Refine search
Actions for selected content:
49525 results in Computer Science
Evolution of cooperation in networks with well-connected cooperators
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 305-320
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 7 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Efficiency trumps aptitude: Individualizing computer-assisted second language vocabulary learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 7 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Preface to the Special Issue on the 2022 Conference on Logic Programming and Nonmonotonic Reasoning
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 422-424
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Partial recovery and weak consistency in the non-uniform hypergraph stochastic block model
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 09 October 2024, pp. 1-51
-
- Article
- Export citation
-
We consider the community detection problem in sparse random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), a general model of random networks with community structure and higher-order interactions. When the random hypergraph has bounded expected degrees, we provide a spectral algorithm that outputs a partition with at least a
 $\gamma$ fraction of the vertices classified correctly, where
$\gamma$ fraction of the vertices classified correctly, where 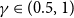 $\gamma \in (0.5,1)$ depends on the signal-to-noise ratio (SNR) of the model. When the SNR grows slowly as the number of vertices goes to infinity, our algorithm achieves weak consistency, which improves the previous results in Ghoshdastidar and Dukkipati ((2017) Ann. Stat. 45(1) 289–315.) for non-uniform HSBMs.
$\gamma \in (0.5,1)$ depends on the signal-to-noise ratio (SNR) of the model. When the SNR grows slowly as the number of vertices goes to infinity, our algorithm achieves weak consistency, which improves the previous results in Ghoshdastidar and Dukkipati ((2017) Ann. Stat. 45(1) 289–315.) for non-uniform HSBMs.Our spectral algorithm consists of three major steps: (1) Hyperedge selection: select hyperedges of certain sizes to provide the maximal signal-to-noise ratio for the induced sub-hypergraph; (2) Spectral partition: construct a regularised adjacency matrix and obtain an approximate partition based on singular vectors; (3) Correction and merging: incorporate the hyperedge information from adjacency tensors to upgrade the error rate guarantee. The theoretical analysis of our algorithm relies on the concentration and regularisation of the adjacency matrix for sparse non-uniform random hypergraphs, which can be of independent interest.

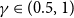
Sharing memory and wisdom across generations: A scaffolded community reminiscing programme for adolescents and older adults
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 03 October 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A semantic visual SLAM based on improved mask R-CNN in dynamic environment
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Algebraic effects and handlers for arrows
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 03 October 2024, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We present an arrow calculus with operations and handlers and its operational and denotational semantics. The calculus is an extension of Lindley, Wadler and Yallop’s arrow calculus.
The denotational semantics is given using a strong (pro)monad
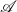 $\mathcal{A}$ in the bicategory of categories and profunctors. The construction of this strong monad
$\mathcal{A}$ in the bicategory of categories and profunctors. The construction of this strong monad 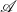 $\mathcal{A}$ is not trivial because of a size problem. To build denotational semantics, we investigate what
$\mathcal{A}$ is not trivial because of a size problem. To build denotational semantics, we investigate what 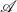 $\mathcal{A}$-algebras are, and a handler is interpreted as an
$\mathcal{A}$-algebras are, and a handler is interpreted as an 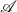 $\mathcal{A}$-homomorphisms between
$\mathcal{A}$-homomorphisms between 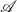 $\mathcal{A}$-algebras.
$\mathcal{A}$-algebras.The syntax and operational semantics are derived from the observations on
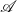 $\mathcal{A}$-algebras. We prove the soundness and adequacy theorem of the operational semantics for the denotational semantics.
$\mathcal{A}$-algebras. We prove the soundness and adequacy theorem of the operational semantics for the denotational semantics.
