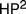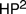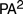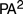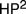Refine search
Actions for selected content:
48287 results in Computer Science
Bibliography
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 1002-1002
-
- Chapter
- Export citation
1 - Introduction
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 3-22
-
- Chapter
- Export citation
2 - Fundamentals
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 23-70
-
- Chapter
- Export citation
Contents
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp v-x
-
- Chapter
- Export citation
7 - Functions
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 299-370
-
- Chapter
- Export citation
9 - Structures and Unions
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 445-496
-
- Chapter
- Export citation
Preface
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp xi-xii
-
- Chapter
- Export citation
16 - Templates in C++
- from PART-II - Object Oriented Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 928-968
-
- Chapter
- Export citation
11 - Classes and Objects
- from PART-II - Object Oriented Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 533-651
-
- Chapter
- Export citation
13 - Operator Overloading
- from PART-II - Object Oriented Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 699-769
-
- Chapter
- Export citation
4 - Decision Making Control Statements
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 110-145
-
- Chapter
- Export citation
3 - Operators and Type Casting
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 71-109
-
- Chapter
- Export citation
Software Development Life Cycle
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 999-1001
-
- Chapter
- Export citation
8 - Pointers
- from PART-I - Structured Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 371-444
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp xiii-xiv
-
- Chapter
- Export citation
12 - Constructors and Destructors
- from PART-II - Object Oriented Programming
-
- Book:
- Computer Programming with C++
- Published online:
- 28 May 2018
- Print publication:
- 18 October 2016, pp 652-698
-
- Chapter
- Export citation
TRIAL AND ERROR MATHEMATICS II: DIALECTICAL SETS AND QUASIDIALECTICAL SETS, THEIR DEGREES, AND THEIR DISTRIBUTION WITHIN THE CLASS OF LIMIT SETS
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 4 / December 2016
- Published online by Cambridge University Press:
- 17 October 2016, pp. 810-835
- Print publication:
- December 2016
-
- Article
- Export citation
-
This paper is a continuation of Amidei, Pianigiani, San Mauro, Simi, & Sorbi (2016), where we have introduced the quasidialectical systems, which are abstract deductive systems designed to provide, in line with Lakatos’ views, a formalization of trial and error mathematics more adherent to the real mathematical practice of revision than Magari’s original dialectical systems. In this paper we prove that the two models of deductive systems (dialectical systems and quasidialectical systems) have in some sense the same information content, in that they represent two classes of sets (the dialectical sets and the quasidialectical sets, respectively), which have the same Turing degrees (namely, the computably enumerable Turing degrees), and the same enumeration degrees (namely, the
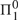 ${\rm{\Pi }}_1^0$ enumeration degrees). Nonetheless, dialectical sets and quasidialectical sets do not coincide. Even restricting our attention to the so-called loopless quasidialectical sets, we show that the quasidialectical sets properly extend the dialectical sets. As both classes consist of
${\rm{\Pi }}_1^0$ enumeration degrees). Nonetheless, dialectical sets and quasidialectical sets do not coincide. Even restricting our attention to the so-called loopless quasidialectical sets, we show that the quasidialectical sets properly extend the dialectical sets. As both classes consist of 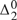 ${\rm{\Delta }}_2^0$ sets, the extent to which the two classes differ is conveniently measured using the Ershov hierarchy: indeed, the dialectical sets are ω-computably enumerable (close inspection also shows that there are dialectical sets which do not lie in any finite level; and in every finite level n ≥ 2 of the Ershov hierarchy there is a dialectical set which does not lie in the previous level); on the other hand, the quasidialectical sets spread out throughout all classes of the hierarchy (close inspection shows that for every ordinal notation a of a nonzero computable ordinal, there is a quasidialectical set lying in
${\rm{\Delta }}_2^0$ sets, the extent to which the two classes differ is conveniently measured using the Ershov hierarchy: indeed, the dialectical sets are ω-computably enumerable (close inspection also shows that there are dialectical sets which do not lie in any finite level; and in every finite level n ≥ 2 of the Ershov hierarchy there is a dialectical set which does not lie in the previous level); on the other hand, the quasidialectical sets spread out throughout all classes of the hierarchy (close inspection shows that for every ordinal notation a of a nonzero computable ordinal, there is a quasidialectical set lying in 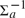 ${\rm{\Sigma }}_a^{ - 1}$ , but in none of the preceding levels).
${\rm{\Sigma }}_a^{ - 1}$ , but in none of the preceding levels).
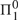
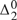
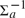
IBN SĪNĀ ON REDUCTIO AD ABSURDUM
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 17 October 2016, pp. 583-601
- Print publication:
- September 2017
-
- Article
- Export citation
GENERALIZING BOOLOS’ THEOREM
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 17 October 2016, pp. 80-91
- Print publication:
- March 2017
-
- Article
- Export citation
-
It’s well known that it’s possible to extract, from Frege’s Grudgesetze, an interpretation of second-order Peano Arithmetic in the theory
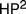 $H{P^2}$ , whose sole axiom is Hume’s principle. What’s less well known is that, in Die Grundlagen Der Arithmetic §82–83 Boolos (2011), George Boolos provided a converse interpretation of
$H{P^2}$ , whose sole axiom is Hume’s principle. What’s less well known is that, in Die Grundlagen Der Arithmetic §82–83 Boolos (2011), George Boolos provided a converse interpretation of 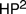 $H{P^2}$ in
$H{P^2}$ in 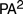 $P{A^2}$ . Boolos’ interpretation can be used to show that the Frege’s construction allows for any model of
$P{A^2}$ . Boolos’ interpretation can be used to show that the Frege’s construction allows for any model of 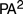 $P{A^2}$ to be recovered from some model of
$P{A^2}$ to be recovered from some model of 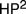 $H{P^2}$ . So the space of possible arithmetical universes is precisely characterized by Hume’s principle.
$H{P^2}$ . So the space of possible arithmetical universes is precisely characterized by Hume’s principle.In this paper, I show that a large class of second-order theories admit characterization by an abstraction principle in this sense. The proof makes use of structural abstraction principles, a class of abstraction principles of considerable intrinsic interest, and categories of interpretations in the sense of Visser (2003).