Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
Non-linear boundary value problems on the semi-infinite interval: an upper and lower solution approach
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 129-140
- Print publication:
- June 2002
-
- Article
- Export citation
Characterizations of a two dimensional Euclidean ring among near-rings
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 59-64
- Print publication:
- June 2002
-
- Article
- Export citation
The longest segment in the complement of a packing
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 45-49
- Print publication:
- June 2002
-
- Article
- Export citation
The universal quaternary quadratic form with the maximal discriminant
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 197-199
- Print publication:
- June 2002
-
- Article
- Export citation
On minimal pairs and residually transcendental extensions of valuations
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 93-106
- Print publication:
- June 2002
-
- Article
- Export citation
-
In this paper, further insight is obtained into the earlier approach of studying residually transcendental extensions of a valuation v of a field K to a simple transcendental extension K(x) of K by means of minimal pairs, thereby introducing new invariants corresponding to any element of an algebraic closure
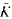 of K. It is also shown that these invariants are of independent interest as well. A characterization of those elements a belonging to is given such that there exists a minimal pair (a, δ) for some δ in the divisible closure of the value group of v.
of K. It is also shown that these invariants are of independent interest as well. A characterization of those elements a belonging to is given such that there exists a minimal pair (a, δ) for some δ in the divisible closure of the value group of v.
 of
of Irreducible and end type group actions on Λ-trees
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 65-70
- Print publication:
- June 2002
-
- Article
- Export citation
On integers which are not differences of two powers
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 231-243
- Print publication:
- June 2002
-
- Article
- Export citation
-
Erdős (see [4]) asked if there are infinitely many integers k which are not a difference or a sum of two powers, i.e., if there are infinitely many positive integers k with k≠|um ± vn| for u, v, m, n ε ℤ. This is certainly a very difficult problem. For example, it is known that the Catalan equation, i.e., the equation um − vn = 1 with uv≠0 and min (m, n)≥2 has only finitely many solutions (u, v, m, n), but there is no other positive integer k≥1 for which it is known that the equation

has only finitely many solution (u, v, m, n) with min (m, n)≥2.

Multiplicities of eigenvalues of a vector-valued Sturm-Liouville problem
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 119-127
- Print publication:
- June 2002
-
- Article
- Export citation
Hilbert function and fractional powers
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 71-75
- Print publication:
- June 2002
-
- Article
- Export citation
On the representation of an integer as the sum of a large and a small square
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 245-251
- Print publication:
- June 2002
-
- Article
- Export citation
-
We continue our study of the different representations of an integer n as a sum of two squares initiated in our final paper written with Paul Erdős [1]. We let r(n) denote the number of representations n = a2 + b2 counted in the usual way, that is, with regard to both the order and sign of a and b. We have
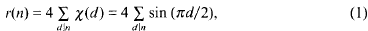
where x is the non-principal Dirichlet character (mod 4); moreover, r(n)≥0 if and only if n has no prime factor p ≡ 3 (mod 4) with odd exponent. We define the function b(n) on the sequence of representable numbers as the least possible value of |b|—for example, we have b(13) = 2,b(25) = 0, b(65) = 1—and we write

here and throughout the paper the star denotes that the sum is restricted to the representable integers. The problem considered here is to find an asymptotic formula for this sum, or, less ambitiously, to determine the order of magnitude of the function B(x).
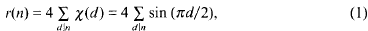

