Refine search
Actions for selected content:
48202 results in Computer Science
8 - Constitutionalizing Internet Governance
- from Part II - A New Social Contract – Constitutionalizing Internet Governance
-
- Book:
- Lawless
- Published online:
- 22 June 2019
- Print publication:
- 18 July 2019, pp 105-114
-
- Chapter
- Export citation
Path Planning Aware of Robot’s Center of Mass for Steep Slope Vineyards
-
- Article
-
- You have access
- Export citation
References
-
- Book:
- An Invitation to Applied Category Theory
- Published online:
- 05 July 2019
- Print publication:
- 18 July 2019, pp 325-330
-
- Chapter
- Export citation
Appendix - Solutions to Selected Exercises
-
- Book:
- How to Prove It
- Published online:
- 04 July 2019
- Print publication:
- 18 July 2019, pp 397-450
-
- Chapter
- Export citation
1 - Generative Effects: Orders and Galois Connections
-
- Book:
- An Invitation to Applied Category Theory
- Published online:
- 05 July 2019
- Print publication:
- 18 July 2019, pp 1-37
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Lawless
- Published online:
- 22 June 2019
- Print publication:
- 18 July 2019, pp iv-iv
-
- Chapter
- Export citation
2 - Resource Theories: Monoidal Preorders and Enrichment
-
- Book:
- An Invitation to Applied Category Theory
- Published online:
- 05 July 2019
- Print publication:
- 18 July 2019, pp 38-76
-
- Chapter
- Export citation
3 - The Internet’s Abuse Problem
- from Part I - A Lawless Internet
-
- Book:
- Lawless
- Published online:
- 22 June 2019
- Print publication:
- 18 July 2019, pp 25-42
-
- Chapter
- Export citation
Neural morphosyntactic tagging for Rusyn
-
- Journal:
- Natural Language Engineering / Volume 25 / Issue 5 / September 2019
- Published online by Cambridge University Press:
- 18 July 2019, pp. 633-650
-
- Article
- Export citation
5 - Signal Flow Graphs: Props, Presentations, and Proofs
-
- Book:
- An Invitation to Applied Category Theory
- Published online:
- 05 July 2019
- Print publication:
- 18 July 2019, pp 147-179
-
- Chapter
- Export citation
7 - Logic of Behavior: Sheaves, Toposes, and Internal Languages
-
- Book:
- An Invitation to Applied Category Theory
- Published online:
- 05 July 2019
- Print publication:
- 18 July 2019, pp 219-255
-
- Chapter
- Export citation
On the Size-Ramsey Number of Cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 17 July 2019, pp. 871-880
-
- Article
- Export citation
-
For given graphs G1,…, Gk, the size-Ramsey number
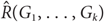 $\hat R({G_1}, \ldots ,{G_k})$ is the smallest integer m for which there exists a graph H on m edges such that in every k-edge colouring of H with colours 1,…,k, H contains a monochromatic copy of Gi of colour i for some 1 ≤ i ≤ k. We denote
$\hat R({G_1}, \ldots ,{G_k})$ is the smallest integer m for which there exists a graph H on m edges such that in every k-edge colouring of H with colours 1,…,k, H contains a monochromatic copy of Gi of colour i for some 1 ≤ i ≤ k. We denote 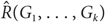 $\hat R({G_1}, \ldots ,{G_k})$ by
$\hat R({G_1}, \ldots ,{G_k})$ by 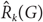 ${\hat R_k}(G)$ when G1 = ⋯ = Gk = G.
${\hat R_k}(G)$ when G1 = ⋯ = Gk = G.Haxell, Kohayakawa and Łuczak showed that the size-Ramsey number of a cycle Cn is linear in n,
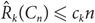 ${\hat R_k}({C_n}) \le {c_k}n$ for some constant ck. Their proof, however, is based on Szemerédi’s regularity lemma so no specific constant ck is known.
