Refine search
Actions for selected content:
49525 results in Computer Science
Towards capsule endoscope locomotion in large volumes: design, fuzzy modeling, and testing
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contract lenses: Reasoning about bidirectional programs via calculation
-
- Journal:
- Journal of Functional Programming / Volume 33 / 2023
- Published online by Cambridge University Press:
- 06 November 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Bidirectional transformations (BXs) are a mechanism for maintaining consistency between multiple representations of related data. The lens framework, which usually constructs BXs from lens combinators, has become the mainstream approach to BX programming because of its modularity and correctness by construction. However, the involved bidirectional behaviors of lenses make the equational reasoning and optimization of them much harder than unidirectional programs. We propose a novel approach to deriving efficient lenses from clear specifications via program calculation, a correct-by-construction approach to reasoning about functional programs by algebraic laws. To support bidirectional program calculation, we propose contract lenses, which extend conventional lenses with a pair of predicates to enable safe and modular composition of partial lenses. We define several contract-lens combinators capturing common computation patterns including
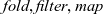 $\textit{fold}, \textit{filter},\textit{map}$, and
$\textit{fold}, \textit{filter},\textit{map}$, and  $\textit{scan}$, and develop several bidirectional calculation laws to reason about and optimize contract lenses. We demonstrate the effectiveness of our new calculation framework based on contract lenses with nontrivial examples.
$\textit{scan}$, and develop several bidirectional calculation laws to reason about and optimize contract lenses. We demonstrate the effectiveness of our new calculation framework based on contract lenses with nontrivial examples.
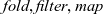

On the choosability of
 $H$-minor-free graphs
$H$-minor-free graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 03 November 2023, pp. 129-142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a graph
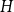 $H$, let us denote by
$H$, let us denote by 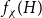 $f_\chi (H)$ and
$f_\chi (H)$ and 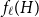 $f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of
$f_\ell (H)$, respectively, the maximum chromatic number and the maximum list chromatic number of 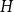 $H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that
$H$-minor-free graphs. Hadwiger’s famous colouring conjecture from 1943 states that 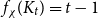 $f_\chi (K_t)=t-1$ for every
$f_\chi (K_t)=t-1$ for every 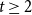 $t \ge 2$. A closely related problem that has received significant attention in the past concerns
$t \ge 2$. A closely related problem that has received significant attention in the past concerns 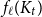 $f_\ell (K_t)$, for which it is known that
$f_\ell (K_t)$, for which it is known that 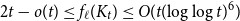 $2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus,
$2t-o(t) \le f_\ell (K_t) \le O(t (\!\log \log t)^6)$. Thus, 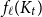 $f_\ell (K_t)$ is bounded away from the conjectured value
$f_\ell (K_t)$ is bounded away from the conjectured value 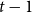 $t-1$ for
$t-1$ for 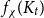 $f_\chi (K_t)$ by at least a constant factor. The so-called
$f_\chi (K_t)$ by at least a constant factor. The so-called 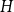 $H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that
$H$-Hadwiger’s conjecture, proposed by Seymour, asks to prove that 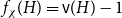 $f_\chi (H)={\textrm{v}}(H)-1$ for a given graph
$f_\chi (H)={\textrm{v}}(H)-1$ for a given graph 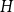 $H$ (which would be implied by Hadwiger’s conjecture).
$H$ (which would be implied by Hadwiger’s conjecture).In this paper, we prove several new lower bounds on
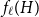 $f_\ell (H)$, thus exploring the limits of a list colouring extension of
$f_\ell (H)$, thus exploring the limits of a list colouring extension of 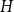 $H$-Hadwiger’s conjecture. Our main results are:
$H$-Hadwiger’s conjecture. Our main results are:For every
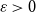 $\varepsilon \gt 0$ and all sufficiently large graphs
$\varepsilon \gt 0$ and all sufficiently large graphs 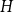 $H$ we have
$H$ we have 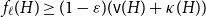 $f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where
$f_\ell (H)\ge (1-\varepsilon )({\textrm{v}}(H)+\kappa (H))$, where 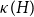 $\kappa (H)$ denotes the vertex-connectivity of
$\kappa (H)$ denotes the vertex-connectivity of 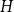 $H$.
