Refine search
Actions for selected content:
48584 results in Computer Science
Voluntary use of automated writing evaluation by content course students
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Linear capabilities for fully abstract compilation of separation-logic-verified code
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 31 / 2021
- Published online by Cambridge University Press:
- 30 March 2021, e6
-
- Article
-
- You have access
- Export citation
The effect of ultrafiltration transmembrane permeation on the flow field in a surrogate system of an artificial kidney
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 30 March 2021, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Renal Replacement Therapies generally associated to the Artificial Kidney (AK) are membrane-based treatments that assure the separation functions of the failing kidney in extracorporeal blood circulation. Their progress from conventional hemodialysis towards high-flux hemodialysis (HFHD) through the introduction of ultrafiltration membranes characterized by high convective permeation fluxes intensified the need of elucidating the effect of the membrane fluid removal rates on the increase of the potentially blood-traumatizing shear stresses developed adjacently to the membrane. The AK surrogate consisting of two-compartments separated by an ultrafiltration membrane is set to have water circulation in the upper chamber mimicking the blood flow rates and the membrane fluid removal rates typical of HFHD. Pressure drop mirrors the shear stresses quantification and the modification of the velocities profiles. The increase on pressure drop when comparing flows in slits with a permeable membrane and an impermeable wall is ca. 512% and 576% for
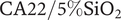 $ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and
$ \mathrm{CA}22/5\%{\mathrm{SiO}}_2 $ and 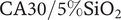 $ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.
$ \mathrm{CA}30/5\%{\mathrm{SiO}}_2 $ membranes, respectively.

Governing Privacy in Knowledge Commons
-
- Published online:
- 29 March 2021
- Print publication:
- 25 March 2021
-
- Book
-
- You have access
- Open access
- Export citation
PES volume 35 issue 2 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. f1-f2
-
- Article
-
- You have access
- Export citation
PES volume 35 issue 2 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 29 March 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation

Hey Cyba
- The Inner Workings of a Virtual Personal Assistant
-
- Published online:
- 26 March 2021
- Print publication:
- 08 April 2021
2 - How Private Individuals Maintain Privacy and Govern Their Own Health Data Cooperative
- from Part I - Personal Information as a Knowledge Commons Resource
-
-
- Book:
- Governing Privacy in Knowledge Commons
- Published online:
- 29 March 2021
- Print publication:
- 25 March 2021, pp 53-69
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
22 - Artificial Intelligence
- from Part IV - Outlook
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 231-240
-
- Chapter
- Export citation
2 - The h-Index
- from Part I - The Science of Career
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 17-27
-
- Chapter
- Export citation
10 - Coauthorship Networks
- from Part II - The Science of Collaboration
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 102-109
-
- Chapter
- Export citation
Index
-
- Book:
- Mathematical Foundations of Infinite-Dimensional Statistical Models
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021, pp 687-690
-
- Chapter
- Export citation
1 - Productivity of a Scientist
- from Part I - The Science of Career
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 7-16
-
- Chapter
- Export citation
23 - Bias and Causality in Science
- from Part IV - Outlook
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 241-251
-
- Chapter
- Export citation
5 - Random Impact Rule
- from Part I - The Science of Career
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 51-59
-
- Chapter
- Export citation
Part I - Personal Information as a Knowledge Commons Resource
-
- Book:
- Governing Privacy in Knowledge Commons
- Published online:
- 29 March 2021
- Print publication:
- 25 March 2021, pp 51-148
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
19 - The Time Dimension of Science
- from Part III - The Science of Impact
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 197-208
-
- Chapter
- Export citation
16 - Citation Disparity
- from Part III - The Science of Impact
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 174-183
-
- Chapter
- Export citation
5 - Public Facebook Groups for Political Activism
- from Part I - Personal Information as a Knowledge Commons Resource
-
-
- Book:
- Governing Privacy in Knowledge Commons
- Published online:
- 29 March 2021
- Print publication:
- 25 March 2021, pp 121-148
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
20 - Ultimate Impact
- from Part III - The Science of Impact
-
- Book:
- The Science of Science
- Published online:
- 07 February 2021
- Print publication:
- 25 March 2021, pp 209-220
-
- Chapter
- Export citation
