Refine search
Actions for selected content:
48285 results in Computer Science
8 - Principal component analysis in high dimensions
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 236-258
-
- Chapter
- Export citation
5 - Metric entropy and its uses
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 121-158
-
- Chapter
- Export citation
Illustrations
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp xv-xvi
-
- Chapter
- Export citation
5 - Availability Attack Case Study: SpamBayes
- from Part II - Causative Attacks on Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 105-133
-
- Chapter
- Export citation
Definability in the local structure of the ω-Turing degrees
-
- Journal:
- Mathematical Structures in Computer Science / Volume 29 / Issue 7 / August 2019
- Published online by Cambridge University Press:
- 21 February 2019, pp. 927-937
-
- Article
- Export citation
-
This article continues the study of the definability in the local substructure
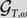 $\mathcal{G}_{T,\omega}$ of the ω-Turing degrees, initiated in (Sariev and Ganchev 2014). We show that the class I of the intermediate degrees is definable in $\mathcal{G}_{T,\omega}$.
$\mathcal{G}_{T,\omega}$ of the ω-Turing degrees, initiated in (Sariev and Ganchev 2014). We show that the class I of the intermediate degrees is definable in $\mathcal{G}_{T,\omega}$.
6 - Integrity Attack Case Study: PCA Detector
- from Part II - Causative Attacks on Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 134-164
-
- Chapter
- Export citation
Part IV - Future Directions in Adversarial Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 239-240
-
- Chapter
- Export citation
4 - Attacking a Hypersphere Learner
- from Part II - Causative Attacks on Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 69-104
-
- Chapter
- Export citation
Part I - Overview of Adversarial Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 1-2
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 1-20
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp xiii-xiv
-
- Chapter
- Export citation
3 - A Framework for Secure Learning
- from Part I - Overview of Adversarial Machine Learning
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 29-66
-
- Chapter
- Export citation
9 - Decomposability and restricted strong convexity
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 259-311
-
- Chapter
- Export citation
15 - Minimax lower bounds
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 485-523
-
- Chapter
- Export citation
References
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 524-539
-
- Chapter
- Export citation
13 - Nonparametric least squares
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 416-452
-
- Chapter
- Export citation
Appendix D: Full Proofs for Near-Optimal Evasion
- from Part V - Appendixes
-
- Book:
- Adversarial Machine Learning
- Published online:
- 14 March 2019
- Print publication:
- 21 February 2019, pp 285-294
-
- Chapter
- Export citation
3 - Concentration of measure
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 58-97
-
- Chapter
- Export citation
Author index
-
- Book:
- High-Dimensional Statistics
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019, pp 548-552
-
- Chapter
- Export citation
