Refine search
Actions for selected content:
49525 results in Computer Science
7 - Denialist Speech
- from Part II - The Legal Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 399-486
-
- Chapter
- Export citation
6 - Between Hate Speech and Hate Crime
- from Part II - The Legal Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 363-398
-
- Chapter
- Export citation
Index
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 593-600
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp iv-iv
-
- Chapter
- Export citation
1 - Conceptual Frontiers in the Understanding of Hate Speech
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 1-44
-
- Chapter
-
- You have access
- HTML
- Export citation
2 - Prototypical Examples of Hate Speech
- from Part I - The Ordinary Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 47-87
-
- Chapter
- Export citation
5 - Orienting the Ordinary and Legal Concepts of Hate Speech
- from Part II - The Legal Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 329-362
-
- Chapter
- Export citation
4 - Attacks on the Identities of Groups
- from Part I - The Ordinary Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 209-326
-
- Chapter
- Export citation
Dedication
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp v-vi
-
- Chapter
- Export citation
Part I - The Ordinary Concept
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp 45-326
-
- Chapter
- Export citation
Contents
-
- Book:
- Hate Speech Frontiers
- Published online:
- 26 October 2023
- Print publication:
- 09 November 2023, pp vii-vii
-
- Chapter
- Export citation

Joy with Java
- Fundamentals of Object Oriented Programming
-
- Published online:
- 08 November 2023
- Print publication:
- 15 June 2023
-
- Textbook
- Export citation
Reformulation techniques for automated planning: a systematic review
-
- Journal:
- The Knowledge Engineering Review / Volume 38 / 2023
- Published online by Cambridge University Press:
- 08 November 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using active learning and an agent-based system to perform interactive knowledge extraction based on the COVID-19 corpus
-
- Journal:
- The Knowledge Engineering Review / Volume 38 / 2023
- Published online by Cambridge University Press:
- 08 November 2023, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On oriented cycles in randomly perturbed digraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 157-178
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In 2003, Bohman, Frieze, and Martin initiated the study of randomly perturbed graphs and digraphs. For digraphs, they showed that for every
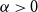 $\alpha \gt 0$, there exists a constant
$\alpha \gt 0$, there exists a constant 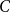 $C$ such that for every
$C$ such that for every  $n$-vertex digraph of minimum semi-degree at least
$n$-vertex digraph of minimum semi-degree at least 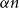 $\alpha n$, if one adds
$\alpha n$, if one adds 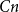 $Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree
$Cn$ random edges then asymptotically almost surely the resulting digraph contains a consistently oriented Hamilton cycle. We generalize their result, showing that the hypothesis of this theorem actually asymptotically almost surely ensures the existence of every orientation of a cycle of every possible length, simultaneously. Moreover, we prove that we can relax the minimum semi-degree condition to a minimum total degree condition when considering orientations of a cycle that do not contain a large number of vertices of indegree 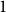 $1$. Our proofs make use of a variant of an absorbing method of Montgomery.
$1$. Our proofs make use of a variant of an absorbing method of Montgomery.
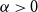
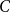

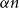
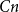
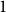
Mastermind with a linear number of queries
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 November 2023, pp. 143-156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Since the 1960s Mastermind has been studied for the combinatorial and information-theoretical interest the game has to offer. Many results have been discovered starting with Erdős and Rényi determining the optimal number of queries needed for two colours. For
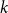 $k$ colours and
$k$ colours and  $n$ positions, Chvátal found asymptotically optimal bounds when
$n$ positions, Chvátal found asymptotically optimal bounds when 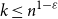 $k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for
$k \le n^{1-\varepsilon }$. Following a sequence of gradual improvements for 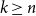 $k\geq n$ colours, the central open question is to resolve the gap between
$k\geq n$ colours, the central open question is to resolve the gap between 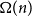 $\Omega (n)$ and
$\Omega (n)$ and 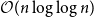 $\mathcal{O}(n\log \log n)$ for
$\mathcal{O}(n\log \log n)$ for 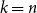 $k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving
$k=n$. In this paper, we resolve this gap by presenting the first algorithm for solving 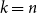 $k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters
$k=n$ Mastermind with a linear number of queries. As a consequence, we are able to determine the query complexity of Mastermind for any parameters 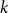 $k$ and
$k$ and  $n$.
$n$.

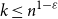
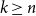
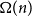
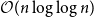
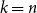
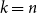

Cross-modal distillation for flood extent mapping
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 07 November 2023, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabeled dataset of paired multi-spectral and synthetic aperture radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabeled data by creating weak labels out of them. However, from our experiments, we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi-supervised learning, we explore the use of a teacher to train a student with the help of a small hand-labeled dataset and a large unlabeled dataset. Unlike the conventional self-distillation setup, we propose a cross-modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak-labeled SAR imagery by an absolute margin of
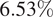 $ 6.53\% $ intersection over union (IoU) on the test split.
$ 6.53\% $ intersection over union (IoU) on the test split.
Graph-based methods for discrete choice
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 06 November 2023, pp. 21-40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
