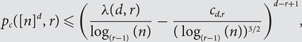Refine search
Actions for selected content:
7009 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Frontmatter
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp i-iv
-
- Chapter
- Export citation
3 - Proofs
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 89-172
-
- Chapter
- Export citation
Preface
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp ix-xii
-
- Chapter
- Export citation
5 - Functions
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 229-272
-
- Chapter
- Export citation
Contents
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp vii-viii
-
- Chapter
- Export citation
Dedication
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp v-vi
-
- Chapter
- Export citation
Suggestions for Further Reading
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 451-452
-
- Chapter
- Export citation
2 - Quantificational Logic
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 58-88
-
- Chapter
- Export citation
7 - Number Theory
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 324-371
-
- Chapter
- Export citation
4 - Relations
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 173-228
-
- Chapter
- Export citation
1 - Sentential Logic
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 8-57
-
- Chapter
- Export citation
Appendix - Solutions to Selected Exercises
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 397-450
-
- Chapter
- Export citation
On the Size-Ramsey Number of Cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 17 July 2019, pp. 871-880
-
- Article
- Export citation
-
For given graphs G1,…, Gk, the size-Ramsey number
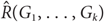 $\hat R({G_1}, \ldots ,{G_k})$ is the smallest integer m for which there exists a graph H on m edges such that in every k-edge colouring of H with colours 1,…,k, H contains a monochromatic copy of Gi of colour i for some 1 ≤ i ≤ k. We denote
$\hat R({G_1}, \ldots ,{G_k})$ is the smallest integer m for which there exists a graph H on m edges such that in every k-edge colouring of H with colours 1,…,k, H contains a monochromatic copy of Gi of colour i for some 1 ≤ i ≤ k. We denote 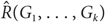 $\hat R({G_1}, \ldots ,{G_k})$ by
$\hat R({G_1}, \ldots ,{G_k})$ by 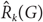 ${\hat R_k}(G)$ when G1 = ⋯ = Gk = G.
${\hat R_k}(G)$ when G1 = ⋯ = Gk = G.Haxell, Kohayakawa and Łuczak showed that the size-Ramsey number of a cycle Cn is linear in n,
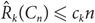 ${\hat R_k}({C_n}) \le {c_k}n$ for some constant ck. Their proof, however, is based on Szemerédi’s regularity lemma so no specific constant ck is known.
${\hat R_k}({C_n}) \le {c_k}n$ for some constant ck. Their proof, however, is based on Szemerédi’s regularity lemma so no specific constant ck is known.In this paper, we give various upper bounds for the size-Ramsey numbers of cycles. We provide an alternative proof of
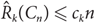 ${\hat R_k}({C_n}) \le {c_k}n$, avoiding use of the regularity lemma, where ck is exponential and doubly exponential in k, when n is even and odd, respectively. In particular, we show that for sufficiently large n we have
${\hat R_k}({C_n}) \le {c_k}n$, avoiding use of the regularity lemma, where ck is exponential and doubly exponential in k, when n is even and odd, respectively. In particular, we show that for sufficiently large n we have 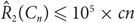 ${\hat R_2}({C_n}) \le {10^5} \times cn$, where c = 6.5 if n is even and c = 1989 otherwise.
${\hat R_2}({C_n}) \le {10^5} \times cn$, where c = 6.5 if n is even and c = 1989 otherwise.
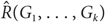
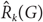
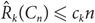
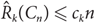
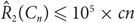
Codegree Conditions for Tiling Complete k-Partite k-Graphs and Loose Cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 09 July 2019, pp. 840-870
-
- Article
- Export citation
Positive association of the oriented percolation cluster in randomly oriented graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 08 July 2019, pp. 811-815
-
- Article
- Export citation