$H$.For every
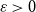 $\varepsilon \gt 0$ there exists
$\varepsilon \gt 0$ there exists 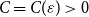 $C=C(\varepsilon )\gt 0$ such that asymptotically almost every
$C=C(\varepsilon )\gt 0$ such that asymptotically almost every  $n$-vertex graph
$n$-vertex graph 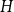 $H$ with
$H$ with 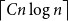 $\left \lceil C n\log n\right \rceil$ edges satisfies
$\left \lceil C n\log n\right \rceil$ edges satisfies 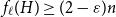 $f_\ell (H)\ge (2-\varepsilon )n$.
$f_\ell (H)\ge (2-\varepsilon )n$.
The first result generalizes recent results on complete and complete bipartite graphs and shows that the list chromatic number of
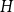 $H$-minor-free graphs is separated from the desired value of
$H$-minor-free graphs is separated from the desired value of 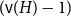 $({\textrm{v}}(H)-1)$ by a constant factor for all large graphs
$({\textrm{v}}(H)-1)$ by a constant factor for all large graphs 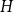 $H$ of linear connectivity. The second result tells us that for almost all graphs
$H$ of linear connectivity. The second result tells us that for almost all graphs 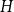 $H$ with superlogarithmic average degree
$H$ with superlogarithmic average degree 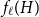 $f_\ell (H)$ is separated from
$f_\ell (H)$ is separated from 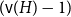 $({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to
$({\textrm{v}}(H)-1)$ by a constant factor arbitrarily close to 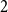 $2$. Conceptually these results indicate that the graphs
$2$. Conceptually these results indicate that the graphs 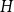 $H$ for which
$H$ for which 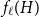 $f_\ell (H)$ is close to the conjectured value
$f_\ell (H)$ is close to the conjectured value 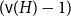 $({\textrm{v}}(H)-1)$ for
$({\textrm{v}}(H)-1)$ for 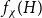 $f_\chi (H)$ are typically rather sparse.
$f_\chi (H)$ are typically rather sparse.
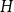
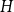
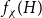
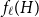
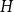
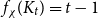
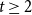
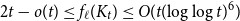
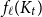
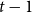
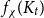
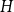
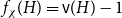
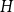
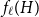
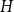
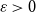
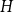
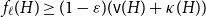
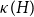
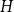
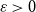
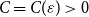

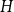
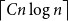
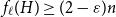
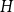
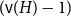
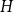
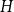
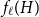
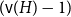
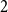
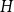
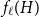
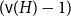
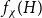
Parametrized polyconvex hyperelasticity with physics-augmented neural networks
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A semantic similarity-based method to support the conversion from EXPRESS to OWL
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embedding data science innovations in organizations: a new workflow approach
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Incomplete to complete multiphysics forecasting: a hybrid approach for learning unknown phenomena
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 03 November 2023, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Material dialogues for first-order logic in constructive type theory: extended version
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 7 / August 2024
- Published online by Cambridge University Press:
- 03 November 2023, pp. 689-709
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Security in the Cyber Age
- An Introduction to Policy and Technology
-
- Published online:
- 02 November 2023
- Print publication:
- 16 November 2023
2 - Bird’s–Eye View
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 31-54
-
- Chapter
- Export citation
6 - Visual Perception
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 129-154
-
- Chapter
- Export citation
10 - Interaction
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 245-270
-
- Chapter
- Export citation
11 - Audio
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 271-292
-
- Chapter
- Export citation
9 - Tracking
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 211-244
-
- Chapter
- Export citation
References
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 340-356
-
- Chapter
- Export citation
3 - The Geometry of Virtual Worlds
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 55-81
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 1-30
-
- Chapter
- Export citation
7 - Visual Rendering
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 155-184
-
- Chapter
- Export citation
8 - Motion in Real and Virtual Worlds
-
- Book:
- Virtual Reality
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023, pp 185-210
-
- Chapter
- Export citation
