Refine search
Actions for selected content:
52675 results in Statistics and Probability
The spatio-temporal distribution of COVID-19 infection in England between January and June 2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 March 2021, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Presence of SARS-CoV-2 RNA on playground surfaces and water fountains
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 March 2021, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
KOLMOGOROV BOUNDS FOR THE NORMAL APPROXIMATION OF THE NUMBER OF TRIANGLES IN THE ERDŐS–RÉNYI RANDOM GRAPH
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 08 March 2021, pp. 747-773
-
- Article
- Export citation

Mathematical Foundations of Infinite-Dimensional Statistical Models
-
- Published online:
- 05 March 2021
- Print publication:
- 25 March 2021
ROBUST ESTIMATION OF LOSS MODELS FOR LOGNORMAL INSURANCE PAYMENT SEVERITY DATA
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 05 March 2021, pp. 475-507
- Print publication:
- May 2021
-
- Article
- Export citation
Fourier analysis using the number of COVID-19 daily deaths in the US
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 04 March 2021, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Weather variability and transmissibility of COVID-19: a time series analysis based on effective reproductive number
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 03 March 2021, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SCALING PROPERTIES OF QUEUES WITH TIME-VARYING LOAD PROCESSES: EXTENSIONS AND APPLICATIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 03 March 2021, pp. 690-731
-
- Article
- Export citation
The IFRS 17 contractual service margin: a life insurance perspective
-
- Journal:
- British Actuarial Journal / Volume 26 / 2021
- Published online by Cambridge University Press:
- 02 March 2021, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Oyster growth across a salinity gradient in a shallow, subtropical Gulf of Mexico estuary—ERRATUM
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 02 March 2021, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Extracting information from textual descriptions for actuarial applications
-
- Journal:
- Annals of Actuarial Science / Volume 15 / Issue 3 / November 2021
- Published online by Cambridge University Press:
- 02 March 2021, pp. 605-622
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiology and transmission characteristics of early COVID-19 cases, 20 January–19 March 2020, in Bavaria, Germany
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 March 2021, e65
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Model-independent pricing with insider information: a skorokhod embedding approach
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 30-56
- Print publication:
- March 2021
-
- Article
- Export citation
Optimally Stopping at a Given Distance from the Ultimate Supremum of a Spectrally Negative Lévy Process
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 279-299
- Print publication:
- March 2021
-
- Article
- Export citation
-
We consider the optimal prediction problem of stopping a spectrally negative Lévy process as close as possible to a given distance
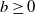 $b \geq 0$ from its ultimate supremum, under a squared-error penalty function. Under some mild conditions, the solution is fully and explicitly characterised in terms of scale functions. We find that the solution has an interesting non-trivial structure: if b is larger than a certain threshold then it is optimal to stop as soon as the difference between the running supremum and the position of the process exceeds a certain level (less than b), while if b is smaller than this threshold then it is optimal to stop immediately (independent of the running supremum and position of the process). We also present some examples.
$b \geq 0$ from its ultimate supremum, under a squared-error penalty function. Under some mild conditions, the solution is fully and explicitly characterised in terms of scale functions. We find that the solution has an interesting non-trivial structure: if b is larger than a certain threshold then it is optimal to stop as soon as the difference between the running supremum and the position of the process exceeds a certain level (less than b), while if b is smaller than this threshold then it is optimal to stop immediately (independent of the running supremum and position of the process). We also present some examples.
Utility of whole-genome sequencing during an investigation of multiple foodborne outbreaks of Shigella sonnei
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 01 March 2021, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The fluid limit of a random graph model for a shared ledger
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 81-106
- Print publication:
- March 2021
-
- Article
- Export citation
RELATIVE ERROR ACCURATE STATISTIC BASED ON NONPARAMETRIC LIKELIHOOD
-
- Journal:
- Econometric Theory / Volume 37 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 01 March 2021, pp. 1214-1237
-
- Article
- Export citation
-
This paper develops a new test statistic for parameters defined by moment conditions that exhibits desirable relative error properties for the approximation of tail area probabilities. Our statistic, called the tilted exponential tilting (TET) statistic, is constructed by estimating certain cumulant generating functions under exponential tilting weights. We show that the asymptotic p-value of the TET statistic can provide an accurate approximation to the p-value of an infeasible saddlepoint statistic, which admits a Lugannani–Rice style adjustment with relative errors of order
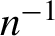 $n^{-1}$ both in normal and large deviation regions. Numerical results illustrate the accuracy of the proposed TET statistic. Our results cover both just- and overidentified moment condition models. A limitation of our analysis is that the theoretical approximation results are exclusively for the infeasible saddlepoint statistic, and closeness of the p-values for the infeasible statistic to the ones for the feasible TET statistic is only numerically assessed.
$n^{-1}$ both in normal and large deviation regions. Numerical results illustrate the accuracy of the proposed TET statistic. Our results cover both just- and overidentified moment condition models. A limitation of our analysis is that the theoretical approximation results are exclusively for the infeasible saddlepoint statistic, and closeness of the p-values for the infeasible statistic to the ones for the feasible TET statistic is only numerically assessed.
OPTIMAL ADMISSION AND ROUTING WITH CONGESTION-SENSITIVE CUSTOMER CLASSES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 01 March 2021, pp. 774-798
-
- Article
-
- You have access
- Open access
- Export citation
Can Coherent Predictions be Contradictory?
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 133-161
- Print publication:
- March 2021
-
- Article
- Export citation
-
We prove the sharp bound for the probability that two experts who have access to different information, represented by different
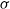 $\sigma$-fields, will give radically different estimates of the probability of an event. This is relevant when one combines predictions from various experts in a common probability space to obtain an aggregated forecast. The optimizer for the bound is explicitly described. This paper was originally titled ‘Contradictory predictions’.
$\sigma$-fields, will give radically different estimates of the probability of an event. This is relevant when one combines predictions from various experts in a common probability space to obtain an aggregated forecast. The optimizer for the bound is explicitly described. This paper was originally titled ‘Contradictory predictions’.
APR volume 53 issue 1 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. f1-f2
- Print publication:
- March 2021
-
- Article
-
- You have access
- Export citation
