Refine search
Actions for selected content:
48287 results in Computer Science
4 - Graphical models
- from 1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 58-76
-
- Chapter
- Export citation
Corrádi and Hajnal's Theorem for Sparse Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 23-55
-
- Article
- Export citation
Plate Section
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp -
-
- Chapter
- Export citation
22 - Latent ability models
- from III - Machine learning
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 479-486
-
- Chapter
- Export citation
A coding theoretic study of MLL proof nets
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 3 / June 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 409-449
-
- Article
- Export citation
Index
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 689-697
-
- Chapter
- Export citation
On Even-Degree Subgraphs of Linear Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 113-127
-
- Article
- Export citation
-
A subgraph of a hypergraph H is even if all its degrees are positive even integers, and b-bounded if it has maximum degree at most b. Let fb(n) denote the maximum number of edges in a linearn-vertex 3-uniform hypergraph which does not contain a b-bounded even subgraph. In this paper, we show that if b ≥ 12, then
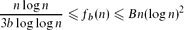 for some absolute constant B, thus establishing fb(n) up to polylogarithmic factors. This leaves open the interesting case b = 2, which is the case of 2-regular subgraphs. We are able to show for some constants c, C > 0 that
for some absolute constant B, thus establishing fb(n) up to polylogarithmic factors. This leaves open the interesting case b = 2, which is the case of 2-regular subgraphs. We are able to show for some constants c, C > 0 that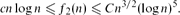 We conjecture that f2(n) = n1 + o(1) as n → ∞.
We conjecture that f2(n) = n1 + o(1) as n → ∞.
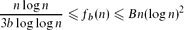
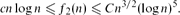
10 - Naive Bayes
- from II - Learning in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 243-255
-
- Chapter
- Export citation
Star Versus Two Stripes Ramsey Numbers and a Conjecture of Schelp
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 179-186
-
- Article
- Export citation
-
R. H. Schelp conjectured that if G is a graph with |V(G)| = R(Pn, Pn) such that δ(G) >
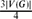 , then in every 2-colouring of the edges of G there is a monochromatic Pn. In other words, the Ramsey number of a path does not change if the graph to be coloured is not complete but has large minimum degree.
, then in every 2-colouring of the edges of G there is a monochromatic Pn. In other words, the Ramsey number of a path does not change if the graph to be coloured is not complete but has large minimum degree.Here we prove Ramsey-type results that imply the conjecture in a weakened form, first replacing the path by a matching, showing that the star-matching–matching Ramsey number satisfying R(Sn, nK2, nK2) = 3n − 1. This extends R(nK2, nK2) = 3n − 1, an old result of Cockayne and Lorimer. Then we extend this further from matchings to connected matchings, and outline how this implies Schelp's conjecture in an asymptotic sense through a standard application of the Regularity Lemma.
It is sad that we are unable to hear Dick Schelp's reaction to our work generated by his conjecture.
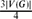 , then in every 2-colouring of the edges of
, then in every 2-colouring of the edges of 19 - Gaussian processes
- from III - Machine learning
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 412-431
-
- Chapter
- Export citation
5 - Efficient inference in trees
- from 1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 77-101
-
- Chapter
- Export citation
The Maximum Number of Triangles in C2k+1-Free Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 187-191
-
- Article
- Export citation
V - Approximate inference
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 585-586
-
- Chapter
- Export citation
BRMLTOOLBOX
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp xxi-xxiv
-
- Chapter
- Export citation
7 - Making decisions
- from 1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 127-162
-
- Chapter
- Export citation
IV - Dynamical models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 487-488
-
- Chapter
- Export citation
6 - The junction tree algorithm
- from 1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 102-126
-
- Chapter
- Export citation
Degree Powers in Graphs: The Erdős–Stone Theorem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 89-105
-
- Article
- Export citation
-
Let 1 ≤ p ≤ r + 1, with r ≥ 2 an integer, and let G be a graph of order n. Let d(v) denote the degree of a vertex v ∈ V(G). We show that if
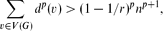 then G has more than
then G has more than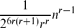 (r + 1)-cliques sharing a common edge. From this we deduce that if
(r + 1)-cliques sharing a common edge. From this we deduce that if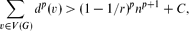 then G contains more than
then G contains more than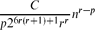 cliques of order r + 1.
cliques of order r + 1.In turn, this statement is used to strengthen the Erdős–Stone theorem by using ∑v ∈ V(G)dp(v) instead of the number of edges.
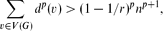
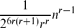
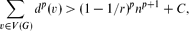
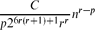
My Friend and Colleague, Richard Schelp
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 1-9
-
- Article
- Export citation
25 - Switching linear dynamical systems
- from IV - Dynamical models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 547-567
-
- Chapter
- Export citation
