Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Bibliography
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 503-512
-
- Chapter
- Export citation
5 - Effective resistance matrix
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 175-192
-
- Chapter
- Export citation
Part III - Polynomials
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 399-400
-
- Chapter
- Export citation
10 - Eigensystem of a matrix
- from Part II - Eigensystem
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 345-398
-
- Chapter
- Export citation
On the zeroes of hypergraph independence polynomials
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 21 September 2023, pp. 65-84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the locations of complex zeroes of independence polynomials of bounded-degree hypergraphs. For graphs, this is a long-studied subject with applications to statistical physics, algorithms, and combinatorics. Results on zero-free regions for bounded-degree graphs include Shearer’s result on the optimal zero-free disc, along with several recent results on other zero-free regions. Much less is known for hypergraphs. We make some steps towards an understanding of zero-free regions for bounded-degree hypergaphs by proving that all hypergraphs of maximum degree
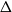 $\Delta$ have a zero-free disc almost as large as the optimal disc for graphs of maximum degree
$\Delta$ have a zero-free disc almost as large as the optimal disc for graphs of maximum degree 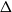 $\Delta$ established by Shearer (of radius
$\Delta$ established by Shearer (of radius 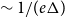 $\sim 1/(e \Delta )$). Up to logarithmic factors in
$\sim 1/(e \Delta )$). Up to logarithmic factors in 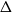 $\Delta$ this is optimal, even for hypergraphs with all edge sizes strictly greater than
$\Delta$ this is optimal, even for hypergraphs with all edge sizes strictly greater than 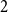 $2$. We conjecture that for
$2$. We conjecture that for 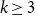 $k\ge 3$,
$k\ge 3$, 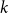 $k$-uniform linear hypergraphs have a much larger zero-free disc of radius
$k$-uniform linear hypergraphs have a much larger zero-free disc of radius 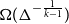 $\Omega (\Delta ^{- \frac{1}{k-1}} )$. We establish this in the case of linear hypertrees.
$\Omega (\Delta ^{- \frac{1}{k-1}} )$. We establish this in the case of linear hypertrees.
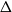
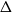
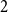
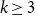
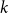
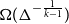
Preface to the first edition
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp xiii-xv
-
- Chapter
- Export citation
3 - Eigenvalues of the adjacency matrix
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 51-110
-
- Chapter
- Export citation
6 - Spectra of special types of graphs
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 193-246
-
- Chapter
- Export citation
Preface to the second edition
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp xi-xii
-
- Chapter
- Export citation
12 - Orthogonal polynomials
- from Part III - Polynomials
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 467-502
-
- Chapter
- Export citation
4 - Eigenvalues of the Laplacian Q
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 111-174
-
- Chapter
- Export citation
2 - Algebraic graph theory
- from Part I - Spectra of graphs
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp 15-50
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp xvi-xvi
-
- Chapter
- Export citation
Contents
-
- Book:
- Graph Spectra for Complex Networks
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023, pp vii-x
-
- Chapter
- Export citation
Height function localisation on trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 18 September 2023, pp. 50-64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Introduction to Probability for Computing
-
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023
-
- Textbook
- Export citation
On the size of maximal intersecting families
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 08 September 2023, pp. 32-49
-
- Article
- Export citation
-
We show that an
 $n$-uniform maximal intersecting family has size at most
$n$-uniform maximal intersecting family has size at most 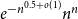 $e^{-n^{0.5+o(1)}}n^n$. This improves a recent bound by Frankl ((2019) Comb. Probab. Comput. 28(5) 733–739.). The Spread Lemma of Alweiss et al. ((2020) Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing.) plays an important role in the proof.
$e^{-n^{0.5+o(1)}}n^n$. This improves a recent bound by Frankl ((2019) Comb. Probab. Comput. 28(5) 733–739.). The Spread Lemma of Alweiss et al. ((2020) Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing.) plays an important role in the proof.


Graph Spectra for Complex Networks
-
- Published online:
- 07 September 2023
- Print publication:
- 21 September 2023
Forcing generalised quasirandom graphs efficiently
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 05 September 2023, pp. 16-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study generalised quasirandom graphs whose vertex set consists of
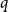 $q$ parts (of not necessarily the same sizes) with edges within each part and between each pair of parts distributed quasirandomly; such graphs correspond to the stochastic block model studied in statistics and network science. Lovász and Sós showed that the structure of such graphs is forced by homomorphism densities of graphs with at most
$q$ parts (of not necessarily the same sizes) with edges within each part and between each pair of parts distributed quasirandomly; such graphs correspond to the stochastic block model studied in statistics and network science. Lovász and Sós showed that the structure of such graphs is forced by homomorphism densities of graphs with at most 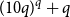 $(10q)^q+q$ vertices; subsequently, Lovász refined the argument to show that graphs with
$(10q)^q+q$ vertices; subsequently, Lovász refined the argument to show that graphs with 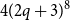 $4(2q+3)^8$ vertices suffice. Our results imply that the structure of generalised quasirandom graphs with
$4(2q+3)^8$ vertices suffice. Our results imply that the structure of generalised quasirandom graphs with 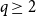 $q\ge 2$ parts is forced by homomorphism densities of graphs with at most
$q\ge 2$ parts is forced by homomorphism densities of graphs with at most 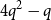 $4q^2-q$ vertices, and, if vertices in distinct parts have distinct degrees, then
$4q^2-q$ vertices, and, if vertices in distinct parts have distinct degrees, then 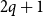 $2q+1$ vertices suffice. The latter improves the bound of
$2q+1$ vertices suffice. The latter improves the bound of 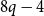 $8q-4$ due to Spencer.
$8q-4$ due to Spencer.
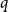
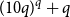
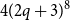
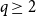
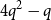
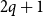
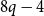
Frontmatter
-
- Book:
- Graph Theory and Additive Combinatorics
- Published online:
- 10 August 2023
- Print publication:
- 31 August 2023, pp i-iv
-
- Chapter
- Export citation