${\hat R_k}({C_n}) \le {c_k}n$ for some constant ck. Their proof, however, is based on Szemerédi’s regularity lemma so no specific constant ck is known.In this paper, we give various upper bounds for the size-Ramsey numbers of cycles. We provide an alternative proof of
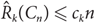 ${\hat R_k}({C_n}) \le {c_k}n$, avoiding use of the regularity lemma, where ck is exponential and doubly exponential in k, when n is even and odd, respectively. In particular, we show that for sufficiently large n we have
${\hat R_k}({C_n}) \le {c_k}n$, avoiding use of the regularity lemma, where ck is exponential and doubly exponential in k, when n is even and odd, respectively. In particular, we show that for sufficiently large n we have 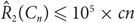 ${\hat R_2}({C_n}) \le {10^5} \times cn$, where c = 6.5 if n is even and c = 1989 otherwise.
${\hat R_2}({C_n}) \le {10^5} \times cn$, where c = 6.5 if n is even and c = 1989 otherwise.
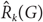
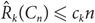
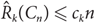
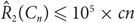
FORMAL REPRESENTATIONS OF DEPENDENCE AND GROUNDEDNESS
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 16 July 2019, pp. 105-140
- Print publication:
- March 2020
-
- Article
- Export citation
Designing a virtual patient dialogue system based on terminology-rich resources: Challenges and evaluation
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 15 July 2019, pp. 183-220
-
- Article
- Export citation
UNIVERSES AND UNIVALENCE IN HOMOTOPY TYPE THEORY
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 15 July 2019, pp. 426-455
- Print publication:
- September 2019
-
- Article
- Export citation
Detecting light verb constructions across languages
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 15 July 2019, pp. 319-348
-
- Article
- Export citation
DYNAMIC GRADED EPISTEMIC LOGIC
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 12 July 2019, pp. 663-684
- Print publication:
- December 2019
-
- Article
- Export citation
EFFECTIVE INSEPARABILITY, LATTICES, AND PREORDERING RELATIONS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 12 July 2019, pp. 838-865
- Print publication:
- December 2021
-
- Article
- Export citation
-
We study effectively inseparable (abbreviated as e.i.) prelattices (i.e., structures of the form
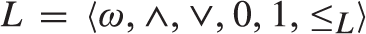 $L = \langle \omega , \wedge , \vee ,0,1,{ \le _L}\rangle$ where ω denotes the set of natural numbers and the following four conditions hold: (1)
$L = \langle \omega , \wedge , \vee ,0,1,{ \le _L}\rangle$ where ω denotes the set of natural numbers and the following four conditions hold: (1) 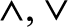 $\wedge , \vee$ are binary computable operations; (2)
$\wedge , \vee$ are binary computable operations; (2) 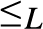 ${ \le _L}$ is a computably enumerable preordering relation, with
${ \le _L}$ is a computably enumerable preordering relation, with 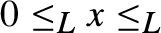 $0{ \le _L}x{ \le _L}1$ for every x; (3) the equivalence relation
$0{ \le _L}x{ \le _L}1$ for every x; (3) the equivalence relation 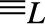 ${ \equiv _L}$ originated by
${ \equiv _L}$ originated by 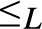 ${ \le _L}$ is a congruence on L such that the corresponding quotient structure is a nontrivial bounded lattice; (4) the
${ \le _L}$ is a congruence on L such that the corresponding quotient structure is a nontrivial bounded lattice; (4) the 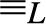 ${ \equiv _L}$-equivalence classes of 0 and 1 form an effectively inseparable pair of sets). Solving a problem in (Montagna & Sorbi, 1985) we show (Theorem 4.2), that if L is an e.i. prelattice then
${ \equiv _L}$-equivalence classes of 0 and 1 form an effectively inseparable pair of sets). Solving a problem in (Montagna & Sorbi, 1985) we show (Theorem 4.2), that if L is an e.i. prelattice then 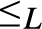 ${ \le _L}$ is universal with respect to all c.e. preordering relations, i.e., for every c.e. preordering relation R there exists a computable function f reducing R to
