Refine search
Actions for selected content:
52675 results in Statistics and Probability
Lyapunov-type conditions for non-strong ergodicity of Markov processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 238-253
- Print publication:
- March 2021
-
- Article
- Export citation
-
We present Lyapunov-type conditions for non-strong ergodicity of Markov processes. Some concrete models are discussed, including diffusion processes on Riemannian manifolds and Ornstein–Uhlenbeck processes driven by symmetric
 $\alpha$-stable processes. In particular, we show that any process of d-dimensional Ornstein–Uhlenbeck type driven by
$\alpha$-stable processes. In particular, we show that any process of d-dimensional Ornstein–Uhlenbeck type driven by  $\alpha$-stable noise is not strongly ergodic for every
$\alpha$-stable noise is not strongly ergodic for every 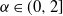 $\alpha\in (0,2]$.
$\alpha\in (0,2]$.


Stochastic comparisons and ageing properties of an extended gamma process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 140-163
- Print publication:
- March 2021
-
- Article
- Export citation
JPR volume 58 issue 1 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. b1-b2
- Print publication:
- March 2021
-
- Article
-
- You have access
- Export citation
JPR volume 58 issue 1 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. f1-f2
- Print publication:
- March 2021
-
- Article
-
- You have access
- Export citation
Tail asymptotics for the area under the excursion of a random walk with heavy-tailed increments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 217-237
- Print publication:
- March 2021
-
- Article
- Export citation
Gaussian process approximations for multicolor Pólya urn models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 274-286
- Print publication:
- March 2021
-
- Article
- Export citation
-
Motivated by mathematical tissue growth modelling, we consider the problem of approximating the dynamics of multicolor Pólya urn processes that start with large numbers of balls of different colors and run for a long time. Using strong approximation theorems for empirical and quantile processes, we establish Gaussian process approximations for the Pólya urn processes. The approximating processes are sums of a multivariate Brownian motion process and an independent linear drift with a random Gaussian coefficient. The dominating term between the two depends on the ratio of the number of time steps n to the initial number of balls N in the urn. We also establish an upper bound of the form
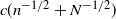 $c(n^{-1/2}+N^{-1/2})$ for the maximum deviation over the class of convex Borel sets of the step-n urn composition distribution from the approximating normal law.
$c(n^{-1/2}+N^{-1/2})$ for the maximum deviation over the class of convex Borel sets of the step-n urn composition distribution from the approximating normal law.
The martingale comparison method for Markov processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 164-176
- Print publication:
- March 2021
-
- Article
- Export citation
Self-exciting multifractional processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 22-41
- Print publication:
- March 2021
-
- Article
- Export citation
-
We propose a new multifractional stochastic process which allows for self-exciting behavior, similar to what can be seen for example in earthquakes and other self-organizing phenomena. The process can be seen as an extension of a multifractional Brownian motion, where the Hurst function is dependent on the past of the process. We define this by means of a stochastic Volterra equation, and we prove existence and uniqueness of this equation, as well as giving bounds on the p-order moments, for all
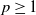 $p\geq1$. We show convergence of an Euler–Maruyama scheme for the process, and also give the rate of convergence, which is dependent on the self-exciting dynamics of the process. Moreover, we discuss various applications of this process, and give examples of different functions to model self-exciting behavior.
$p\geq1$. We show convergence of an Euler–Maruyama scheme for the process, and also give the rate of convergence, which is dependent on the self-exciting dynamics of the process. Moreover, we discuss various applications of this process, and give examples of different functions to model self-exciting behavior.
