Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Mastermind with a linear number of queries
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 143-156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Since the 1960s Mastermind has been studied for the combinatorial and information-theoretical interest the game has to offer. Many results have been discovered starting with Erdős and Rényi determining the optimal number of queries needed for two colours. For
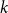 $k$ colours and
$k$ colours and  $n$ positions, Chvátal found asymptotically optimal bounds when
$n$ positions, Chvátal found asymptotically optimal bounds when 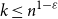 $k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for
$k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for 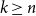 $k\geq n$ colours, the central open question is to resolve the gap between
$k\geq n$ colours, the central open question is to resolve the gap between 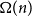 $\Omega (n)$ and
$\Omega (n)$ and 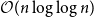 $\mathcal{O}(n\log \log n)$ for
$\mathcal{O}(n\log \log n)$ for 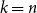 $k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving
$k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving 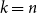 $k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters
$k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters 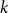 $k$ and
$k$ and  $n$.
$n$.
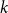

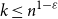
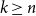
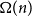
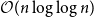
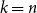
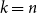
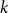

On the choosability of
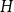 $H$-minor-free graphs
$H$-minor-free graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 03 November 2023, pp. 129-142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a graph
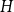 $H$, let us denote by
$H$, let us denote by 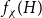 $f_\chi (H)$ and
$f_\chi (H)$ and 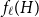 $f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of
$f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of 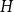 $H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that
$H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that 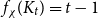 $f_\chi (K_t)=t-1$ for every
$f_\chi (K_t)=t-1$ for every 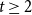 $t \ge 2$. A closely related problem that has received significant attention in the past concerns
$t \ge 2$. A closely related problem that has received significant attention in the past concerns 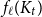 $f_\ell (K_t)$, for which it is known that
$f_\ell (K_t)$, for which it is known that 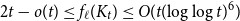 $2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus,
$2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus, 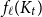 $f_\ell (K_t)$ is bounded away from the conjectured value
$f_\ell (K_t)$ is bounded away from the conjectured value 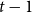 $t-1$ for
$t-1$ for 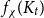 $f_\chi (K_t)$ by at least a constant factor. The so-called
$f_\chi (K_t)$ by at least a constant factor. The so-called 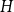 $H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that
$H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that 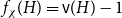 $f_\chi (H)={\textrm{v}}(H)-1$ for a given graph
$f_\chi (H)={\textrm{v}}(H)-1$ for a given graph 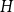 $H$ (which would be implied by Hadwiger’s conjecture).
$H$ (which would be implied by Hadwiger’s conjecture).In this paper, we prove several new lower bounds on
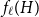 $f_\ell (H)$, thus exploring the limits of a list colouring extension of
$f_\ell (H)$, thus exploring the limits of a list colouring extension of 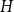 $H$-Hadwiger’s conjecture. Our main results are:
$H$-Hadwiger’s conjecture. Our main results are:For every
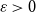 $\varepsilon \gt 0$ and all sufficiently large graphs
$\varepsilon \gt 0$ and all sufficiently large graphs 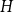 $H$ we have
$H$ we have 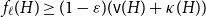 $f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where
$f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where 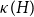 $\kappa (H)$ denotes the vertex-connectivity of
$\kappa (H)$ denotes the vertex-connectivity of 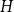 $H$.
$H$.For every
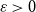 $\varepsilon \gt 0$ there exists
$\varepsilon \gt 0$ there exists 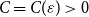 $C=C(\varepsilon )\gt 0$ such that asymptotically almost every
$C=C(\varepsilon )\gt 0$ such that asymptotically almost every  $n$-vertex graph
$n$-vertex graph 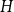 $H$ with
$H$ with 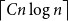 $\left \lceil C n\log n\right \rceil$ edges satisfies
$\left \lceil C n\log n\right \rceil$ edges satisfies 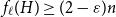 $f_\ell (H)\ge (2-\varepsilon )n$.
$f_\ell (H)\ge (2-\varepsilon )n$.
The first result generalizes recent results on complete and complete bipartite graphs and shows that the list chromatic number of
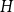 $H$-minor-free graphs is separated from the desired value of
$H$-minor-free graphs is separated from the desired value of 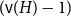 $({\textrm{v}}(H)-1)$ by a constant factor for all large graphs
$({\textrm{v}}(H)-1)$ by a constant factor for all large graphs 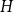 $H$ of linear connectivity. The second result tells us that for almost all graphs
$H$ of linear connectivity. The second result tells us that for almost all graphs 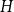 $H$ with superlogarithmic average degree
$H$ with superlogarithmic average degree 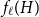 $f_\ell (H)$ is separated from
$f_\ell (H)$ is separated from 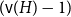 $({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to
$({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to 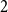 $2$. Conceptually these results indicate that the graphs
$2$. Conceptually these results indicate that the graphs 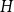 $H$ for which
$H$ for which 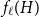 $f_\ell (H)$ is close to the conjectured value
$f_\ell (H)$ is close to the conjectured value 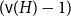 $({\textrm{v}}(H)-1)$ for
$({\textrm{v}}(H)-1)$ for 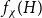 $f_\chi (H)$ are typically rather sparse.
$f_\chi (H)$ are typically rather sparse.
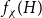
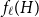
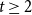
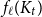
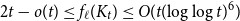
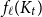
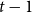
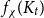
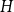
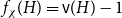
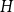
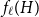
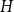
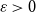
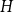
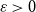
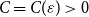