${ \le _L}$ is universal with respect to all c.e. preordering relations, i.e., for every c.e. preordering relation R there exists a computable function f reducing R to 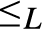 ${ \le _L}$, i.e.,
${ \le _L}$, i.e., 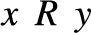 $xRy$ if and only if
$xRy$ if and only if 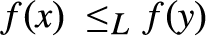 $f\left( x \right){ \le _L}f\left( y \right)$, for all
$f\left( x \right){ \le _L}f\left( y \right)$, for all 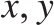 $x,y$. In fact (Corollary 5.3)
$x,y$. In fact (Corollary 5.3)  ${ \le _L}$ is locally universal, i.e., for every pair
${ \le _L}$ is locally universal, i.e., for every pair 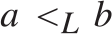 $a{ < _L}b$ and every c.e. preordering relation R one can find a reducing function f from R to
$a{ < _L}b$ and every c.e. preordering relation R one can find a reducing function f from R to  ${ \le _L}$ such that the range of f is contained in the interval
${ \le _L}$ such that the range of f is contained in the interval 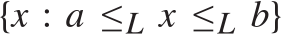 $\left\{ {x:a{ \le _L}x{ \le _L}b} \right\}$. Also (Theorem 5.7)
$\left\{ {x:a{ \le _L}x{ \le _L}b} \right\}$. Also (Theorem 5.7) 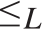 ${ \le _L}$ is uniformly dense, i.e., there exists a computable function f such that for every
${ \le _L}$ is uniformly dense, i.e., there exists a computable function f such that for every 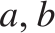 $a,b$ if
$a,b$ if 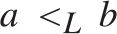 $a{ < _L}b$ then
$a{ < _L}b$ then 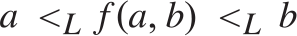 $a{ < _L}f\left( {a,b} \right){ < _L}b$, and if
$a{ < _L}f\left( {a,b} \right){ < _L}b$, and if 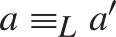 $a{ \equiv _L}a\prime$ and
$a{ \equiv _L}a\prime$ and 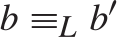 $b{ \equiv _L}b\prime$ then
$b{ \equiv _L}b\prime$ then 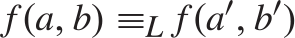 $f\left( {a,b} \right){ \equiv _L}f\left( {a\prime ,b\prime } \right)$. Some consequences and applications of these results are discussed: in particular (Corollary 7.2) for
$f\left( {a,b} \right){ \equiv _L}f\left( {a\prime ,b\prime } \right)$. Some consequences and applications of these results are discussed: in particular (Corollary 7.2) for 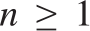 $n \ge 1$ the c.e. preordering relation on
$n \ge 1$ the c.e. preordering relation on 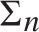 ${{\rm{\Sigma }}_n}$ sentences yielded by the relation of provable implication of any c.e. consistent extension of Robinson’s system R or Q is locally universal and uniformly dense; and (Corollary 7.3) the c.e. preordering relation yielded by provable implication of any c.e. consistent extension of Heyting Arithmetic is locally universal and uniformly dense.
${{\rm{\Sigma }}_n}$ sentences yielded by the relation of provable implication of any c.e. consistent extension of Robinson’s system R or Q is locally universal and uniformly dense; and (Corollary 7.3) the c.e. preordering relation yielded by provable implication of any c.e. consistent extension of Heyting Arithmetic is locally universal and uniformly dense.
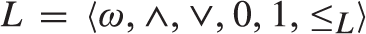
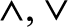
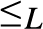
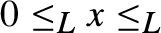
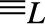
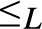
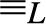
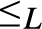
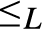
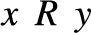
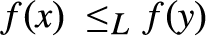
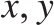

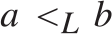

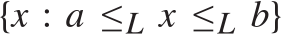
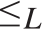
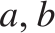
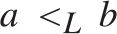
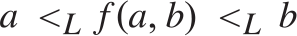
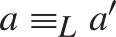
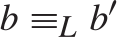
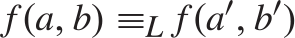
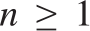
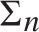
Term evaluation metrics in imbalanced text categorization
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 12 July 2019, pp. 31-47
-
- Article
- Export citation
