Refine search
Actions for selected content:
52669 results in Statistics and Probability
Evolutionary and genomic analysis of four SARS-CoV-2 isolates circulating in March 2020 in Sri Lanka; Additional evidence on multiple introduction and further transmission
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 16 March 2021, e78
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association between live childhood vaccines and COVID-19 outcomes: a national-level analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 16 March 2021, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RUIN PROBABILITIES FOR A MULTIDIMENSIONAL RISK MODEL WITH NON-STATIONARY ARRIVALS AND SUBEXPONENTIAL CLAIMS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 16 March 2021, pp. 799-811
-
- Article
- Export citation
Tree-based models for variable annuity valuation: parameter tuning and empirical analysis
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 16 March 2021, pp. 95-118
-
- Article
- Export citation
ON DEGRADATION-BASED REMAINING LIFETIME
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 16 March 2021, pp. 812-823
-
- Article
- Export citation
Risk factors for rabid animal bites: a study in domestic ruminants in Mymensingh district, Bangladesh
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 15 March 2021, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Variational assimilation of web camera-derived estimates of visibility for Alaska aviation
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 15 March 2021, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Valuation of long-term care options embedded in life annuities
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 15 March 2021, pp. 68-94
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of the early COVID-19 epidemic curve in Germany by regression models with change points
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 11 March 2021, e68
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PRICING LONGEVITY-LINKED SECURITIES IN THE PRESENCE OF MORTALITY TREND CHANGES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 10 March 2021, pp. 411-447
- Print publication:
- May 2021
-
- Article
-
- You have access
- Open access
- Export citation
The roles actors play in policy networks: Central positions in strongly institutionalized fields
-
- Journal:
- Network Science / Volume 9 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 10 March 2021, pp. 213-235
-
- Article
- Export citation
A proof of a conjecture of Gyárfás, Lehel, Sárközy and Schelp on Berge-cycles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 5 / September 2021
- Published online by Cambridge University Press:
- 09 March 2021, pp. 654-669
-
- Article
- Export citation
-
It has been conjectured that, for any fixed
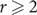 \[{\text{r}} \geqslant 2\] and sufficiently large n, there is a monochromatic Hamiltonian Berge-cycle in every
\[{\text{r}} \geqslant 2\] and sufficiently large n, there is a monochromatic Hamiltonian Berge-cycle in every 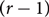 \[({\text{r}} - 1)\]-colouring of the edges of
\[({\text{r}} - 1)\]-colouring of the edges of 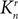 \[{\text{K}}_{\text{n}}^{\text{r}}\], the complete r-uniform hypergraph on n vertices. In this paper we prove this conjecture.
\[{\text{K}}_{\text{n}}^{\text{r}}\], the complete r-uniform hypergraph on n vertices. In this paper we prove this conjecture.
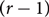
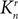
Automatic analysis of insurance reports through deep neural networks to identify severe claims
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 09 March 2021, pp. 42-67
-
- Article
- Export citation
Evaluation of equity-linked products in the presence of policyholder surrender option using risk-control strategies
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 08 March 2021, pp. 25-41
-
- Article
- Export citation
The spatio-temporal distribution of COVID-19 infection in England between January and June 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 March 2021, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Presence of SARS-CoV-2 RNA on playground surfaces and water fountains
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 March 2021, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
KOLMOGOROV BOUNDS FOR THE NORMAL APPROXIMATION OF THE NUMBER OF TRIANGLES IN THE ERDŐS–RÉNYI RANDOM GRAPH
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 08 March 2021, pp. 747-773
-
- Article
- Export citation

Mathematical Foundations of Infinite-Dimensional Statistical Models
-
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021
ROBUST ESTIMATION OF LOSS MODELS FOR LOGNORMAL INSURANCE PAYMENT SEVERITY DATA
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 05 March 2021, pp. 475-507
- Print publication:
- May 2021
-
- Article
- Export citation
Fourier analysis using the number of COVID-19 daily deaths in the US
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 04 March 2021, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