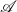
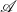
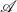
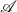
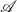
Special issue on logic and complexity
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 5 / May 2024
- Published online by Cambridge University Press:
- 02 October 2024, pp. 344-345
-
- Article
-
- You have access
- HTML
- Export citation
Adding an implication to logics of perfect paradefinite algebras
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 10 / November 2024
- Published online by Cambridge University Press:
- 02 October 2024, pp. 1138-1183
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Perfect paradefinite algebras are De Morgan algebras expanded with an operation that allows for the full behavior of classical negation to be restored. They form a variety that is term-equivalent to the variety of involutive Stone algebras. Their associated multiple-conclusion (Set-Set) and single-conclusion (
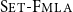 ) order-preserving logics are non-algebraizable self-extensional logics of formal inconsistency and undeterminedness determined by a six-valued matrix. We studied these logics extensively in Gomes et al. ((2022). Electronic Proceedings in Theoretical Computer Science 357 56–76.) from both the algebraic and the proof-theoretical perspectives. In the present paper, we continue that study by investigating directions for conservatively expanding these logics with an implication connective (essentially, one that admits the deduction-detachment theorem). We first consider logics given by very simple and manageable non-deterministic semantics whose implication (in isolation) is classical. These, nevertheless, fail to be self-extensional. We then consider the implication realized by the relative pseudo-complement over the six-valued perfect paradefinite algebra. Our strategy is to expand the language of the latter algebra with this connective and study the (self-extensional) Set-Set and
) order-preserving logics are non-algebraizable self-extensional logics of formal inconsistency and undeterminedness determined by a six-valued matrix. We studied these logics extensively in Gomes et al. ((2022). Electronic Proceedings in Theoretical Computer Science 357 56–76.) from both the algebraic and the proof-theoretical perspectives. In the present paper, we continue that study by investigating directions for conservatively expanding these logics with an implication connective (essentially, one that admits the deduction-detachment theorem). We first consider logics given by very simple and manageable non-deterministic semantics whose implication (in isolation) is classical. These, nevertheless, fail to be self-extensional. We then consider the implication realized by the relative pseudo-complement over the six-valued perfect paradefinite algebra. Our strategy is to expand the language of the latter algebra with this connective and study the (self-extensional) Set-Set and  order-preserving and
order-preserving and  $\top$-assertional logics of the variety induced by the resulting algebra. We provide axiomatizations for such new variety and for such logics, drawing parallels with the class of symmetric Heyting algebras and with Moisil’s “symmetric modal logic.” For the order-preserving Set-Set logic, in particular, we obtain a Set-Set axiomatization that is analytic. We close by studying interpolation properties for these logics and concluding that the new variety has the Maehara amalgamation property.
$\top$-assertional logics of the variety induced by the resulting algebra. We provide axiomatizations for such new variety and for such logics, drawing parallels with the class of symmetric Heyting algebras and with Moisil’s “symmetric modal logic.” For the order-preserving Set-Set logic, in particular, we obtain a Set-Set axiomatization that is analytic. We close by studying interpolation properties for these logics and concluding that the new variety has the Maehara amalgamation property.
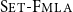 ) order-preserving logics are non-algebraizable self-extensional logics of formal inconsistency and undeterminedness determined by a six-valued matrix. We studied these logics extensively in Gomes et al. ((2022).
) order-preserving logics are non-algebraizable self-extensional logics of formal inconsistency and undeterminedness determined by a six-valued matrix. We studied these logics extensively in Gomes et al. ((2022).  order-preserving and
order-preserving and 
The not-so-forbidden triad: Evaluating the assumptions of the Strength of Weak Ties
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 October 2024, pp. 289-304
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
REFERENCE DIGRAPHS OF NON-SELF-REFERENTIAL PARADOXES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 30 September 2024, pp. 349-366
- Print publication:
- March 2025
-
- Article
- Export citation
Review of “Real World OCaml: Functional Programming for the Masses” Second Edition, by Yaron Minsky and Anil Madhavapeddy, 2023
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 27 September 2024, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Type-directed operational semantics for gradual typing
-
- Journal:
- Journal of Functional Programming / Volume 34 / 2024
- Published online by Cambridge University Press:
- 26 September 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The semantics of gradually typed languages is typically given indirectly via an elaboration into a cast calculus. This contrasts with more conventional formulations of programming language semantics, where the semantics of a language is given directly using, for instance, an operational semantics. This paper presents a new approach to give the semantics of gradually typed languages directly. We use a recently proposed variant of small-step operational semantics called type-directed operational semantics (TDOS). In a TDOS, type annotations become operationally relevant and can affect the result of a program. In the context of a gradually typed language, type annotations are used to trigger type-based conversions on values. We illustrate how to employ a TDOS on gradually typed languages using two calculi. The first calculus, called
 $\lambda B^{g}$, is inspired by the semantics of the blame calculus, but it has implicit type conversions, enabling it to be used as a gradually typed language. The second calculus, called
$\lambda B^{g}$, is inspired by the semantics of the blame calculus, but it has implicit type conversions, enabling it to be used as a gradually typed language. The second calculus, called  $\lambda e$, explores an eager semantics for gradually typed languages using a TDOS. For both calculi, type safety is proved. For the
$\lambda e$, explores an eager semantics for gradually typed languages using a TDOS. For both calculi, type safety is proved. For the 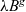 $\lambda B^{g}$ calculus, we also present a variant with blame labels and illustrate how the TDOS can also deal with such an important feature of gradually typed languages. We also show that the semantics of
$\lambda B^{g}$ calculus, we also present a variant with blame labels and illustrate how the TDOS can also deal with such an important feature of gradually typed languages. We also show that the semantics of  $\lambda B^{g}$ with blame labels is sound and complete with respect to the semantics of the blame calculus, and that both calculi come with a gradual guarantee. All the results have been formalized in the Coq theorem prover.
$\lambda B^{g}$ with blame labels is sound and complete with respect to the semantics of the blame calculus, and that both calculi come with a gradual guarantee. All the results have been formalized in the Coq theorem prover.



Torque, speed, and power requirements for the design of a lower limb exoskeleton to augment human finned swimming
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
