Refine search
Actions for selected content:
7009 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Surjectivity of near-square random matrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 06 November 2019, pp. 267-292
-
- Article
- Export citation
The string of diamonds is nearly tight for rumour spreading
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 04 November 2019, pp. 190-199
-
- Article
- Export citation
-
For a rumour spreading protocol, the spread time is defined as the first time everyone learns the rumour. We compare the synchronous push&pull rumour spreading protocol with its asynchronous variant, and show that for any n-vertex graph and any starting vertex, the ratio between their expected spread times is bounded by
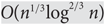 $O({n^{1/3}}{\log ^{2/3}}n)$. This improves the
$O({n^{1/3}}{\log ^{2/3}}n)$. This improves the 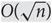 $O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then
$O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then 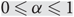 $0 \le \alpha \le 1$ and
$0 \le \alpha \le 1$ and  $\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
$\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
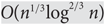
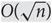
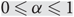

Unlabelled Gibbs partitions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 04 November 2019, pp. 293-309
-
- Article
- Export citation
On the Brownian separable permuton
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 24 October 2019, pp. 241-266
-
- Article
- Export citation
On the number of symbols that forces a transversal
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 21 October 2019, pp. 234-240
-
- Article
- Export citation
FKN theorem for the multislice, with applications
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 18 October 2019, pp. 200-212
-
- Article
- Export citation
On Ramsey numbers of hedgehogs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 18 October 2019, pp. 101-112
-
- Article
- Export citation
-
The hedgehog Ht is a 3-uniform hypergraph on vertices
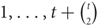 $1, \ldots ,t + \left({\matrix{t \cr 2}}\right)$ such that, for any pair (i, j) with 1 ≤ i < j ≤ t, there exists a unique vertex k > t such that {i, j, k} is an edge. Conlon, Fox and Rödl proved that the two-colour Ramsey number of the hedgehog grows polynomially in the number of its vertices, while the four-colour Ramsey number grows exponentially in the square root of the number of vertices. They asked whether the two-colour Ramsey number of the hedgehog Ht is nearly linear in the number of its vertices. We answer this question affirmatively, proving that r(Ht) = O(t2 ln t).
$1, \ldots ,t + \left({\matrix{t \cr 2}}\right)$ such that, for any pair (i, j) with 1 ≤ i < j ≤ t, there exists a unique vertex k > t such that {i, j, k} is an edge. Conlon, Fox and Rödl proved that the two-colour Ramsey number of the hedgehog grows polynomially in the number of its vertices, while the four-colour Ramsey number grows exponentially in the square root of the number of vertices. They asked whether the two-colour Ramsey number of the hedgehog Ht is nearly linear in the number of its vertices. We answer this question affirmatively, proving that r(Ht) = O(t2 ln t).
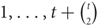
The Infinite limit of random permutations avoiding patterns of length three
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 14 October 2019, pp. 137-152
-
- Article
- Export citation
-
For
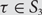 $$\tau \in {S_3}$$, let
$$\tau \in {S_3}$$, let 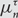 $$\mu _n^\tau $$ denote the uniformly random probability measure on the set of
$$\mu _n^\tau $$ denote the uniformly random probability measure on the set of  $$\tau $$-avoiding permutations in
$$\tau $$-avoiding permutations in 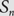 $${S_n}$$. Let
$${S_n}$$. Let 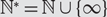 $${\mathbb {N}^*} = {\mathbb {N}} \cup \{ \infty \} $$ with an appropriate metric and denote by
$${\mathbb {N}^*} = {\mathbb {N}} \cup \{ \infty \} $$ with an appropriate metric and denote by 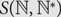 $$S({\mathbb{N}},{\mathbb{N}^*})$$ the compact metric space consisting of functions
$$S({\mathbb{N}},{\mathbb{N}^*})$$ the compact metric space consisting of functions 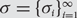 $$\sigma {\rm{= }}\{ {\sigma _i}\} _{i = 1}^\infty {\rm{}}$$ from
$$\sigma {\rm{= }}\{ {\sigma _i}\} _{i = 1}^\infty {\rm{}}$$ from 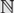 $$\mathbb {N}$$ to
$$\mathbb {N}$$ to 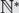 $${\mathbb {N}^ * }$$ which are injections when restricted to
$${\mathbb {N}^ * }$$ which are injections when restricted to 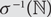 $${\sigma ^{ - 1}}(\mathbb {N})$$; that is, if
$${\sigma ^{ - 1}}(\mathbb {N})$$; that is, if 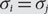 $${\sigma _i}{\rm{= }}{\sigma _j}$$,
$${\sigma _i}{\rm{= }}{\sigma _j}$$, 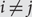 $$i \ne j$$, then
$$i \ne j$$, then  $${\sigma _i} = \infty $$. Extending permutations
$${\sigma _i} = \infty $$. Extending permutations 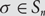 $$\sigma \in {S_n}$$ by defining
$$\sigma \in {S_n}$$ by defining  $${\sigma _j} = j$$, for
$${\sigma _j} = j$$, for 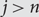 $$j \gt n$$, we have
$$j \gt n$$, we have 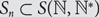 $${S_n} \subset S({\mathbb{N}},{{\mathbb{N}}^*})$$. For each
$${S_n} \subset S({\mathbb{N}},{{\mathbb{N}}^*})$$. For each 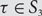 $$\tau \in {S_3}$$, we study the limiting behaviour of the measures
$$\tau \in {S_3}$$, we study the limiting behaviour of the measures 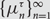 $$\{ \mu _n^\tau \} _{n = 1}^\infty $$ on
$$\{ \mu _n^\tau \} _{n = 1}^\infty $$ on 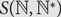 $$S({\mathbb{N}},{\mathbb{N}^*})$$. We obtain partial results for the permutation
$$S({\mathbb{N}},{\mathbb{N}^*})$$. We obtain partial results for the permutation 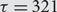 $$\tau= 321$$ and complete results for the other five permutations
$$\tau= 321$$ and complete results for the other five permutations 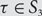 $$\tau \in {S_3}$$.
$$\tau \in {S_3}$$.
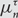

