Refine search
Actions for selected content:
48287 results in Computer Science
Frontmatter
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp i-iv
-
- Chapter
- Export citation
Dedication
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp v-vi
-
- Chapter
- Export citation
4 - Logic, Lifting and Finality
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 159-245
-
- Chapter
- Export citation
8 - Sets
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 114-126
-
- Chapter
- Export citation
CHAPTER 12 - SPECTRA OF VAUGHT COUNTEREXAMPLES
- from Part 3 - Effective considerations
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 151-158
-
- Chapter
- Export citation
Preface
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp vii-xvi
-
- Chapter
- Export citation
CHAPTER 1 - INFINITARY LANGUAGES
- from Part 1 - Classical results in infinitary model theory
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 7-14
-
- Chapter
- Export citation
INDEX
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 181-183
-
- Chapter
- Export citation
1 - Why Data Structures? A Motivating Example
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 1-13
-
- Chapter
- Export citation
Contents
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp v-viii
-
- Chapter
- Export citation
6 - B-Trees
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 83-100
-
- Chapter
- Export citation
CHAPTER 7 - VAUGHT COUNTEREXAMPLES
- from Part 2 - Building uncountable models
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 83-96
-
- Chapter
- Export citation
10 - Sorting
-
- Book:
- Basic Concepts in Data Structures
- Published online:
- 10 November 2016
- Print publication:
- 27 October 2016, pp 152-177
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Introduction to Coalgebra
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016, pp 469-477
-
- Chapter
- Export citation
CHAPTER 5 - HANF NUMBERS AND INDISCERNIBLES
- from Part 1 - Classical results in infinitary model theory
-
- Book:
- Lectures on Infinitary Model Theory
- Published online:
- 05 August 2016
- Print publication:
- 27 October 2016, pp 51-62
-
- Chapter
- Export citation
REPRESENTING CONJUNCTIVE DEDUCTIONS BY DISJUNCTIVE DEDUCTIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 25 October 2016, pp. 145-157
- Print publication:
- March 2017
-
- Article
- Export citation
-
A skeleton of the category with finite coproducts
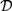 ${\cal D}$ freely generated by a single object has a subcategory isomorphic to a skeleton of the category with finite products
${\cal D}$ freely generated by a single object has a subcategory isomorphic to a skeleton of the category with finite products 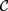 ${\cal C}$ freely generated by a countable set of objects. As a consequence, we obtain that
${\cal C}$ freely generated by a countable set of objects. As a consequence, we obtain that 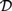 ${\cal D}$ has a subcategory equivalent with
${\cal D}$ has a subcategory equivalent with 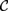 ${\cal C}$ . From a proof-theoretical point of view, this means that up to some identifications of formulae the deductions of pure conjunctive logic with a countable set of propositional letters can be represented by deductions in pure disjunctive logic with just one propositional letter. By taking opposite categories, one can replace coproduct by product, i.e., disjunction by conjunction, and the other way round, to obtain the dual results.
${\cal C}$ . From a proof-theoretical point of view, this means that up to some identifications of formulae the deductions of pure conjunctive logic with a countable set of propositional letters can be represented by deductions in pure disjunctive logic with just one propositional letter. By taking opposite categories, one can replace coproduct by product, i.e., disjunction by conjunction, and the other way round, to obtain the dual results.
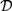
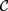
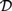
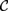
Gencel: a program generator for correct spreadsheets
-
- Journal:
- Journal of Functional Programming / Volume 16 / Issue 3 / May 2006
- Published online by Cambridge University Press:
- 25 October 2016, pp. 293-325
-
- Article
-
- You have access
- Export citation
EDUCATIONAL PEARL: Automata via macros
-
- Journal:
- Journal of Functional Programming / Volume 16 / Issue 3 / May 2006
- Published online by Cambridge University Press:
- 25 October 2016, pp. 253-267
-
- Article
-
- You have access
- Export citation
Consistency of the theory of contexts
-
- Journal:
- Journal of Functional Programming / Volume 16 / Issue 3 / May 2006
- Published online by Cambridge University Press:
- 25 October 2016, pp. 327-372
-
- Article
-
- You have access
- Export citation
