Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
Some explicit continued fraction expansions
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 1-9
- Print publication:
- June 1991
-
- Article
- Export citation
On the number of integral ideals of given norm and ray-class
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 185-190
- Print publication:
- June 1991
-
- Article
- Export citation
-
Let K be an algebraic number field, [K: Q] = κ є N; only the case κ > 1 is of interest in this paper. Let f be any non-zero ideal in ZK, the ring of integers of K, and let b be any ray-class (modx f) of K. In this paper we answer a question of P. Erdös (private communication) about the “maximum-growth-rate” of the functions
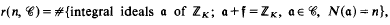
and
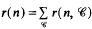
the sum here taken over all ray-classes (modx f), while N(a) is the absolute norm of a. Let
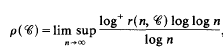
and
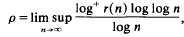
where, as usual, for x є R, log+ x - log max {1, x}. We prove
THEOREM 1. For every f, b we have
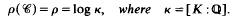
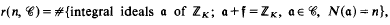
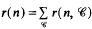
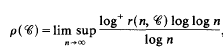
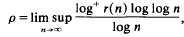
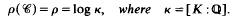
Distributions de signes
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 50-62
- Print publication:
- June 1991
-
- Article
- Export citation
Irreducible convex sets
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 134-155
- Print publication:
- June 1991
-
- Article
- Export citation
On the space of continuous functions on a dyadic set
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 42-49
- Print publication:
- June 1991
-
- Article
- Export citation
Slice discrepancy and irregularities of distribution on spheres
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 105-116
- Print publication:
- June 1991
-
- Article
- Export citation
The rotation of two circular cylinders in a viscous fluid
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 63-66
- Print publication:
- June 1991
-
- Article
- Export citation
A note on lattices of rational functions
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 10-13
- Print publication:
- June 1991
-
- Article
- Export citation
-
One may perhaps doubt whether in the geometry of numbers any particular family of lattices deserves such an attention as, for example, BCH codes receive in coding theory. However, only recently a quite interesting family has emerged. The general case of these lattices considered by Rosenbloom and Tsfasman [5, Section 2] parallels Goppa's construction of codes from algebraic curves. Here we shall take a closer look at the case of genus zero where some special features of Goppa's early codes will show up again: There is a lattice Λ (L, g) in n-dimensional euclidean space associated with a subset L of the field
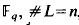 , and a polynomial g satisfying g(є) ≠ for all λ є L. For g = zd previously known sphere packings are recovered and generalized. A nonconstructive argument shows that for n → ∞ and some irreducible polynomials g Minkowski's lower packing bound is met (this being not achieved in [5] where q is fixed, but the genus grows; cf. also [4]).
, and a polynomial g satisfying g(є) ≠ for all λ є L. For g = zd previously known sphere packings are recovered and generalized. A nonconstructive argument shows that for n → ∞ and some irreducible polynomials g Minkowski's lower packing bound is met (this being not achieved in [5] where q is fixed, but the genus grows; cf. also [4]).
 ,
, Completely right pure monoids: the general case
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 77-88
- Print publication:
- June 1991
-
- Article
- Export citation
-
A right S-system over a monoid S is a set A on which S acts unitarily on the right. That is, there is a function
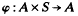 A such that (φ,1)φ and (a, st)φ = ((a, s) t)φ for all a є A and for all s, t є S. We shall refer to right S-systems simply as S-systems. It is clear what is meant by S-homomorphism, S-subsystem etc.; further details of the terms used in this Introduction are given in Section 2.
A such that (φ,1)φ and (a, st)φ = ((a, s) t)φ for all a є A and for all s, t є S. We shall refer to right S-systems simply as S-systems. It is clear what is meant by S-homomorphism, S-subsystem etc.; further details of the terms used in this Introduction are given in Section 2.
