Refine search
Actions for selected content:
48202 results in Computer Science
Generalised powerlocales via relation lifting
-
- Journal:
- Mathematical Structures in Computer Science / Volume 23 / Issue 1 / February 2013
- Published online by Cambridge University Press:
- 30 August 2012, pp. 142-199
-
- Article
- Export citation
-
This paper introduces an endofunctor VT on the category of frames that is parametrised by an endofunctor T on the category Set that satisfies certain constraints. This generalises Johnstone's construction of the Vietoris powerlocale in the sense that his construction is obtained by taking for T the finite covariant power set functor. Our construction of the T-powerlocale VT
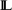
We show how to extend certain natural transformations between set functors to natural transformations between T-powerlocale functors. Finally, we prove that the operation VT preserves some properties of frames, such as regularity, zero-dimensionality and the combination of zero-dimensionality and compactness.
5 - Multiprocessor systems
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 232-308
-
- Chapter
- Export citation
Contents
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp vii-x
-
- Chapter
- Export citation
7 - Coherence, synchronization, and memory consistency
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 342-424
-
- Chapter
- Export citation
8 - Chip multiprocessors
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 425-487
-
- Chapter
- Export citation
4 - Memory hierarchies
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 193-231
-
- Chapter
- Export citation
Index
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 521-542
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 1-35
-
- Chapter
- Export citation
Preface
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp xi-xviii
-
- Chapter
- Export citation
9 - Quantitative evaluations
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 488-520
-
- Chapter
- Export citation
3 - Processor microarchitecture
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 74-192
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp i-vi
-
- Chapter
- Export citation
2 - Impact of technology
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 36-73
-
- Chapter
- Export citation
6 - Interconnection networks
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 309-341
-
- Chapter
- Export citation
ROB volume 30 issue 6 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ROB volume 30 issue 6 Cover and Front matter
-
- Article
-
- You have access
- Export citation
On (Not) Computing the Möbius Function Using Bounded Depth Circuits
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 24 August 2012, pp. 942-951
-
- Article
- Export citation
-
Any function F: {0,. . ., N − 1} → {−1,1} such that F(x) can be computed from the binary digits of x using a bounded depth circuit is orthogonal to the Möbius function μ in the sense that
The proof combines a result of Linial, Mansour and Nisan with techniques of Kátai and Harman, used in their work on finding primes with specified digits.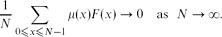 \[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
\[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
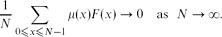
NLE volume 18 issue 4 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 23 August 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
NLE volume 18 issue 4 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 23 August 2012, pp. b1-b2
-
- Article
-
- You have access
- Export citation