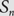
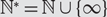
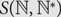
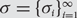
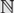
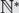
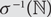
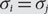
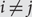

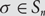

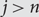
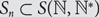
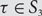
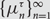
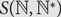
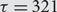
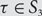
On sets of points with few odd secants
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 10 October 2019, pp. 31-43
-
- Article
- Export citation
Minimizing the number of 5-cycles in graphs with given edge-density
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 09 October 2019, pp. 44-67
-
- Article
- Export citation
-
Motivated by the work of Razborov about the minimal density of triangles in graphs we study the minimal density of the 5-cycle C5. We show that every graph of order n and size
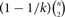 $ (1 - 1/k) \left( {\matrix{n \cr 2 }} \right) $, where k ≥ 3 is an integer, contains at leastcopies of C5. This bound is optimal, since a matching upper bound is given by the balanced complete k-partite graph. The proof is based on the flag algebras framework. We also provide a stability result. An SDP solver is not necessary to verify our proofs.
$ (1 - 1/k) \left( {\matrix{n \cr 2 }} \right) $, where k ≥ 3 is an integer, contains at leastcopies of C5. This bound is optimal, since a matching upper bound is given by the balanced complete k-partite graph. The proof is based on the flag algebras framework. We also provide a stability result. An SDP solver is not necessary to verify our proofs.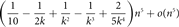 $$({1 \over {10}} - {1 \over {2k}} + {1 \over {{k^2}}} - {1 \over {{k^3}}} + {2 \over {5{k^4}}}){n^5} + o({n^5})$$
$$({1 \over {10}} - {1 \over {2k}} + {1 \over {{k^2}}} - {1 \over {{k^3}}} + {2 \over {5{k^4}}}){n^5} + o({n^5})$$
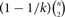
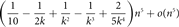
Extensions of the Erdős–Gallai theorem and Luo’s theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 08 October 2019, pp. 128-136
-
- Article
- Export citation
-
The famous Erdős–Gallai theorem on the Turán number of paths states that every graph with n vertices and m edges contains a path with at least (2m)/n edges. In this note, we first establish a simple but novel extension of the Erdős–Gallai theorem by proving that every graph G contains a path with at least
edges, where Nj(G) denotes the number of j-cliques in G for 1≤ j ≤ ω(G). We also construct a family of graphs which shows our extension improves the estimate given by the Erdős–Gallai theorem. Among applications, we show, for example, that the main results of [20], which are on the maximum possible number of s-cliques in an n-vertex graph without a path with ℓ vertices (and without cycles of length at least c), can be easily deduced from this extension. Indeed, to prove these results, Luo [20] generalized a classical theorem of Kopylov and established a tight upper bound on the number of s-cliques in an n-vertex 2-connected graph with circumference less than c. We prove a similar result for an n-vertex 2-connected graph with circumference less than c and large minimum degree. We conclude this paper with an application of our results to a problem from spectral extremal graph theory on consecutive lengths of cycles in graphs.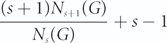 $${{(s + 1){N_{s + 1}}(G)} \over {{N_s}(G)}} + s - 1$$
$${{(s + 1){N_{s + 1}}(G)} \over {{N_s}(G)}} + s - 1$$
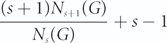
Long Monotone Trails in Random Edge-Labellings of Random Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 08 October 2019, pp. 22-30
-
- Article
- Export citation
The Induced Removal Lemma in Sparse Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 30 September 2019, pp. 153-162
-
- Article
- Export citation
On the Chromatic Number of Matching Kneser Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 12 September 2019, pp. 1-21
-
- Article
- Export citation
Contents
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp v-viii
-
- Chapter
- Export citation
References
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp 294-306
-
- Chapter
- Export citation
Index
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp 310-314
-
- Chapter
- Export citation
9 - Open Questions
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp 291-293
-
- Chapter
- Export citation
Preface
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp ix-x
-
- Chapter
- Export citation
Author Index
-
- Book:
- Network Flow Algorithms
- Published online:
- 21 August 2019
- Print publication:
- 05 September 2019, pp 307-309
-
- Chapter
- Export citation
