Refine search
Actions for selected content:
48287 results in Computer Science
Precise complexity guarantees for pointer analysis via Datalog with extensions*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 916-932
-
- Article
- Export citation
Stable models for infinitary formulas with extensional atoms
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 771-786
-
- Article
- Export citation
Assertion-based analysis via slicing with ABETS * (system description)
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 515-532
-
- Article
- Export citation
Stable-unstable semantics: Beyond NP with normal logic programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 570-586
-
- Article
-
- You have access
- Export citation
A general framework for static profiling of parametric resource usage*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 849-865
-
- Article
- Export citation
Autostability spectra for decidable structures
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 3 / March 2018
- Published online by Cambridge University Press:
- 14 October 2016, pp. 392-411
-
- Article
- Export citation
-
We study autostability spectra relative to strong constructivizations (SC-autostability spectra). For a decidable structure
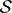 $\mathcal{S}$ , the SC-autostability spectrum of $\mathcal{S}$ is the set of all Turing degrees capable of computing isomorphisms among arbitrary decidable copies of $\mathcal{S}$ . The degree of SC-autostability for $\mathcal{S}$ is the least degree in the spectrum (if such a degree exists).
$\mathcal{S}$ , the SC-autostability spectrum of $\mathcal{S}$ is the set of all Turing degrees capable of computing isomorphisms among arbitrary decidable copies of $\mathcal{S}$ . The degree of SC-autostability for $\mathcal{S}$ is the least degree in the spectrum (if such a degree exists).We prove that for a computable successor ordinal α, every Turing degree c.e. in and above 0 (α) is the degree of SC-autostability for some decidable structure. We show that for an infinite computable ordinal β, every Turing degree c.e. in and above 0 (2β+1) is the degree of SC-autostability for some discrete linear order. We prove that the set of all PA-degrees is an SC-autostability spectrum. We also obtain similar results for autostability spectra relative to n-constructivizations.
Proving infinitary formulas
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 787-799
-
- Article
- Export citation
Online learning of event definitions
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 817-833
-
- Article
- Export citation
Justifications for programs with disjunctive and causal-choice rules*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 587-603
-
- Article
- Export citation
Introduction to the 32nd International Conference on Logic Programming Special Issue
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 509-514
-
- Article
- Export citation
Tabling with Sound Answer Subsumption
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 933-949
-
- Article
- Export citation
On local domain symmetry for model expansion
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 636-652
-
- Article
- Export citation
Lock-free atom garbage collection for multithreaded Prolog
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 950-965
-
- Article
- Export citation
Paraconsistency and word puzzles
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 703-720
-
- Article
- Export citation
Semantic code browsing*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 721-737
-
- Article
- Export citation
The power of non-ground rules in Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 552-569
-
- Article
- Export citation
ASP for minimal entailment in a rational extension of SROEL
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 738-754
-
- Article
- Export citation
Query answering in resource-based answer set semantics*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 619-635
-
- Article
- Export citation
TLP volume 16 issue 5-6 Cover and Back matter
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. b1-b3
-
- Article
-
- You have access
- Export citation
Efficient algebraic effect handlers for Prolog
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 884-898
-
- Article
- Export citation
