Refine search
Actions for selected content:
49522 results in Computer Science
An analytical study of Euler angle and Rodrigues parameter representations of
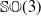 $\mathbb{SO}(3)$ towards describing subsets of
$\mathbb{SO}(3)$ towards describing subsets of 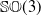 ${\mathbb{SO}}(3)$ geometrically and establishing the relations between these
${\mathbb{SO}}(3)$ geometrically and establishing the relations between these
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Descriptions of various subsets of
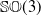 $\mathbb{SO}(3)$ are encountered frequently in robotics, for example, in the context of specifying the orientation workspaces of manipulators. Often, the Cartesian concept of a cuboid is extended into the domain of Euler angles, notwithstanding the fact that the physical implications of this practice are not documented. Motivated by this lacuna in the existing literature, this article focuses on studying sets of rotations described by such cuboids by mapping them to the space of Rodrigues parameters, where a physically meaningful measure of distance from the origin is available and the spherical geometry is intrinsically pertinent. It is established that the planar faces of the said cuboid transform into hyperboloids of one sheet and hence, the cuboid itself maps into a solid of complicated non-convex shape. To quantify the extents of these solids, the largest spheres contained within them are computed analytically. It is expected that this study would help in the process of design and path planning of spatial robots, especially those of parallel architecture, due to a better and quantitative understanding of their orientation workspaces.
$\mathbb{SO}(3)$ are encountered frequently in robotics, for example, in the context of specifying the orientation workspaces of manipulators. Often, the Cartesian concept of a cuboid is extended into the domain of Euler angles, notwithstanding the fact that the physical implications of this practice are not documented. Motivated by this lacuna in the existing literature, this article focuses on studying sets of rotations described by such cuboids by mapping them to the space of Rodrigues parameters, where a physically meaningful measure of distance from the origin is available and the spherical geometry is intrinsically pertinent. It is established that the planar faces of the said cuboid transform into hyperboloids of one sheet and hence, the cuboid itself maps into a solid of complicated non-convex shape. To quantify the extents of these solids, the largest spheres contained within them are computed analytically. It is expected that this study would help in the process of design and path planning of spatial robots, especially those of parallel architecture, due to a better and quantitative understanding of their orientation workspaces.
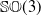
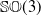
On the Foundations of Conflict-Driven Solving for Hybrid MKNF Knowledge Bases
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 28 October 2024, pp. 901-920
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CON-FOLD Explainable Machine Learning with Confidence
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 28 October 2024, pp. 663-681
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Informal digital learning of English in teachers: development and validation of a scale
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimising Dynamic Traffic Distribution for Urban Networks with Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 28 October 2024, pp. 825-843
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bridging the gap between requirements engineering and systems architecting: the Elephant Specification Language
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 28 October 2024, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Practical Reasoning in DatalogMTL
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 28 October 2024, pp. 225-255
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximal cliques in scale-free random graphs
-
- Journal:
- Network Science / Volume 12 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 28 October 2024, pp. 366-391
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Examining generative AI–mediated informal digital learning of English practices with social cognitive theory: a mixed-methods study
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Highway digital twin-enabled Autonomous Maintenance Plant: a perspective
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Soap ’n’ AI
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 25 October 2024, pp. 1155-1160
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A human-centered approach for sharing patient experiences through digital storytelling: a research through design study
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clustering of listed stock exchange companies active in the cement using the FPC clustering algorithm
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing emerging technologies taking into account upscaling
- Part of
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What, how and when should I prototype? An empirical study of design team prototyping practices at the IDEA challenge hackathon
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The uneven deployment of algorithms as tools in government: evidence from the use of an expert system
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 25 October 2024, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface
-
- Book:
- Search Methods in Artificial Intelligence
- Published online:
- 30 April 2024
- Print publication:
- 24 October 2024, pp xi-xii
-
- Chapter
- Export citation
4 - Heuristic Search
-
- Book:
- Search Methods in Artificial Intelligence
- Published online:
- 30 April 2024
- Print publication:
- 24 October 2024, pp 75-114
-
- Chapter
- Export citation
An entangled memoryscape: Holocaust memory on social media
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 24 October 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
