Refine search
Actions for selected content:
48584 results in Computer Science
Discrete equational theories
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 2 / February 2024
- Published online by Cambridge University Press:
- 22 January 2024, pp. 147-160
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
On a locally
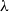 $\lambda$-presentable symmetric monoidal closed category
$\lambda$-presentable symmetric monoidal closed category 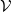 $\mathcal {V}$,
$\mathcal {V}$, 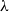 $\lambda$-ary enriched equational theories correspond to enriched monads preserving
$\lambda$-ary enriched equational theories correspond to enriched monads preserving 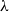 $\lambda$-filtered colimits. We introduce discrete
$\lambda$-filtered colimits. We introduce discrete 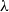 $\lambda$-ary enriched equational theories where operations are induced by those having discrete arities (equations are not required to have discrete arities) and show that they correspond to enriched monads preserving preserving
$\lambda$-ary enriched equational theories where operations are induced by those having discrete arities (equations are not required to have discrete arities) and show that they correspond to enriched monads preserving preserving 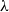 $\lambda$-filtered colimits and surjections. Using it, we prove enriched Birkhof-type theorems for categories of algebras of discrete theories. This extends known results from metric spaces and posets to general symmetric monoidal closed categories.
$\lambda$-filtered colimits and surjections. Using it, we prove enriched Birkhof-type theorems for categories of algebras of discrete theories. This extends known results from metric spaces and posets to general symmetric monoidal closed categories.
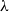
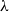
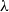
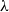
Locally Tight Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 19 January 2024, pp. 942-972
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automated detection of edge clusters via an overfitted mixture prior
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 19 January 2024, pp. 88-106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Employer Engagement
- Making Active Labour Market Policies Work
-
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023
8 - Even More Devastating: Chaitin’s Incompleteness Theorem
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 174-189
-
- Chapter
- Export citation
9 - Gödel (For Real, This Time)
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 190-233
-
- Chapter
- Export citation
2 - Moments and Tails
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 21-94
-
- Chapter
- Export citation
Index
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 429-434
-
- Chapter
- Export citation
Appendix B - Measure–Theoretic Foundations
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 398-418
-
- Chapter
- Export citation
4 - Coupling
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 182-255
-
- Chapter
- Export citation
5 - Spectral Methods
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 256-326
-
- Chapter
- Export citation
Contents
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp vii-x
-
- Chapter
- Export citation
Index
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 246-254
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 419-428
-
- Chapter
- Export citation
Notation
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp xv-xvi
-
- Chapter
- Export citation
Preface
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp xi-xiv
-
- Chapter
- Export citation
3 - Enjoying Bell Magic: With Inequalities and Without
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp 40-77
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Modern Discrete Probability
- Published online:
- 14 December 2023
- Print publication:
- 18 January 2024, pp 1-20
-
- Chapter
-
- You have access
- Export citation
Contents
-
- Book:
- Proven Impossible
- Published online:
- 18 February 2024
- Print publication:
- 18 January 2024, pp vii-xii
-
- Chapter
- Export citation
