Refine search
Actions for selected content:
48202 results in Computer Science
10 - Finite State Machines
- from PART II - Software Modeling
-
- Book:
- Software Modeling and Design
- Published online:
- 05 June 2012
- Print publication:
- 21 February 2011, pp 151-176
-
- Chapter
- Export citation
3 - Software Life Cycle Models and Processes
- from PART I - Overview
-
- Book:
- Software Modeling and Design
- Published online:
- 05 June 2012
- Print publication:
- 21 February 2011, pp 29-44
-
- Chapter
- Export citation
Almost Isoperimetric Subsets of the Discrete Cube
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 17 February 2011, pp. 363-380
-
- Article
- Export citation
-
We show that a set A ⊂ {0, 1}n with edge-boundary of size at most
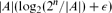 can be made into a subcube by at most (2ε/log2(1/ε))|A| additions and deletions, provided ε is less than an absolute constant.
can be made into a subcube by at most (2ε/log2(1/ε))|A| additions and deletions, provided ε is less than an absolute constant.We deduce that if A ⊂ {0, 1}n has size 2t for some t ∈ ℕ, and cannot be made into a subcube by fewer than δ|A| additions and deletions, then its edge-boundary has size at least
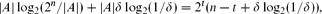 provided δ is less than an absolute constant. This is sharp whenever δ = 1/2j for some j ∈ {1, 2, . . ., t}.
provided δ is less than an absolute constant. This is sharp whenever δ = 1/2j for some j ∈ {1, 2, . . ., t}.
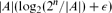
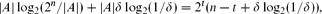
The Evolution of the Cover Time
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 15 February 2011, pp. 331-345
-
- Article
- Export citation
HUME’S PRINCIPLE, BEGINNINGS
-
- Journal:
- The Review of Symbolic Logic / Volume 4 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 14 February 2011, pp. 114-129
- Print publication:
- March 2011
-
- Article
- Export citation
Estimating the number of segments for improving dialogue act labelling†
-
- Journal:
- Natural Language Engineering / Volume 18 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 14 February 2011, pp. 1-19
-
- Article
- Export citation
The Blind Passenger and the Assignment Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 14 February 2011, pp. 467-480
-
- Article
- Export citation
Covering Complete r-Graphs with Spanning Complete r-Partite r-Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 09 February 2011, pp. 519-527
-
- Article
- Export citation
-
An r-cut of the complete r-uniform hypergraph Krn is obtained by partitioning its vertex set into r parts and taking all edges that meet every part in exactly one vertex. In other words it is the edge set of a spanning complete r-partite subhypergraph of Krn. An r-cut cover is a collection of r-cuts such that each edge of Krn is in at least one of the cuts. While in the graph case r = 2 any 2-cut cover on average covers each edge at least 2-o(1) times, when r is odd we exhibit an r-cut cover in which each edge is covered exactly once. When r is even no such decomposition can exist, but we can bound the average number of times an edge is cut in an r-cut cover between
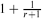 and
and 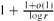 . The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
. The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
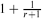 and
and 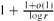 . The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
. The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.Ayurveda for agents: an attempt to bring the sciences of natural and artificial intelligence closer together
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 31-33
-
- Article
- Export citation
Formalizing knowledge and expertise: where have we been and where are we going?
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 5-10
-
- Article
- Export citation
From the journals…
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 73-97
-
- Article
- Export citation
Data mining: past, present and future
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 25-29
-
- Article
- Export citation
Algorithmic Game Theory by Noam Nisan, Tim Roughgarden, Éva Tardos and Vijay V. Vazirani, Cambridge University Press, 754 pp., £32.00, ISBN 0-521-87282-0
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 71-72
-
- Article
- Export citation
On the evolving relation between Belief Revision and Argumentation
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 35-43
-
- Article
- Export citation
Coordination models and languages: from parallel computing to self-organisation
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 53-59
-
- Article
- Export citation
From expert systems to context-based intelligent assistant systems: a testimony
-
- Journal:
- The Knowledge Engineering Review / Volume 26 / Issue 1 / 07 February 2011
- Published online by Cambridge University Press:
- 07 February 2011, pp. 19-24
-
- Article
- Export citation