Index to Volume 49
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, p. 263
- Print publication:
- June 2002
-
- Article
- Export citation
Rational homology of spaces of complex monic polynomials with multiple roots
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 77-91
- Print publication:
- June 2002
-
- Article
- Export citation
An analogue of Van der Corput's A5-process for exponential sums
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 167-183
- Print publication:
- June 2002
-
- Article
- Export citation
-
A diophantine system is studied from which is deduced an analogue of van der Corput's A5-process in order to bound analytic exponential sums of the form
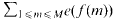 . The saving has now to be taken to the exponent 1/20 instead of 1/32. Our main application is a “ninth derivative test” for exponential sums which is essential for giving new exponent pairs in [3].
. The saving has now to be taken to the exponent 1/20 instead of 1/32. Our main application is a “ninth derivative test” for exponential sums which is essential for giving new exponent pairs in [3].
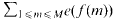 . The saving has now to be taken to the exponent 1/20 instead of 1/32. Our main application is a “ninth derivative test” for exponential sums which is essential for giving new exponent pairs in [3].
. The saving has now to be taken to the exponent 1/20 instead of 1/32. Our main application is a “ninth derivative test” for exponential sums which is essential for giving new exponent pairs in [3].Small positive values of indefinite ternary forms
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 185-196
- Print publication:
- June 2002
-
- Article
- Export citation
-
For an indefinite quadratic form f(x1,…,xn) of discriminant d. let P(f) denote the greatest lower bound of the positive values assumed by f for integers x1, …, xn. This paper investigates the values of P3/|d| for nonzero ternary forms of signature −1, and finds the only remaining class of forms with
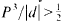 .
.
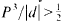 .
.The Hooley–Huxley contour method, for problems in number fields II: factorization and divisibility
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 201-225
- Print publication:
- June 2002
-
- Article
- Export citation
-
Let L be a Galois extension of the number field K. Set n = nK = deg K/ℚ, nL = deg L/ℚ and nL/K = deg L/K. Let I = IL/K denote the group of fractional ideals of K whose prime decomposition contains no prime ideals that ramify in L, and let P = {(α)ΣI: αΣK*, α>0}. Following Hecke [9}, let (λ1, λ2, …, λn − 1) be a basis for the torsion-free characters on P that satisfy λi(α) = 1 (1≤i≤n − 1) for all units α>0 in
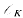 , the ring of integers of K. Fixing an extension of each λi to a character on I, then λi,(α) (1 ≤i≤n − 1) are defined for all ideals α of K that do not ramify in L. So, for such ideals, we can define
, the ring of integers of K. Fixing an extension of each λi to a character on I, then λi,(α) (1 ≤i≤n − 1) are defined for all ideals α of K that do not ramify in L. So, for such ideals, we can define 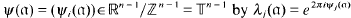 . Then the small region of K referred to above is
. Then the small region of K referred to above is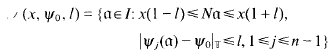
for 0<l<½ and
with the notation that, for any α ∈ ℝ, we set 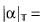 β. where β is the unique real satisyfing
β. where β is the unique real satisyfing 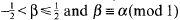 .
.
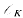 , the ring of integers of
, the ring of integers of 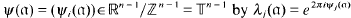 . Then the small region of
. Then the small region of 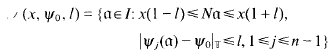
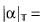 β. where β is the unique real satisyfing
β. where β is the unique real satisyfing 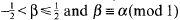 .
.Local inversion for differentiable functions and the Darboux property
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 141-158
- Print publication:
- June 2002
-
- Article
- Export citation
-
The main goal of this paper is to prove that the classical theorem of local inversion for
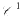 functions extends in finite dimension to everywhere differentiable functions. As usual, a theorem of implicit functions can be deduced from this “Local Inversion Theorem”. The deepest part of the local inversion theorem consists of showing that a differentiable function with non-vanishing Jacobian determinant is locally one-to-one. In turn, this fact allows one to extend the Darboux property of derivative functions on ℝ (the range of the derivative is an interval) to the Jacobian function Df of a differentiable function, under the condition that this Jacobian function does not vanish. It is also proved that these results are no longer true in infinite dimension. These results should be known in whole or part, but references to a complete proof could not be found.
functions extends in finite dimension to everywhere differentiable functions. As usual, a theorem of implicit functions can be deduced from this “Local Inversion Theorem”. The deepest part of the local inversion theorem consists of showing that a differentiable function with non-vanishing Jacobian determinant is locally one-to-one. In turn, this fact allows one to extend the Darboux property of derivative functions on ℝ (the range of the derivative is an interval) to the Jacobian function Df of a differentiable function, under the condition that this Jacobian function does not vanish. It is also proved that these results are no longer true in infinite dimension. These results should be known in whole or part, but references to a complete proof could not be found.
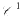 functions extends in finite dimension to everywhere differentiable functions. As usual, a theorem of implicit functions can be deduced from this “Local Inversion Theorem”. The deepest part of the local inversion theorem consists of showing that a differentiable function with non-vanishing Jacobian determinant is locally one-to-one. In turn, this fact allows one to extend the Darboux property of derivative functions on ℝ (the range of the derivative is an interval) to the Jacobian function
functions extends in finite dimension to everywhere differentiable functions. As usual, a theorem of implicit functions can be deduced from this “Local Inversion Theorem”. The deepest part of the local inversion theorem consists of showing that a differentiable function with non-vanishing Jacobian determinant is locally one-to-one. In turn, this fact allows one to extend the Darboux property of derivative functions on ℝ (the range of the derivative is an interval) to the Jacobian function Lipschitz quotient mappings with good ratio of constants
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 159-165
- Print publication:
- June 2002
-
- Article
- Export citation
MTK volume 49 issue 1-2 Cover and Front matter
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. f1-f4
- Print publication:
- June 2002
-
- Article
-
- You have access
- Export citation
On shifted products which are powers
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 227-230
- Print publication:
- June 2002
-
- Article
- Export citation
Uniqueness theorems for convex bodies in non-Euclidean spaces
- Part of
-
- Journal:
- Mathematika / Volume 49 / Issue 1-2 / June 2002
- Published online by Cambridge University Press:
- 26 February 2010, pp. 13-31
- Print publication:
- June 2002
-
- Article
- Export citation
