Refine search
Actions for selected content:
48287 results in Computer Science
LOGICS ABOVE S4 AND THE LEBESGUE MEASURE ALGEBRA
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 28 October 2016, pp. 51-64
- Print publication:
- March 2017
-
- Article
- Export citation
-
We study the measure semantics for propositional modal logics, in which formulas are interpreted in the Lebesgue measure algebra
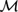 ${\cal M}$ , or algebra of Borel subsets of the real interval [0,1] modulo sets of measure zero. It was shown in Lando (2012) and Fernández-Duque (2010) that the propositional modal logic S4 is complete for the Lebesgue measure algebra. The main result of the present paper is that every logic L aboveS4 is complete for some subalgebra of
${\cal M}$ , or algebra of Borel subsets of the real interval [0,1] modulo sets of measure zero. It was shown in Lando (2012) and Fernández-Duque (2010) that the propositional modal logic S4 is complete for the Lebesgue measure algebra. The main result of the present paper is that every logic L aboveS4 is complete for some subalgebra of 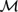 ${\cal M}$ . Indeed, there is a single model over a subalgebra of
${\cal M}$ . Indeed, there is a single model over a subalgebra of 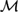 ${\cal M}$ in which all nontheorems of L are refuted. This work builds on recent work by Bezhanishvili, Gabelaia, & Lucero-Bryan (2015) on the topological semantics for logics above S4. In Bezhanishvili et al., (2015), it is shown that there are logics above that are not the logic of any subalgebra of the interior algebra over the real line,
${\cal M}$ in which all nontheorems of L are refuted. This work builds on recent work by Bezhanishvili, Gabelaia, & Lucero-Bryan (2015) on the topological semantics for logics above S4. In Bezhanishvili et al., (2015), it is shown that there are logics above that are not the logic of any subalgebra of the interior algebra over the real line, 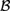 ${\cal B}$ (ℝ), but that every logic above is the logic of some subalgebra of the interior algebra over the rationals,
${\cal B}$ (ℝ), but that every logic above is the logic of some subalgebra of the interior algebra over the rationals, 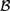 ${\cal B}$ (ℚ), and the interior algebra over Cantor space,
${\cal B}$ (ℚ), and the interior algebra over Cantor space, 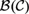 ${\cal B}\left( {\cal C} \right)$ .
${\cal B}\left( {\cal C} \right)$ .
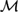
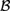
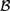
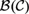
A linear/producer/consumer model of classical linear logic
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 5 / May 2018
- Published online by Cambridge University Press:
- 27 October 2016, pp. 710-735
-
- Article
- Export citation
List of Background Concepts
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp ix-x
-
- Chapter
- Export citation
Part 3 - Effective considerations
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 113-114
-
- Chapter
- Export citation
CHAPTER 10 - HYPERARITHMETIC SETS
- from Part 3 - Effective considerations
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 127-138
-
- Chapter
- Export citation
3 - Bisimulations
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 114-158
-
- Chapter
- Export citation
APPENDIX B - ADMISSIBLILITY
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 163-174
-
- Chapter
- Export citation
APPENDIX A - ℵ1-FREE ABELIAN GROUPS
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 159-162
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp i-iv
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp i-iv
-
- Chapter
- Export citation
Definition and Symbol Index
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 466-468
-
- Chapter
- Export citation
1 - Motivation
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 1-32
-
- Chapter
- Export citation
CHAPTER 11 - EFFECTIVE ASPECTS OF Lω1,ω
- from Part 3 - Effective considerations
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 139-150
-
- Chapter
- Export citation
CHAPTER 2 - BACK AND FORTH
- from Part 1 - Classical results in infinitary model theory
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 15-28
-
- Chapter
- Export citation
6 - Invariants and Assertions
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 334-439
-
- Chapter
- Export citation
7 - Heaps
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 101-113
-
- Chapter
- Export citation
Preface
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp xi-xii
-
- Chapter
- Export citation
Appendix - Solutions to Selected Exercises
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 205-216
-
- Chapter
- Export citation
CHAPTER 3 - THE SPACE OF COUNTABLE MODELS
- from Part 1 - Classical results in infinitary model theory
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 29-38
-
- Chapter
- Export citation
CHAPTER 9 - EFFECTIVE DESCRIPTIVE SET THEORY
- from Part 3 - Effective considerations
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 115-126
-
- Chapter
- Export citation
