Refine search
Actions for selected content:
48287 results in Computer Science
On quasi-interpretations, blind abstractions and implicit complexity†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 22 / Issue 4 / August 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 549-580
-
- Article
- Export citation
1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 1-2
-
- Chapter
- Export citation
On the Maximum Number of Edges in a Triple System Not Containing a Disjoint Family of a Given Size
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 141-148
-
- Article
- Export citation
27 - Sampling
- from V - Approximate inference
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 587-616
-
- Chapter
- Export citation
Compressions and Probably Intersecting Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 301-313
-
- Article
- Export citation
-
A family
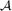
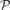
Standard compression techniques appear inadequate to solve the problem as they do not preserve intersection properties of subfamilies. Instead, our main tool is a novel compression method, together with a way of ‘compressing subfamilies’, which may be of independent interest.
II - Learning in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 163-164
-
- Chapter
- Export citation
28 - Deterministic approximate inference
- from V - Approximate inference
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 617-654
-
- Chapter
- Export citation
3 - Belief networks
- from 1 - Inference in probabilistic models
-
- Book:
- Bayesian Reasoning and Machine Learning
- Published online:
- 05 June 2012
- Print publication:
- 02 February 2012, pp 29-57
-
- Chapter
- Export citation
Medians and means in Finsler geometry
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 15 / May 2012
- Published online by Cambridge University Press:
- 01 February 2012, pp. 23-37
-
- Article
-
- You have access
- Export citation
ROB volume 30 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ROB volume 30 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Contents
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp vii-viii
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp i-vi
-
- Chapter
- Export citation
6 - Creating Analysis-Friendly Data
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 181-214
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 1-16
-
- Chapter
- Export citation
4 - Tuning Algorithms, Tuning Code
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 98-151
-
- Chapter
- Export citation
Preface
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp ix-x
-
- Chapter
- Export citation
3 - What to Measure
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 50-97
-
- Chapter
- Export citation
2 - A Plan of Attack
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 17-49
-
- Chapter
- Export citation
7 - Data Analysis
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 215-256
-
- Chapter
- Export citation
