Refine search
Actions for selected content:
48581 results in Computer Science
ARROW’S THEOREM, ULTRAFILTERS, AND REVERSE MATHEMATICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 29 February 2024, pp. 439-462
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper initiates the reverse mathematics of social choice theory, studying Arrow’s impossibility theorem and related results including Fishburn’s possibility theorem and the Kirman–Sondermann theorem within the framework of reverse mathematics. We formalise fundamental notions of social choice theory in second-order arithmetic, yielding a definition of countable society which is tractable in
 ${\mathsf {RCA}}_0$. We then show that the Kirman–Sondermann analysis of social welfare functions can be carried out in
${\mathsf {RCA}}_0$. We then show that the Kirman–Sondermann analysis of social welfare functions can be carried out in  ${\mathsf {RCA}}_0$. This approach yields a proof of Arrow’s theorem in
${\mathsf {RCA}}_0$. This approach yields a proof of Arrow’s theorem in  ${\mathsf {RCA}}_0$, and thus in
${\mathsf {RCA}}_0$, and thus in  $\mathrm {PRA}$, since Arrow’s theorem can be formalised as a
$\mathrm {PRA}$, since Arrow’s theorem can be formalised as a  $\Pi ^0_1$ sentence. Finally we show that Fishburn’s possibility theorem for countable societies is equivalent to
$\Pi ^0_1$ sentence. Finally we show that Fishburn’s possibility theorem for countable societies is equivalent to  ${\mathsf {ACA}}_0$ over
${\mathsf {ACA}}_0$ over  ${\mathsf {RCA}}_0$.
${\mathsf {RCA}}_0$.







Notes on contributors
-
- Book:
- Human Perception and Digital Information Technologies
- Published by:
- Bristol University Press
- Published online:
- 18 December 2024
- Print publication:
- 29 February 2024, pp ix-xii
-
- Chapter
- Export citation

Humor 2.0
- How the Internet Changed Humor
-
- Published by:
- Anthem Press
- Published online:
- 28 February 2024
- Print publication:
- 15 August 2023
Spontaneous transmedia co-location: Integration in memory
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 28 February 2024, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian state-space synthetic control method for deforestation baseline estimation for forest carbon credits
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 28 February 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Digital remembrance: Honouring Srebrenica genocide victims via #ŠtoTeNema
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 26 February 2024, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Shall the robots remember? Conceptualising the role of non-human agents in digital memory communication
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 26 February 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Motorized three-wheelers and their potential for just mobility in Caribbean urban areas
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 26 February 2024, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A bibliometric analysis of artificial intelligence in L2 teaching and applied linguistics between 1995 and 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perceptions of learning from audiovisual input and changes in L2 viewing preferences: The roles of on-screen text and proficiency
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The multiplicities of platformed remembering
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 23 February 2024, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vocabulary learning through viewing dual-subtitled videos: Immediate repetition versus spaced repetition as an enhancement strategy
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The internet will not remember you: curation of autobiographical online materials in Russia in Spring 2022
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 23 February 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

People's Parks
- The Design and Development of Public Parks in Britain
-
- Published by:
- Boydell & Brewer
- Published online:
- 22 February 2024
- Print publication:
- 14 November 2023
CONCEPTUAL DISTANCE AND ALGEBRAS OF CONCEPTS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 22 February 2024, pp. 300-315
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Small subsets with large sumset: Beyond the Cauchy–Davenport bound
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 21 February 2024, pp. 411-431
-
- Article
- Export citation
-
For a subset
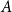 $A$ of an abelian group
$A$ of an abelian group 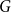 $G$, given its size
$G$, given its size 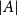 $|A|$, its doubling
$|A|$, its doubling 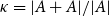 $\kappa =|A+A|/|A|$, and a parameter
$\kappa =|A+A|/|A|$, and a parameter  $s$ which is small compared to
$s$ which is small compared to 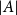 $|A|$, we study the size of the largest sumset
$|A|$, we study the size of the largest sumset 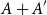 $A+A'$ that can be guaranteed for a subset
$A+A'$ that can be guaranteed for a subset 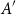 $A'$ of
$A'$ of 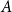 $A$ of size at most
$A$ of size at most  $s$. We show that a subset
$s$. We show that a subset 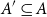 $A'\subseteq A$ of size at most
$A'\subseteq A$ of size at most  $s$ can be found so that
$s$ can be found so that 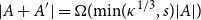 $|A+A'| = \Omega (\!\min\! (\kappa ^{1/3},s)|A|)$. Thus, a sumset significantly larger than the Cauchy–Davenport bound can be guaranteed by a bounded size subset assuming that the doubling
$|A+A'| = \Omega (\!\min\! (\kappa ^{1/3},s)|A|)$. Thus, a sumset significantly larger than the Cauchy–Davenport bound can be guaranteed by a bounded size subset assuming that the doubling  $\kappa$ is large. Building up on the same ideas, we resolve a conjecture of Bollobás, Leader and Tiba that for subsets
$\kappa$ is large. Building up on the same ideas, we resolve a conjecture of Bollobás, Leader and Tiba that for subsets 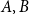 $A,B$ of
$A,B$ of 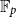 $\mathbb{F}_p$ of size at most
$\mathbb{F}_p$ of size at most 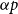 $\alpha p$ for an appropriate constant
$\alpha p$ for an appropriate constant 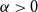 $\alpha \gt 0$, one only needs three elements
$\alpha \gt 0$, one only needs three elements 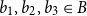 $b_1,b_2,b_3\in B$ to guarantee
$b_1,b_2,b_3\in B$ to guarantee 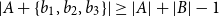 $|A+\{b_1,b_2,b_3\}|\ge |A|+|B|-1$. Allowing the use of larger subsets
$|A+\{b_1,b_2,b_3\}|\ge |A|+|B|-1$. Allowing the use of larger subsets 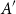 $A'$, we show that for sets
$A'$, we show that for sets 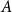 $A$ of bounded doubling, one only needs a subset
$A$ of bounded doubling, one only needs a subset 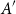 $A'$ with
$A'$ with 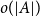 $o(|A|)$ elements to guarantee that
$o(|A|)$ elements to guarantee that 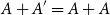 $A+A'=A+A$. We also address another conjecture and a question raised by Bollobás, Leader and Tiba on high-dimensional analogues and sets whose sumset cannot be saturated by a bounded size subset.
$A+A'=A+A$. We also address another conjecture and a question raised by Bollobás, Leader and Tiba on high-dimensional analogues and sets whose sumset cannot be saturated by a bounded size subset.
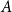
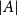
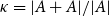

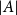
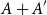
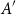
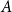

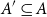

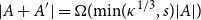

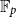
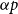
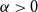
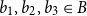
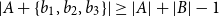
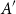
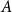
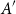
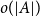
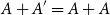
Design team formation using self-assessment and observer-assessment techniques: mapping practices in a global network of universities
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 21 February 2024, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
