Refine search
Actions for selected content:
48287 results in Computer Science
The Maximum Displacement for Linear Probing Hashing
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 24 January 2013, pp. 455-476
-
- Article
- Export citation
A New Bound for the 2/3 Conjecture†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 23 January 2013, pp. 384-393
-
- Article
- Export citation
A goal-directed implementation of query answering for hybrid MKNF knowledge bases
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 18 January 2013, pp. 239-264
-
- Article
- Export citation
-
Ontologies and rules are usually loosely coupled in knowledge representation formalisms. In fact, ontologies use open-world reasoning, while the leading semantics for rules use non-monotonic, closed-world reasoning. One exception is the tightly coupled framework of Minimal Knowledge and Negation as Failure (MKNF), which allows statements about individuals to be jointly derived via entailment from ontology and inferences from rules. Nonetheless, the practical usefulness of MKNF has not always been clear, although recent work has formalized a general resolution-based method for querying MKNF when rules are taken to have the well-founded semantics, and the ontology is modeled by a general oracle. That work leaves open what algorithms should be used to relate the entailments of the ontology and the inferences of rules. In this paper we provide such algorithms, and describe the implementation of a query-driven system, CDF-Rules, for hybrid knowledge bases combining both (non-monotonic) rules under the well-founded semantics and a (monotonic) ontology, represented by the Coherent Description Framework Type-1 (
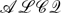 $\mathcal{ALCQ}$ ) theory.
$\mathcal{ALCQ}$ ) theory.
Monadic translation of classical sequent calculus
-
- Journal:
- Mathematical Structures in Computer Science / Volume 23 / Issue 6 / December 2013
- Published online by Cambridge University Press:
- 18 January 2013, pp. 1111-1162
-
- Article
- Export citation
-
We study monadic translations of the call-by-name (cbn) and call-by-value (cbv) fragments of the classical sequent calculus
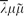 ${\overline{\lambda}\mu\tilde{\mu}}$ due to Curien and Herbelin, and give modular and syntactic proofs of strong normalisation. The target of the translations is a new meta-language for classical logic, named monadic λμ. This language is a monadic reworking of Parigot's λμ-calculus, where the monadic binding is confined to commands, thus integrating the monad with the classical features. Also, its μ-reduction rule is replaced by a rule expressing the interaction between monadic binding and μ-abstraction.
${\overline{\lambda}\mu\tilde{\mu}}$ due to Curien and Herbelin, and give modular and syntactic proofs of strong normalisation. The target of the translations is a new meta-language for classical logic, named monadic λμ. This language is a monadic reworking of Parigot's λμ-calculus, where the monadic binding is confined to commands, thus integrating the monad with the classical features. Also, its μ-reduction rule is replaced by a rule expressing the interaction between monadic binding and μ-abstraction.Our monadic translations produce very tight simulations of the respective fragments of
${\overline{\lambda}\mu\tilde{\mu}}$ within monadic λμ, with reduction steps of ${\overline{\lambda}\mu\tilde{\mu}}$ being translated in a 1–1 fashion, except for β steps, which require two steps. The monad of monadic λμ can be instantiated to the continuations monad so as to ensure strict simulation of monadic λμ within simply typed λ-calculus with β- and η-reduction. Through strict simulation, the strong normalisation of simply typed λ-calculus is inherited by monadic λμ, and then by cbn and cbv ${\overline{\lambda}\mu\tilde{\mu}}$, thus reproving strong normalisation in an elementary syntactical way for these fragments of ${\overline{\lambda}\mu\tilde{\mu}}$, and establishing it for our new calculus. These results extend to second-order logic, with polymorphic λ-calculus as the target, giving new strong normalisation results for classical second-order logic in sequent calculus style.CPS translations of cbn and cbv
${\overline{\lambda}\mu\tilde{\mu}}$ with the strict simulation property are obtained by composing our monadic translations with the continuations-monad instantiation. In an appendix to the paper, we investigate several refinements of the continuations-monad instantiation in order to obtain in a modular way improvements of the CPS translations enjoying extra properties like simulation by cbv β-reduction or reduction of administrative redexes at compile time.
OUTCOME LEVEL ANALYSIS OF BELIEF CONTRACTION
-
- Journal:
- The Review of Symbolic Logic / Volume 6 / Issue 2 / June 2013
- Published online by Cambridge University Press:
- 16 January 2013, pp. 183-204
- Print publication:
- June 2013
-
- Article
- Export citation
A semantic space approach to the computational semantics of noun compounds
-
- Journal:
- Natural Language Engineering / Volume 20 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 15 January 2013, pp. 185-234
-
- Article
- Export citation
AIE volume 27 issue 1 Cover and Back matter
-
- Article
-
- You have access
- Export citation
AIE volume 27 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Status and new features
-
- Article
-
- You have access
- HTML
- Export citation