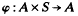 A such that (φ,1)φ and (a, st)φ = ((a, s) t)φ for all a є A and for all s, t є S. We shall refer to right
A such that (φ,1)φ and (a, st)φ = ((a, s) t)φ for all a є A and for all s, t є S. We shall refer to right Some infinite families of satellite knots with given Alexander polynomial
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 156-169
- Print publication:
- June 1991
-
- Article
- Export citation
-
For satellite knots there is a well-known formula which relates the Alexander polynomial of the satellite to those of a companion knot and the corresponding pattern. If &s, &C and &P are the Alexander polynomials of a satellite, companion and pattern respectively then
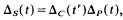
where
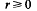 is the linking number of P with a meridian of the companion torus (see [BZ], p. 118). Analogous relationships do not exist for other knot polynomials [MS]. This suggests that the existence of the above formula depends more on the geometry underlying the polynomial than on the geometry of the satellite construction.
is the linking number of P with a meridian of the companion torus (see [BZ], p. 118). Analogous relationships do not exist for other knot polynomials [MS]. This suggests that the existence of the above formula depends more on the geometry underlying the polynomial than on the geometry of the satellite construction.
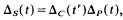
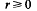 is the linking number of
is the linking number of Wave-source expansions for water of infinite depth in the presence of surface tension
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 67-76
- Print publication:
- June 1991
-
- Article
- Export citation
A note on asymmetric approximation
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 34-41
- Print publication:
- June 1991
-
- Article
- Export citation
J. Adamek, H. Herrlich and G. Strecker. Abstract and Concrete Categories. Wiley. 1990, 482 pp., £43–65. - A. D. Alexandrov and Y. G. Reshetnyak. General Theory of Irregular Curves. Kluwer Academic. 1989, 288 pp., £66. - V. I. Arnold. Huygens and Barrow, Newton and Hooke: Pioneers in Mathematical Analysis and Catastrophe Theory from Evolvents to Quasicrystals. Birkhäuser. 1990, 118 pp., Swiss Franks 24. - A. C. Baker and H. L. Porteous. Linea Algebra and Differential Equations. Ellis Horwood. 1990, 390 pp., £19-95. - G. Burns and A. M. Glazer. Space Groups for Solid State Scientists. 2nd Edition. Academic Press. 1990, 343 pp., $39.95. - A. Chakrabarti. Elements of Ordinary Differential Equations and Special Functions. Wiley. 1990, 148 pp., £24-50. - L. de Branges, I. Gohberg and J. Rovnyak. SeeI. Gohberg. - L. Debnath and P. Mikusinski. Introduction to Hilbert Spaces with Applications. Academic Press. 1990, 509 pp., $49.95. - M. Dozzi. Stochastic Processes with a Multidimensional Parameter. Longman. 1989, 198 pp., £15-50. - R. Durrett. Probability: Theory and Examples. Wadsworth … Brooks/Cole. 1991, 449 pp., £36. - G. Eason and R. W. Ogden. Editors. Elasticity: Mathematical Methods and Applications. Ellis Horwood. 1990, 412 pp., £60. - R. A. Fisher. Statistical Methods, Experimental Design and Scientific Inference. Oxford University Press. 1990, 800 pp., £25. - A. T. Fomenko. The Plateau Problem: Part I Historical survey; Part II The Present State of the Theory. Two volumes. Gordon and Breach. 1990, 220 pp. and 251 pp., $245 for the set. - D. H. Fowler. The Mathematics of Plato's Academy: A New Reconstruction. Clarendon Press. 1991, 401 pp., paper-back £20. - P. B. Garrett. Holomorphic Hilbert Modular Forms. Wadsworth and Brooks/Cole. 1989, 304 pp., £37-50. - R. P. Gilbert and H. C. Howard. Ordinary and Differential Equations with Applications. Ellis Horwood. 