How to Prove It
- A Structured Approach
-
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019
-
- Textbook
- Export citation
A natural barrier in random greedy hypergraph matching
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 27 June 2019, pp. 816-825
-
- Article
- Export citation
-
Let r ⩾ 2 be a fixed constant and let
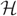 $ {\cal H} $ be an r-uniform, D-regular hypergraph on N vertices. Assume further that D → ∞ as N → ∞ and that degrees of pairs of vertices in
$ {\cal H} $ be an r-uniform, D-regular hypergraph on N vertices. Assume further that D → ∞ as N → ∞ and that degrees of pairs of vertices in 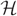 $ {\cal H} $ are at most L where L = D/( log N)ω(1). We consider the random greedy algorithm for forming a matching in
$ {\cal H} $ are at most L where L = D/( log N)ω(1). We consider the random greedy algorithm for forming a matching in 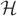 $ {\cal H} $. We choose a matching at random by iteratively choosing edges uniformly at random to be in the matching and deleting all edges that share at least one vertex with a chosen edge before moving on to the next choice. This process terminates when there are no edges remaining in the graph. We show that with high probability the proportion of vertices of
$ {\cal H} $. We choose a matching at random by iteratively choosing edges uniformly at random to be in the matching and deleting all edges that share at least one vertex with a chosen edge before moving on to the next choice. This process terminates when there are no edges remaining in the graph. We show that with high probability the proportion of vertices of 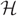 $ {\cal H} $ that are not saturated by the final matching is at most (L/D)(1/(2(r−1)))+o(1). This point is a natural barrier in the analysis of the random greedy hypergraph matching process.
$ {\cal H} $ that are not saturated by the final matching is at most (L/D)(1/(2(r−1)))+o(1). This point is a natural barrier in the analysis of the random greedy hypergraph matching process.
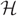
On the union of intersecting families
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 27 June 2019, pp. 826-839
-
- Article
- Export citation
-
A family of sets is said to be intersecting if any two sets in the family have non-empty intersection. In 1973, Erdős raised the problem of determining the maximum possible size of a union of r different intersecting families of k-element subsets of an n-element set, for each triple of integers (n, k, r). We make progress on this problem, proving that for any fixed integer r ⩾ 2 and for any
 $$k \le ({1 \over 2} - o(1))n$$, if X is an n-element set, and
$$k \le ({1 \over 2} - o(1))n$$, if X is an n-element set, and 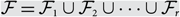 $${\cal F} = {\cal F}_1 \cup {\cal F}_2 \cup \cdots \cup {\cal F}_r $$, where each
$${\cal F} = {\cal F}_1 \cup {\cal F}_2 \cup \cdots \cup {\cal F}_r $$, where each 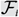 $$ {\cal F}_i $$ is an intersecting family of k-element subsets of X, then
$$ {\cal F}_i $$ is an intersecting family of k-element subsets of X, then  $$|{\cal F}| \le \left( {\matrix{n \cr k \cr } } \right) - \left( {\matrix{{n - r} \cr k \cr } } \right)$$, with equality only if
$$|{\cal F}| \le \left( {\matrix{n \cr k \cr } } \right) - \left( {\matrix{{n - r} \cr k \cr } } \right)$$, with equality only if 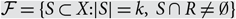 $${\cal F} = \{ S \subset X:|S| = k,\;S \cap R \ne \emptyset \} $$ for some R ⊂ X with |R| = r. This is best possible up to the size of the o(1) term, and improves a 1987 result of Frankl and Füredi, who obtained the same conclusion under the stronger hypothesis
$${\cal F} = \{ S \subset X:|S| = k,\;S \cap R \ne \emptyset \} $$ for some R ⊂ X with |R| = r. This is best possible up to the size of the o(1) term, and improves a 1987 result of Frankl and Füredi, who obtained the same conclusion under the stronger hypothesis 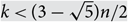 $$k < (3 - \sqrt 5 )n/2$$, in the case r = 2. Our proof utilizes an isoperimetric, influence-based method recently developed by Keller and the authors.
$$k < (3 - \sqrt 5 )n/2$$, in the case r = 2. Our proof utilizes an isoperimetric, influence-based method recently developed by Keller and the authors.

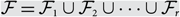
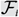

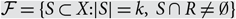
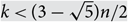
On Erdős–Ko–Rado for random hypergraphs I
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 25 June 2019, pp. 881-916
-
- Article
- Export citation
-
A family of sets is intersecting if no two of its members are disjoint, and has the Erdős–Ko–Rado property (or is EKR) if each of its largest intersecting subfamilies has non-empty intersection.
Denote by
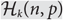 ${{\cal H}_k}(n,p)$ the random family in which each k-subset of {1, …, n} is present with probability p, independent of other choices. A question first studied by Balogh, Bohman and Mubayi asks:
${{\cal H}_k}(n,p)$ the random family in which each k-subset of {1, …, n} is present with probability p, independent of other choices. A question first studied by Balogh, Bohman and Mubayi asks: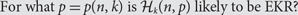 \begin{equation} {\rm{For what }}p = p(n,k){\rm{is}}{{\cal H}_k}(n,p){\rm{likely to be EKR}}? \end{equation}
\begin{equation} {\rm{For what }}p = p(n,k){\rm{is}}{{\cal H}_k}(n,p){\rm{likely to be EKR}}? \end{equation}Here, for fixed c < 1/4, and
 $k \lt \sqrt {cn\log n} $ we give a precise answer to this question, characterizing those sequences p = p(n, k) for which
$k \lt \sqrt {cn\log n} $ we give a precise answer to this question, characterizing those sequences p = p(n, k) for which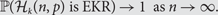 \begin{equation} {\mathbb{P}}({{\cal H}_k}(n,p){\rm{is EKR}}{\kern 1pt} ) \to 1{\rm{as }}n \to \infty . \end{equation}
\begin{equation} {\mathbb{P}}({{\cal H}_k}(n,p){\rm{is EKR}}{\kern 1pt} ) \to 1{\rm{as }}n \to \infty . \end{equation}
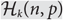
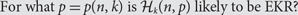

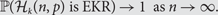
An Improved Upper Bound for Bootstrap Percolation in All Dimensions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 17 June 2019, pp. 936-960
-
- Article
- Export citation
-
In r-neighbour bootstrap percolation on the vertex set of a graph G, a set A of initially infected vertices spreads by infecting, at each time step, all uninfected vertices with at least r previously infected neighbours. When the elements of A are chosen independently with some probability p, it is natural to study the critical probability pc(G, r) at which it becomes likely that all of V(G) will eventually become infected. Improving a result of Balogh, Bollobás and Morris, we give a bound on the second term in the expansion of the critical probability when G = [n]d and d ⩾ r ⩾ 2. We show that for all d ⩾ r ⩾ 2 there exists a constant cd,r > 0 such that if n is sufficiently large, then
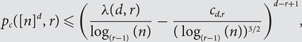 $$p_c (\left[ n \right]^d ,{\rm{ }}r){\rm{\le }}\left( {\frac{{\lambda (d,r)}}{{\log _{(r - 1)} (n)}} - \frac{{c_{d,r} }}{{(\log _{(r - 1)} (n))^{3/2} }}} \right)^{d - r + 1} ,$$
$$p_c (\left[ n \right]^d ,{\rm{ }}r){\rm{\le }}\left( {\frac{{\lambda (d,r)}}{{\log _{(r - 1)} (n)}} - \frac{{c_{d,r} }}{{(\log _{(r - 1)} (n))^{3/2} }}} \right)^{d - r + 1} ,$$where λ(d, r) is an exact constant and log(k) (n) denotes the k-times iterated natural logarithm of n.