Refine search
Actions for selected content:
49522 results in Computer Science
Anticipating return migration to Ukraine: participatory foresight with Ukrainians displaced to Spain
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 23 October 2024, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An Introduction to Radical Biocracy: A relational, autonomous approach to decision-making towards emergent and symbiotic design
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 23 October 2024, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An integrated framework for importance-performance analysis of product attributes and validation from online reviews and maintenance records
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 23 October 2024, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Control and locomotion of tensegrity robots through manipulation of the center of mass
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The Cambridge Handbook of AI and Consumer Law
- Comparative Perspectives
-
- Published online:
- 21 October 2024
- Print publication:
- 31 October 2024
Requirements management for lean digital twins
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 21 October 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vision-based target localization and online error correction for high-precision robotic drilling
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Insights from the sustainable mobility using data in Latin America and the Caribbean special collection
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 21 October 2024, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automatic differentiation for ML-family languages: Correctness via logical relations
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 8 / September 2024
- Published online by Cambridge University Press:
- 21 October 2024, pp. 747-806
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We give a simple, direct, and reusable logical relations technique for languages with term and type recursion and partially defined differentiable functions. We demonstrate it by working out the case of automatic differentiation (AD) correctness: namely, we present a correctness proof of a dual numbers style AD code transformation for realistic functional languages in the ML-family. We also show how this code transformation provides us with correct forward- and reverse-mode AD.
The starting point is to interpret a functional programming language as a suitable freely generated categorical structure. In this setting, by the universal property of the syntactic categorical structure, the dual numbers AD code transformation and the basic
 $\boldsymbol{\omega } \mathbf{Cpo}$-semantics arise as structure preserving functors. The proof follows, then, by a novel logical relations argument.
$\boldsymbol{\omega } \mathbf{Cpo}$-semantics arise as structure preserving functors. The proof follows, then, by a novel logical relations argument.The key to much of our contribution is a powerful monadic logical relations technique for term recursion and recursive types. It provides us with a semantic correctness proof based on a simple approach for denotational semantics, making use only of the very basic concrete model of
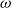 $\omega$-cpos.
$\omega$-cpos.

Opinion dynamics beyond social influence
-
- Journal:
- Network Science / Volume 12 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 21 October 2024, pp. 339-365
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Applied logic and semantics on indoor and urban adaptive design through knowledge graphs, reasoning and explainable argumentation
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 21 October 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unraveling the Brexit–COVID-19 nexus: assessing the decline of EU student applications into UK universities
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 21 October 2024, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Transparency challenges in policy evaluation with causal machine learning: improving usability and accountability
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 18 October 2024, e43
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reset controller synthesis: a correct-by-construction way to the design of CPS
-
- Journal:
- Research Directions: Cyber-Physical Systems / Volume 2 / 2024
- Published online by Cambridge University Press:
- 18 October 2024, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cokernel statistics for walk matrices of directed and weighted random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 18 October 2024, pp. 131-150
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The walk matrix associated to an
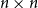 $n\times n$ integer matrix
$n\times n$ integer matrix 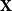 $\mathbf{X}$ and an integer vector
$\mathbf{X}$ and an integer vector 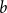 $b$ is defined by
$b$ is defined by 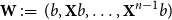 ${\mathbf{W}} \,:\!=\, (b,{\mathbf{X}} b,\ldots, {\mathbf{X}}^{n-1}b)$. We study limiting laws for the cokernel of
${\mathbf{W}} \,:\!=\, (b,{\mathbf{X}} b,\ldots, {\mathbf{X}}^{n-1}b)$. We study limiting laws for the cokernel of 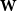 $\mathbf{W}$ in the scenario where
$\mathbf{W}$ in the scenario where 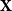 $\mathbf{X}$ is a random matrix with independent entries and
$\mathbf{X}$ is a random matrix with independent entries and 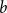 $b$ is deterministic. Our first main result provides a formula for the distribution of the
$b$ is deterministic. Our first main result provides a formula for the distribution of the 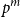 $p^m$-torsion part of the cokernel, as a group, when
$p^m$-torsion part of the cokernel, as a group, when 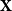 $\mathbf{X}$ has independent entries from a specific distribution. The second main result relaxes the distributional assumption and concerns the
$\mathbf{X}$ has independent entries from a specific distribution. The second main result relaxes the distributional assumption and concerns the 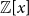 ${\mathbb{Z}}[x]$-module structure.
${\mathbb{Z}}[x]$-module structure.The motivation for this work arises from an open problem in spectral graph theory, which asks to show that random graphs are often determined up to isomorphism by their (generalised) spectrum. Sufficient conditions for generalised spectral determinacy can, namely, be stated in terms of the cokernel of a walk matrix. Extensions of our results could potentially be used to determine how often those conditions are satisfied. Some remaining challenges for such extensions are outlined in the paper.
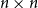
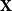
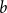
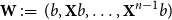
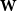
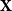
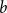
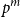
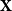
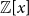
AI, big data, and quest for truth: the role of theoretical insight
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 18 October 2024, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Logistics efficiency in Brazilian cities applying data envelopment analysis
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 18 October 2024, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Part II - Financial Regulation and Investor Protection
-
- Book:
- The Cambridge Handbook of Law and Policy for NFTs
- Published online:
- 02 November 2024
- Print publication:
- 17 October 2024, pp 57-136
-
- Chapter
- Export citation