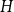
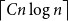
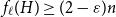
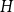
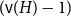
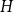
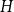
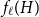
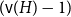
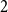
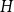
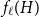
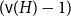
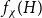
Spanning subdivisions in Dirac graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 20 October 2023, pp. 121-128
-
- Article
- Export citation
-
We show that for every
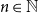 $n\in \mathbb N$ and
$n\in \mathbb N$ and 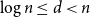 $\log n\le d\lt n$, if a graph
$\log n\le d\lt n$, if a graph 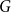 $G$ has
$G$ has 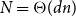 $N=\Theta (dn)$ vertices and minimum degree
$N=\Theta (dn)$ vertices and minimum degree 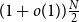 $(1+o(1))\frac{N}{2}$, then it contains a spanning subdivision of every
$(1+o(1))\frac{N}{2}$, then it contains a spanning subdivision of every  $n$-vertex
$n$-vertex 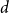 $d$-regular graph.
$d$-regular graph.
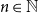
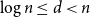
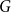
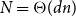
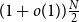

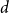
Many Hamiltonian subsets in large graphs with given density
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 110-120
-
- Article
- Export citation
-
A set of vertices in a graph is a Hamiltonian subset if it induces a subgraph containing a Hamiltonian cycle. Kim, Liu, Sharifzadeh, and Staden proved that for large
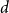 $d$, among all graphs with minimum degree
$d$, among all graphs with minimum degree 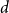 $d$,
$d$, 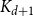 $K_{d+1}$ minimises the number of Hamiltonian subsets. We prove a near optimal lower bound that takes also the order and the structure of a graph into account. For many natural graph classes, it provides a much better bound than the extremal one (
$K_{d+1}$ minimises the number of Hamiltonian subsets. We prove a near optimal lower bound that takes also the order and the structure of a graph into account. For many natural graph classes, it provides a much better bound than the extremal one (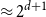 $\approx 2^{d+1}$). Among others, our bound implies that an
$\approx 2^{d+1}$). Among others, our bound implies that an  $n$-vertex
$n$-vertex 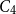 $C_4$-free graph with minimum degree
$C_4$-free graph with minimum degree 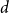 $d$ contains at least
$d$ contains at least 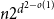 $n2^{d^{2-o(1)}}$ Hamiltonian subsets.
$n2^{d^{2-o(1)}}$ Hamiltonian subsets.
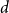
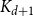
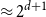

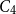
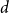
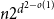
Intersecting families without unique shadow
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 02 October 2023, pp. 91-109
-
- Article
- Export citation
-
Let
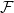 $\mathcal{F}$ be an intersecting family. A
$\mathcal{F}$ be an intersecting family. A 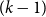 $(k-1)$-set
$(k-1)$-set 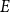 $E$ is called a unique shadow if it is contained in exactly one member of
$E$ is called a unique shadow if it is contained in exactly one member of 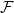 $\mathcal{F}$. Let
$\mathcal{F}$. Let 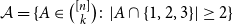 ${\mathcal{A}}=\{A\in \binom{[n]}{k}\colon |A\cap \{1,2,3\}|\geq 2\}$. In the present paper, we show that for
${\mathcal{A}}=\{A\in \binom{[n]}{k}\colon |A\cap \{1,2,3\}|\geq 2\}$. In the present paper, we show that for 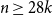 $n\geq 28k$,
$n\geq 28k$, 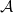 $\mathcal{A}$ is the unique family attaining the maximum size among all intersecting families without unique shadow. Several other results of a similar flavour are established as well.
$\mathcal{A}$ is the unique family attaining the maximum size among all intersecting families without unique shadow. Several other results of a similar flavour are established as well.
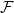
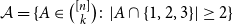
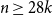
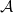
3 - Common Discrete Random Variables
- from Part II - Discrete Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 44-57
-
- Chapter
- Export citation
15 - Estimators for Mean and Variance
- from Part V - Statistical Inference
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 255-264
-
- Chapter
- Export citation
-
Summary
The general setting in statistics is that we observe some data and then try to infer some property of the underlying distribution behind this data. The underlying distribution behind the data is unknown and represented by random variable (r.v.)
. This chapter will briefly introduce the general concept of estimators, focusing on estimators for the mean and variance.
References
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 539-543
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp iv-iv
-
- Chapter
- Export citation
12 - The Poisson Process
- from Part IV - Computer Systems Modeling and Simulation
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 210-228
-
- Chapter
- Export citation
24 - Discrete-Time Markov Chains: Finite-State
- from Part VIII - Discrete-Time Markov Chains
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 420-437
-
- Chapter
- Export citation
20 - Hashing Algorithms
- from Part VI - Tail Bounds and Applications
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 346-362
-
- Chapter
- Export citation
Part VII - Randomized Algorithms
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 363-418
-
- Chapter
- Export citation
8 - Continuous Random Variables: Joint Distributions
- from Part III - Continuous Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 153-169
-
- Chapter
- Export citation
Part VIII - Discrete-Time Markov Chains
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 419-538
-
- Chapter
- Export citation
10 - Heavy Tails: The Distributions of Computing
- from Part III - Continuous Random Variables
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 181-197
-
- Chapter
- Export citation
Preface
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp xv-xxi
-
- Chapter
- Export citation
Dedication
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp v-vi
-
- Chapter
- Export citation
Contents
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp vii-xiv
-
- Chapter
- Export citation
21 - Las Vegas Randomized Algorithms
- from Part VII - Randomized Algorithms
-
- Book:
- Introduction to Probability for Computing
- Published online:
- 12 September 2023
- Print publication:
- 28 September 2023, pp 364-382
-
- Chapter
- Export citation
