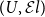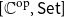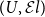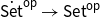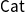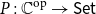Refine search
Actions for selected content:
49522 results in Computer Science
The complexity of completions in partial combinatory algebra
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 6 / June 2024
- Published online by Cambridge University Press:
- 23 September 2024, pp. 455-466
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We discuss the complexity of completions of partial combinatory algebras, in particular, of Kleene’s first model. Various completions of this model exist in the literature, but all of them have high complexity. We show that although there are no computable completions, there exist completions of low Turing degree. We use this construction to relate completions of Kleene’s first model to complete extensions of
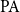 $\mathrm{PA}$. We also discuss the complexity of pcas defined from nonstandard models of
$\mathrm{PA}$. We also discuss the complexity of pcas defined from nonstandard models of 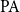 $\mathrm{PA}$.
$\mathrm{PA}$.
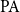
Advancing digital healthcare engineering for aging ships and offshore structures: an in-depth review and feasibility analysis – ERRATUM
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 20 September 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimizing soft robot design and tracking with and without evolutionary computation: an intensive survey
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The full rank condition for sparse random matrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 20 September 2024, pp. 643-707
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We derive a sufficient condition for a sparse random matrix with given numbers of non-zero entries in the rows and columns having full row rank. The result covers both matrices over finite fields with independent non-zero entries and
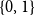 $\{0,1\}$-matrices over the rationals. The sufficient condition is generally necessary as well.
$\{0,1\}$-matrices over the rationals. The sufficient condition is generally necessary as well.
An approach for enhancing and measuring information comprehensibility for engineering designers: applied to patent documents
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Witnessing flows in arithmetic
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 7 / August 2024
- Published online by Cambridge University Press:
- 20 September 2024, pp. 578-614
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
One of the elegant achievements in the history of proof theory is the characterization of the provably total recursive functions of an arithmetical theory by its proof-theoretic ordinal as a way to measure the time complexity of the functions. Unfortunately, the machinery is not sufficiently fine-grained to be applicable on the weak theories, on the one hand and to capture the bounded functions with bounded definitions of strong theories, on the other. In this paper, we develop such a machinery to address the bounded theorems of both strong and weak theories of arithmetic. In the first part, we provide a refined version of ordinal analysis to capture the feasibly definable and bounded functions that are provably total in
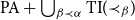 $\textrm{PA}+\bigcup _{\beta \prec \alpha } \textrm{TI}({\prec_{\beta}})$, the extension of Peano arithmetic by transfinite induction up to the ordinals below
$\textrm{PA}+\bigcup _{\beta \prec \alpha } \textrm{TI}({\prec_{\beta}})$, the extension of Peano arithmetic by transfinite induction up to the ordinals below 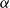 $\alpha$. Roughly speaking, we identify the functions as the ones that are computable by a sequence of
$\alpha$. Roughly speaking, we identify the functions as the ones that are computable by a sequence of 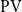 $\textrm{PV}$-provable polynomial time modifications on an initial polynomial time value, where the computational steps are indexed by the ordinals below
$\textrm{PV}$-provable polynomial time modifications on an initial polynomial time value, where the computational steps are indexed by the ordinals below 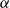 $\alpha$, decreasing by the modifications. In the second part, and choosing
$\alpha$, decreasing by the modifications. In the second part, and choosing 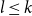 $l \leq k$, we use similar technique to capture the functions with bounded definitions in the theory
$l \leq k$, we use similar technique to capture the functions with bounded definitions in the theory 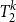 $T^k_2$ (resp.
$T^k_2$ (resp. 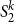 $S^k_2$) as the functions computable by exponentially (resp. polynomially) long sequence of
$S^k_2$) as the functions computable by exponentially (resp. polynomially) long sequence of 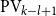 $\textrm{PV}_{k-l +1}$-provable reductions between
$\textrm{PV}_{k-l +1}$-provable reductions between 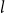 $l$-turn games starting with an explicit
$l$-turn games starting with an explicit 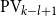 $\textrm{PV}_{k-l +1}$-provable winning strategy for the first game.
