Refine search
Actions for selected content:
49488 results in Computer Science
Fast Inference for Probabilistic Answer Set Programs Via the Residual Program
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 682-697
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Teachers’ articulations of digital resources in an upper secondary programme for newly arrived migrants
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Abstract Environment Trimming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 863-884
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Lower Bounding Minimal Model Count
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 586-605
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Minimal models of a Boolean formula play a pivotal role in various reasoning tasks. While previous research has primarily focused on qualitative analysis over minimal models; our study concentrates on the quantitative aspect, specifically counting of minimal models. Exact counting of minimal models is strictly harder than
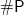 $\#\mathsf{P}$, prompting our investigation into establishing a lower bound for their quantity, which is often useful in related applications. In this paper, we introduce two novel techniques for counting minimal models, leveraging the expressive power of answer set programming: the first technique employs methods from knowledge compilation, while the second one draws on recent advancements in hashing-based approximate model counting. Through empirical evaluations, we demonstrate that our methods significantly improve the lower bound estimates of the number of minimal models, surpassing the performance of existing minimal model reasoning systems in terms of runtime.
$\#\mathsf{P}$, prompting our investigation into establishing a lower bound for their quantity, which is often useful in related applications. In this paper, we introduce two novel techniques for counting minimal models, leveraging the expressive power of answer set programming: the first technique employs methods from knowledge compilation, while the second one draws on recent advancements in hashing-based approximate model counting. Through empirical evaluations, we demonstrate that our methods significantly improve the lower bound estimates of the number of minimal models, surpassing the performance of existing minimal model reasoning systems in terms of runtime.
Reasoning About Study Regulations in Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 790-804
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Stable Model Semantics for Higher-Order Logic Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 737-754
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quantifying over Optimum Answer Sets
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 716-736
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Answer Set Programming with Quantifiers (ASP(Q)) has been introduced to provide a natural extension of ASP modeling to problems in the polynomial hierarchy (PH). However, ASP(Q) lacks a method for encoding in an elegant and compact way problems requiring a polynomial number of calls to an oracle in
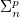 $\Sigma _n^p$ (that is, problems in
$\Sigma _n^p$ (that is, problems in 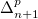 $\Delta _{n+1}^p$). Such problems include, in particular, optimization problems. In this paper, we propose an extension of ASP(Q), in which component programs may contain weak constraints. Weak constraints can be used both for expressing local optimization within quantified component programs and for modeling global optimization criteria. We showcase the modeling capabilities of the new formalism through various application scenarios. Further, we study its computational properties obtaining complexity results and unveiling non-obvious characteristics of ASP(Q) programs with weak constraints.
$\Delta _{n+1}^p$). Such problems include, in particular, optimization problems. In this paper, we propose an extension of ASP(Q), in which component programs may contain weak constraints. Weak constraints can be used both for expressing local optimization within quantified component programs and for modeling global optimization criteria. We showcase the modeling capabilities of the new formalism through various application scenarios. Further, we study its computational properties obtaining complexity results and unveiling non-obvious characteristics of ASP(Q) programs with weak constraints.
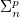
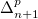
Modeling of spatial extremes in environmental data science: time to move away from max-stable processes
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 15 January 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards Probabilistic Inductive Logic Programming with Neurosymbolic Inference and Relaxation
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 628-643
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Winning Snake: Design Choices in Multi-Shot ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 772-789
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cyclic Supports in Recursive Bipolar Argumentation Frameworks: Semantics and LP Mapping
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 921-941
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automating Semantic Analysis of System Assurance Cases Using Goal-Directed ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 15 January 2025, pp. 805-824
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prompting for products: investigating design space exploration strategies for text-to-image generative models
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 15 January 2025, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modular Composition: An approach towards structural plasticity in music
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 13 January 2025, pp. 58-67
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sound Practices in the Global South: Co-listening to Resounding Plurilogues Budhaditya Chattopadhyay, Cham, Switzerland: Palgrave MacMillan, 2024. ISBN: 978-3-030-99731-1.
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 13 January 2025, pp. 81-82
- Print publication:
- April 2025
-
- Article
- Export citation
The Music of James Tenney Robert Wannamaker, Volume 1: Contexts and Paradigms; Volume 2: A Handbook to the Pieces. Champaign, IL: University of Illinois Press, 2021. ISBN: 978-0-252-04367-3.
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 13 January 2025, pp. 83-85
- Print publication:
- April 2025
-
- Article
- Export citation
THE ALGEBRAS OF LEWIS’S COUNTERFACTUALS: AXIOMATIZATIONS AND ALGEBRAIZABILITY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 10 January 2025, pp. 563-588
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Solving Decision Theory Problems with Probabilistic Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 January 2025, pp. 33-63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mixed-frequency VAR: a new approach to forecasting migration in Europe using macroeconomic data
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 January 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
