Refine search
Actions for selected content:
49522 results in Computer Science
AI for peace: mitigating the risks and enhancing opportunities
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 15 October 2024, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring collaborative writing among large groups in online distance learning through a public forum and private chat tool
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
L2 learner experiences in a playful constructivist metaverse space
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Table tennis ball landing control in a robotic system by cameras
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SyROCCo: enhancing systematic reviews using machine learning
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 14 October 2024, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Professionalism: bridging the missing link between environmental MRV and carbon neutrality
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 11 October 2024, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sampling repulsive Gibbs point processes using random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 October 2024, pp. 63-89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vertex-critical graphs far from edge-criticality
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 October 2024, pp. 151-157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $r$ be any positive integer. We prove that for every sufficiently large
$r$ be any positive integer. We prove that for every sufficiently large 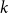 $k$ there exists a
$k$ there exists a 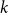 $k$-chromatic vertex-critical graph
$k$-chromatic vertex-critical graph 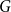 $G$ such that
$G$ such that  $\chi (G-R)=k$ for every set
$\chi (G-R)=k$ for every set 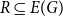 $R \subseteq E(G)$ with
$R \subseteq E(G)$ with 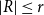 $|R|\le r$. This partially solves a problem posed by Erdős in 1985, who asked whether the above statement holds for
$|R|\le r$. This partially solves a problem posed by Erdős in 1985, who asked whether the above statement holds for 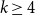 $k \ge 4$.
$k \ge 4$.


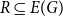
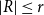
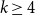

How to Think about Algorithms
-
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024
-
- Textbook
- Export citation
Historical Review of Variants of Informal Semantics for Logic Programs under Answer Set Semantics: GL’88, GL’91, GK’14, D-V’12
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 1031-1050
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Approximation of subgraph counts in the uniform attachment model
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 90-114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We use Stein’s method to obtain distributional approximations of subgraph counts in the uniform attachment model or random directed acyclic graph; we provide also estimates of rates of convergence. In particular, we give uni- and multi-variate Poisson approximations to the counts of cycles and normal approximations to the counts of unicyclic subgraphs; we also give a partial result for the counts of trees. We further find a class of multicyclic graphs whose subgraph counts are a.s. bounded as
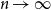 $n\to \infty$.
$n\to \infty$.
A novel morphing soft robot design to minimize deviations
-
- Article
- Export citation
-
Soft robotics is rapidly advancing, particularly in medical device applications. A particular miniaturized manipulator design that offers high dexterity, multiple degrees-of-freedom, and better lateral force rendering than competing designs, has great potential for minimally invasive surgery. However, it faces challenges such as the tendency to suddenly and unpredictably deviate in bending plane orientation at higher pressures. In this work, we identified the cause of this deviation as the buckling of the partition wall and proposed design alternatives along with their manufacturing process to address the problem without compromising the original design features. In both simulation and experiment, the novel design managed to achieve a better bending performance in terms of stiffness and reduced deviation of the bending plane. We also developed an artificial neural network-based inverse kinematics model to further improve the performance of the prototype during vectorization. This approach yielded mean absolute errors in orientation of the bending plane below
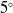 $5^{\circ }$.
$5^{\circ }$.
Digitally gamified co-creation: enhancing community engagement in urban design through a participant-centric framework
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 10 October 2024, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A note on extremal constructions for the Erdős–Rademacher problem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 52-62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For given positive integers
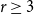 $r\ge 3$,
$r\ge 3$,  $n$ and
$n$ and 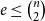 $e\le \binom{n}{2}$, the famous Erdős–Rademacher problem asks for the minimum number of
$e\le \binom{n}{2}$, the famous Erdős–Rademacher problem asks for the minimum number of  $r$-cliques in a graph with
$r$-cliques in a graph with  $n$ vertices and
$n$ vertices and  $e$ edges. A conjecture of Lovász and Simonovits from the 1970s states that, for every
$e$ edges. A conjecture of Lovász and Simonovits from the 1970s states that, for every 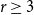 $r\ge 3$, if
$r\ge 3$, if  $n$ is sufficiently large then, for every
$n$ is sufficiently large then, for every  $e\le \binom{n}{2}$, at least one extremal graph can be obtained from a complete partite graph by adding a triangle-free graph into one part.
$e\le \binom{n}{2}$, at least one extremal graph can be obtained from a complete partite graph by adding a triangle-free graph into one part.In this note, we explicitly write the minimum number of
 $r$-cliques predicted by the above conjecture. Also, we describe what we believe to be the set of extremal graphs for any
$r$-cliques predicted by the above conjecture. Also, we describe what we believe to be the set of extremal graphs for any 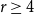 $r\ge 4$ and all large
$r\ge 4$ and all large  $n$, amending the previous conjecture of Pikhurko and Razborov.
$n$, amending the previous conjecture of Pikhurko and Razborov.
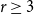

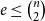



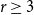



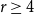

Evolution of cooperation in networks with well-connected cooperators
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 305-320
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 7 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Efficiency trumps aptitude: Individualizing computer-assisted second language vocabulary learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
