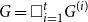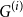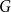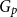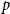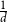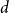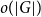Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
1 - Introduction
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 1-20
-
- Chapter
-
- You have access
- Export citation
Contents
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp vii-xii
-
- Chapter
- Export citation
2 - Bell’s Impossibility Theorem(s)
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 10-39
-
- Chapter
- Export citation
Dedication
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp v-vi
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp xiv-xiv
-
- Chapter
- Export citation
4 - Arrow’s (and Friends’) Impossibility Theorems
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 78-113
-
- Chapter
- Export citation
7 - Turing Undecidability and Incompleteness
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 149-173
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 240-245
-
- Chapter
- Export citation
Appendix A - Useful Combinatorial Formulas
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 397-397
-
- Chapter
- Export citation
6 - Branching Processes
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 327-396
-
- Chapter
- Export citation
Appendix - Computer Programs Are Text
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 234-239
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp i-iv
-
- Chapter
- Export citation
6 - A Gödel-ish Impossibility and Incompleteness Theorem
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 130-148
-
- Chapter
- Export citation
Preface
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp xiii-xiii
-
- Chapter
- Export citation
5 - Clustering and Impossibility
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 114-129
-
- Chapter
- Export citation
1 - Yes You Can Prove a Negative!
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 1-9
-
- Chapter
-
- You have access
- Export citation
Dedication
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp v-vi
-
- Chapter
- Export citation
3 - Martingales and Potentials
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 95-181
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp i-iv
-
- Chapter
- Export citation
Percolation on irregular high-dimensional product graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 20 December 2023, pp. 377-403
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider bond percolation on high-dimensional product graphs
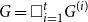 $G=\square _{i=1}^tG^{(i)}$, where
$G=\square _{i=1}^tG^{(i)}$, where  $\square$ denotes the Cartesian product. We call the
$\square$ denotes the Cartesian product. We call the 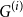 $G^{(i)}$ the base graphs and the product graph
$G^{(i)}$ the base graphs and the product graph 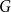 $G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph
$G$ the host graph. Very recently, Lichev (J. Graph Theory, 99(4):651–670, 2022) showed that, under a mild requirement on the isoperimetric properties of the base graphs, the component structure of the percolated graph 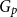 $G_p$ undergoes a phase transition when
$G_p$ undergoes a phase transition when 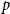 $p$ is around
$p$ is around 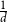 $\frac{1}{d}$, where
$\frac{1}{d}$, where 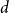 $d$ is the average degree of the host graph.
$d$ is the average degree of the host graph.In the supercritical regime, we strengthen Lichev’s result by showing that the giant component is in fact unique, with all other components of order
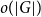 $o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).
$o(|G|)$, and determining the sharp asymptotic order of the giant. Furthermore, we answer two questions posed by Lichev (J. Graph Theory, 99(4):651–670, 2022): firstly, we provide a construction showing that the requirement of bounded degree is necessary for the likely emergence of a linear order component; secondly, we show that the isoperimetric requirement on the base graphs can be, in fact, super-exponentially small in the dimension. Finally, in the subcritical regime, we give an example showing that in the case of irregular high-dimensional product graphs, there can be a polynomially large component with high probability, very much unlike the quantitative behaviour seen in the Erdős-Rényi random graph and in the percolated hypercube, and in fact in any regular high-dimensional product graphs, as shown by the authors in a companion paper (Percolation on high-dimensional product graphs. arXiv:2209.03722, 2022).