Refine search
Actions for selected content:
48229 results in Computer Science
6 - Interconnection networks
-
- Book:
- Parallel Computer Organization and Design
- Published online:
- 05 November 2012
- Print publication:
- 30 August 2012, pp 309-341
-
- Chapter
- Export citation
ROB volume 30 issue 6 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ROB volume 30 issue 6 Cover and Front matter
-
- Article
-
- You have access
- Export citation
On (Not) Computing the Möbius Function Using Bounded Depth Circuits
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 24 August 2012, pp. 942-951
-
- Article
- Export citation
-
Any function F: {0,. . ., N − 1} → {−1,1} such that F(x) can be computed from the binary digits of x using a bounded depth circuit is orthogonal to the Möbius function μ in the sense that
The proof combines a result of Linial, Mansour and Nisan with techniques of Kátai and Harman, used in their work on finding primes with specified digits.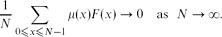 \[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
\[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
NLE volume 18 issue 4 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 23 August 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
NLE volume 18 issue 4 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 23 August 2012, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Cops and Robbers on Geometric Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 16 August 2012, pp. 816-834
-
- Article
- Export citation
-
Cops and robbers is a turn-based pursuit game played on a graph G. One robber is pursued by a set of cops. In each round, these agents move between vertices along the edges of the graph. The cop number c(G) denotes the minimum number of cops required to catch the robber in finite time. We study the cop number of geometric graphs. For points x1, . . ., xn ∈ ℝ2, and r ∈ ℝ+, the vertex set of the geometric graph G(x1, . . ., xn; r) is the graph on these n points, with xi, xj adjacent when ∥xi − xj∥ ≤ r. We prove that c(G) ≤ 9 for any connected geometric graph G in ℝ2 and we give an example of a connected geometric graph with c(G) = 3. We improve on our upper bound for random geometric graphs that are sufficiently dense. Let
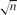
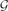
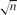
Lazy tree splitting
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 382-438
-
- Article
-
- You have access
- Export citation
JFP volume 22 issue 4-5 Cover and Front matter
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
The impact of higher-order state and control effects on local relational reasoning
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 477-528
-
- Article
-
- You have access
- Export citation
Listening Together, Making Place
-
- Journal:
- Organised Sound / Volume 17 / Issue 3 / December 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 257-265
- Print publication:
- December 2012
-
- Article
- Export citation
Every bit counts: The binary representation of typed data and programs
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 529-573
-
- Article
-
- You have access
- Export citation
A unified treatment of syntax with binders
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 614-704
-
- Article
-
- You have access
- Export citation
Systematic abstraction of abstract machines
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 705-746
-
- Article
-
- You have access
- Export citation
Fortifying macros
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 439-476
-
- Article
-
- You have access
- Export citation
JFP volume 22 issue 4-5 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Editorial: Special issue dedicated to ICFP 2010
-
- Journal:
- Journal of Functional Programming / Volume 22 / Issue 4-5 / September 2012
- Published online by Cambridge University Press:
- 15 August 2012, pp. 379-381
-
- Article
-
- You have access
- Export citation