$\textrm{PV}_{k-l +1}$-provable winning strategy for the first game.
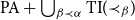
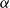
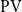
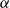
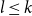
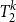
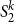
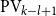
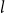
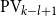
Asymptotics for the sum-ruin probability of a bi-dimensional compound risk model with dependent numbers of claims
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 20 September 2024, pp. 765-779
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From concrete mixture to structural design—a holistic optimization procedure in the presence of uncertainties
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 20 September 2024, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Emerging trends: a gentle introduction to RAG
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 20 September 2024, pp. 870-881
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The List-Ramsey threshold for families of graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 20 September 2024, pp. 829-851
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a family of graphs
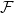 $\mathcal{F}$ and an integer
$\mathcal{F}$ and an integer  $r$, we say that a graph is
$r$, we say that a graph is  $r$-Ramsey for
$r$-Ramsey for 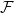 $\mathcal{F}$ if any
$\mathcal{F}$ if any  $r$-colouring of its edges admits a monochromatic copy of a graph from
$r$-colouring of its edges admits a monochromatic copy of a graph from 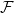 $\mathcal{F}$. The threshold for the classic Ramsey property, where
$\mathcal{F}$. The threshold for the classic Ramsey property, where 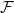 $\mathcal{F}$ consists of one graph, in the binomial random graph was located in the celebrated work of Rödl and Ruciński.
$\mathcal{F}$ consists of one graph, in the binomial random graph was located in the celebrated work of Rödl and Ruciński.In this paper, we offer a twofold generalisation to the Rödl–Ruciński theorem. First, we show that the list-colouring version of the property has the same threshold. Second, we extend this result to finite families
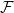 $\mathcal{F}$, where the threshold statements might also diverge. This also confirms further special cases of the Kohayakawa–Kreuter conjecture. Along the way, we supply a short(-ish), self-contained proof of the
$\mathcal{F}$, where the threshold statements might also diverge. This also confirms further special cases of the Kohayakawa–Kreuter conjecture. Along the way, we supply a short(-ish), self-contained proof of the 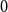 $0$-statement of the Rödl–Ruciński theorem.
$0$-statement of the Rödl–Ruciński theorem.



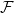
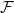
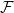
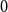
On Hofmann–Streicher universes
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 19 September 2024, pp. 894-910
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We take another look at the construction by Hofmann and Streicher of a universe
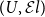 $(U,{\mathcal{E}l})$ for the interpretation of Martin-Löf type theory in a presheaf category
$(U,{\mathcal{E}l})$ for the interpretation of Martin-Löf type theory in a presheaf category 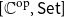 $[{{{\mathbb{C}}}^{\textrm{op}}},\textsf{Set}]$. It turns out that
$[{{{\mathbb{C}}}^{\textrm{op}}},\textsf{Set}]$. It turns out that 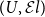 $(U,{\mathcal{E}l})$ can be described as the nerve of the classifier
$(U,{\mathcal{E}l})$ can be described as the nerve of the classifier 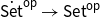 $\dot{{\textsf{Set}}}^{\textsf{op}} \rightarrow{{\textsf{Set}}}^{\textsf{op}}$ for discrete fibrations in
$\dot{{\textsf{Set}}}^{\textsf{op}} \rightarrow{{\textsf{Set}}}^{\textsf{op}}$ for discrete fibrations in 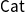 $\textsf{Cat}$, where the nerve functor is right adjoint to the so-called “Grothendieck construction” taking a presheaf
$\textsf{Cat}$, where the nerve functor is right adjoint to the so-called “Grothendieck construction” taking a presheaf 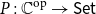 $P :{{{\mathbb{C}}}^{\textrm{op}}}\rightarrow{\textsf{Set}}$ to its category of elements
$P :{{{\mathbb{C}}}^{\textrm{op}}}\rightarrow{\textsf{Set}}$ to its category of elements  $\int _{\mathbb{C}} P$. We also consider change of base for such universes, as well as universes of structured families, such as fibrations.
$\int _{\mathbb{C}} P$. We also consider change of base for such universes, as well as universes of structured families, such as fibrations.