Refine search
Actions for selected content:
48285 results in Computer Science
Using SWISH to Realize Interactive Web-based Tutorials for Logic-based Languages
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 15 February 2019, pp. 229-261
-
- Article
- Export citation
AN ABSTRACT APPROACH TO CONSEQUENCE RELATIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 15 February 2019, pp. 331-371
- Print publication:
- June 2019
-
- Article
- Export citation
SUSZKO’S PROBLEM: MIXED CONSEQUENCE AND COMPOSITIONALITY
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 15 February 2019, pp. 736-767
- Print publication:
- December 2019
-
- Article
- Export citation
Introduction to the TPLP Special Issue on User-oriented Logic Programming and Reasoning Paradigms
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 15 February 2019, pp. 109-113
-
- Article
-
- You have access
- Export citation
MODAL LOGIC WITHOUT CONTRACTION IN A METATHEORY WITHOUT CONTRACTION
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 13 February 2019, pp. 685-701
- Print publication:
- December 2019
-
- Article
- Export citation

High-Dimensional Statistics
- A Non-Asymptotic Viewpoint
-
- Published online:
- 12 February 2019
- Print publication:
- 21 February 2019
PES volume 33 issue 1 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 12 February 2019, pp. b1-b2
-
- Article
-
- You have access
- Export citation
A free-rotating ball-shaped transmitting coil with wireless power transfer system for robot joints
-
- Journal:
- Wireless Power Transfer / Volume 6 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 12 February 2019, pp. 26-40
- Print publication:
- March 2019
-
- Article
- Export citation
PES volume 33 issue 1 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 12 February 2019, pp. f1-f2
-
- Article
-
- You have access
- Export citation
A Simple Method to Solve the Instantaneous Kinematics of the 5-R
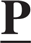 $\underbar{P}$UR Parallel Manipulator
$\underbar{P}$UR Parallel Manipulator
-
- Article
- Export citation
-
In this work a simple method to solve the kinematics of the 5-R
$\underbar{P}$UR parallel manipulator is introduced. Dealing with the displacement analysis, the kinematic constraint equations required to address the forward–inverse displacement analysis are established according to linear combinations of two vectors attached to the moving platform. Then, besides the solution of the inverse displacement analysis two strategies are proposed in order to solve the forward position analysis. Finally, the input–output equations of velocity and acceleration are systematically obtained by resorting to reciprocal-screw theory. Numerical examples are provided with the purpose to illustrate the proposed method. Furthermore, the numerical results obtained by means of screw theory are confirmed with the aid of commercially available software.
Out-domain Chinese new word detection with statistics-based character embedding
-
- Journal:
- Natural Language Engineering / Volume 25 / Issue 2 / March 2019
- Published online by Cambridge University Press:
- 11 February 2019, pp. 239-255
-
- Article
- Export citation
Inlining External Sources in Answer Set Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 19 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 11 February 2019, pp. 360-411
-
- Article
- Export citation
-
hex-programs are an extension of answer set programs (ASP) with external sources. To this end, external atoms provide a bidirectional interface between the program and an external source. The traditional evaluation algorithm for hex-programs is based on guessing truth values of external atoms and verifying them by explicit calls of the external source. The approach was optimized by techniques that reduce the number of necessary verification calls or speed them up, but the remaining external calls are still expensive. In this paper, we present an alternative evaluation approach based on inlining of external atoms, motivated by existing but less general approaches for specialized formalisms such as DL-programs. External atoms are then compiled away such that no verification calls are necessary. The approach is implemented in the dlvhex reasoner. Experiments show a significant performance gain. Besides performance improvements, we further exploit inlining for extending previous (semantic) characterizations of program equivalence from ASP to hex-programs, including those of strong equivalence, uniform equivalence, and
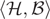 $\langle\mathcal{H},\mathcal{B}\rangle$- equivalence. Finally, based on these equivalence criteria, we characterize also inconsistency of programs w.r.t. extensions. Since well-known ASP extensions (such as constraint ASP) are special cases of hex, the results are interesting beyond the particular formalism.
$\langle\mathcal{H},\mathcal{B}\rangle$- equivalence. Finally, based on these equivalence criteria, we characterize also inconsistency of programs w.r.t. extensions. Since well-known ASP extensions (such as constraint ASP) are special cases of hex, the results are interesting beyond the particular formalism.
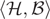
COCHIS: Stable and coherent implicits
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 29 / 2019
- Published online by Cambridge University Press:
- 08 February 2019, e3
-
- Article
-
- You have access
- Export citation
INEQUALITIES FOR THE DEPENDENT GAUSSIAN NOISE CHANNELS BASED ON FISHER INFORMATION AND COPULAS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 07 February 2019, pp. 618-657
-
- Article
- Export citation
Getting Started
-
- Book:
- Doing Better Statistics in Human-Computer Interaction
- Published online:
- 26 January 2019
- Print publication:
- 07 February 2019, pp 1-8
-
- Chapter
- Export citation
11 - A Robust t-Test
- from Part II - How to Use Statistics
-
- Book:
- Doing Better Statistics in Human-Computer Interaction
- Published online:
- 26 January 2019
- Print publication:
- 07 February 2019, pp 125-138
-
- Chapter
- Export citation
Contents
-
- Book:
- Doing Better Statistics in Human-Computer Interaction
- Published online:
- 26 January 2019
- Print publication:
- 07 February 2019, pp vii-x
-
- Chapter
- Export citation
Part II - How to Use Statistics
-
- Book:
- Doing Better Statistics in Human-Computer Interaction
- Published online:
- 26 January 2019
- Print publication:
- 07 February 2019, pp 69-70
-
- Chapter
- Export citation
Dedication
-
- Book:
- Doing Better Statistics in Human-Computer Interaction
- Published online:
- 26 January 2019
- Print publication:
- 07 February 2019, pp v-vi
-
- Chapter
- Export citation