1990, 613 pp., £45. - I. Gohberg. Editor. Extension and Interpolation of Linear Operators. Operator Theory: Advances and Applications, Vol. 47. Birkhauser. 1990, 305 pp., Swiss Franks 88. - L. De Branges, I. Gohberg and J. Rovnyak. Editors. Topics in Operator Theory. Operator Theory: Advances and Applications, Vol. 48. Birkhauser. 1990, 448 pp., Swiss Franks 118. - J. R. Hanna and J. H. Rowland. Fourier Series, Transforms and Boundary Value Problems. 2nd Edition. Wiley. 1990, 354 pp., £43. - N. Hartsfield and G. Ringel. Pearls in Graph Theory: A Comprehensive Introduction. Academic Press. 1990, 246 pp., $29.95. - R. F. Hoskins. Standard and Non-Standard Analysis. Ellis Horwood. 1990, 269 pp., £39-95. - I. D. Huntley and D. J. G. James. Editors. Mathematical Modelling. A Source Book of Case Studies. Oxford University Press. 1990, 462 pp., £37-50. - G. Iooss and D. D. Joseph. Elementary Stability and Bifurcation Theory. 2nd edition. Springer. 1989, 324 pp., DM 108. - J. Lutzen. Joseph Liouville, 1809-1882; Master of Pure and Applied Mathematics. Springer. 1990, 884 pp., £81-50. - R. E. Mickens. Difference Equations: Theory and Applications. 2nd edition. Van Nostrand … Reinhold. 1990, 448 pp., £28-50. - G. J. Murphy. C-Algebras and Operator Theory. Academic Press. 1990, 286 pp., $44.50. - A. L. Onishchik and E. B. Vinberg. Lie Groups and Algebraic Groups. Springer, 1990, 328 pp., DM 128. - H. A. Priestley. Introduction to Complex Analysis. Revised Edition. Clarendon Press. 1990, 214 pp., £12-95. - J. T. Sandefur. Discrete Dynamical Systems, Theory and Applications. Clarendon Press. 1990, 445 pp., £16-50. - S. R. Simanca. Pseudo-Differential Operators. Pitman Research Notes in Mathematics No. 236. Longman. 1990, 123 pp., £14. - B. D. Sleeman and R. J. Jarvis. Editors. Ordinary and Partial Differential Equations. Volume II. Longman. 1989, 227 pp., £20. - J. C. Strikwerda. Finite difference schemes and partial differential equations. Wads worth … Brooks/Cole. 1989, 386 pp., £36. - K. Subrahmaniam. A Primer in Probability. Second Edition. Marcel Dekker. 1990, 336 pp., $45. - M. Toda. Non-linear waves and solitons. Kluwer Academic. 1989, 371 pp., £86. - Xiang-qun Yang. The construction theory of denumerable Markov processes. Wiley. 1990, 395 pp., £45.
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 07 April 2017, pp. 194-201
- Print publication:
- June 1991
-
- Article
- Export citation
Centrally symmetric convex bodies and Radon transforms on higher order Grassmannians
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 117-133
- Print publication:
- June 1991
-
- Article
- Export citation
On the distribution of apk modulo one
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 170-184
- Print publication:
- June 1991
-
- Article
- Export citation
On some applications of formulae of Ramanujan in the analysis of algorithms
- Part of
-
- Journal:
- Mathematika / Volume 38 / Issue 1 / June 1991
- Published online by Cambridge University Press:
- 26 February 2010, pp. 14-33
- Print publication:
- June 1991
-
- Article
- Export citation
Index
-
- Book:
- Probabilistic Causality
- Published online:
- 07 October 2009
- Print publication:
- 29 March 1991, pp 411-413
-
- Chapter
- Export citation
Appendix 1 - Logic
-
- Book:
- Probabilistic Causality
- Published online:
- 07 October 2009
- Print publication:
- 29 March 1991, pp 393-398
-
- Chapter
- Export citation
Chapter 2 - Spurious correlation and probability increase
-
- Book:
- Probabilistic Causality
- Published online:
- 07 October 2009
- Print publication:
- 29 March 1991, pp 56-126
-
- Chapter
- Export citation
Chapter 3 - Causal interaction and probability increase
-
- Book:
- Probabilistic Causality
- Published online:
- 07 October 2009
- Print publication:
- 29 March 1991, pp 127-168
-
- Chapter
- Export citation