Spatial dynamics of the COVID-19 pandemic in Brazil
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 25 February 2021, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Simple conditions for metastability of continuous Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 83-105
- Print publication:
- March 2021
-
- Article
- Export citation
-
A family
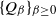 $\{Q_{\beta}\}_{\beta \geq 0}$ of Markov chains is said to exhibit metastable mixing with modes
$\{Q_{\beta}\}_{\beta \geq 0}$ of Markov chains is said to exhibit metastable mixing with modes 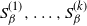 $S_{\beta}^{(1)},\ldots,S_{\beta}^{(k)}$ if its spectral gap (or some other mixing property) is very close to the worst conductance
$S_{\beta}^{(1)},\ldots,S_{\beta}^{(k)}$ if its spectral gap (or some other mixing property) is very close to the worst conductance 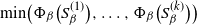 $\min\!\big(\Phi_{\beta}\big(S_{\beta}^{(1)}\big), \ldots, \Phi_{\beta}\big(S_{\beta}^{(k)}\big)\big)$ of its modes for all large values of
$\min\!\big(\Phi_{\beta}\big(S_{\beta}^{(1)}\big), \ldots, \Phi_{\beta}\big(S_{\beta}^{(k)}\big)\big)$ of its modes for all large values of 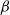 $\beta$. We give simple sufficient conditions for a family of Markov chains to exhibit metastability in this sense, and verify that these conditions hold for a prototypical Metropolis–Hastings chain targeting a mixture distribution. The existing metastability literature is large, and our present work is aimed at filling the following small gap: finding sufficient conditions for metastability that are easy to verify for typical examples from statistics using well-studied methods, while at the same time giving an asymptotically exact formula for the spectral gap (rather than a bound that can be very far from sharp). Our bounds from this paper are used in a companion paper (O. Mangoubi, N. S. Pillai, and A. Smith, arXiv:1808.03230) to compare the mixing times of the Hamiltonian Monte Carlo algorithm and a random walk algorithm for multimodal target distributions.
$\beta$. We give simple sufficient conditions for a family of Markov chains to exhibit metastability in this sense, and verify that these conditions hold for a prototypical Metropolis–Hastings chain targeting a mixture distribution. The existing metastability literature is large, and our present work is aimed at filling the following small gap: finding sufficient conditions for metastability that are easy to verify for typical examples from statistics using well-studied methods, while at the same time giving an asymptotically exact formula for the spectral gap (rather than a bound that can be very far from sharp). Our bounds from this paper are used in a companion paper (O. Mangoubi, N. S. Pillai, and A. Smith, arXiv:1808.03230) to compare the mixing times of the Hamiltonian Monte Carlo algorithm and a random walk algorithm for multimodal target distributions.
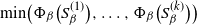
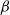
Double hypergeometric Lévy processes and self-similarity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 254-273
- Print publication:
- March 2021
-
- Article
- Export citation
Entropy of killed-resurrected stationary Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 177-196
- Print publication:
- March 2021
-
- Article
- Export citation
Ergodic control of diffusions with random intervention times
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 1-21
- Print publication:
- March 2021
-
- Article
- Export citation
On a generalization of the Rényi–Srivastava characterization of the Poisson law
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 68-82
- Print publication:
- March 2021
-
- Article
- Export citation
Extinction and coming down from infinity of continuous-state branching processes with competition in a Lévy environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 128-139
- Print publication:
- March 2021
-
- Article
- Export citation
Mobile isolation wards in a fever clinic: a novel operation model during the COVID-19 pandemic
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 24 February 2021, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SARS-CoV-2 molecular testing in Greek hospital paediatric departments: a nationwide study
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 24 February 2021, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamics and risk of transmission of bovine tuberculosis in the emerging dairy regions of Ethiopia
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 24 February 2021, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ESTIMATION AND INFERENCE FOR MOMENTS OF RATIOS WITH ROBUSTNESS AGAINST LARGE TRIMMING BIAS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 23 February 2021, pp. 66-112
-
- Article
- Export citation
-
Researchers often trim observations with small values of the denominator A when they estimate moments of the form
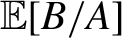 $\mathbb {E}[B/A]$. Large trimming is common in practice to reduce variance, but it incurs a large bias. This paper provides a novel method of correcting the large trimming bias. If a researcher is willing to assume that the joint distribution between A and B is smooth, then the trimming bias may be estimated well. Along with the proposed bias correction method, we also develop an inference method. Practical advantages of the proposed method are demonstrated through simulation studies, where the data generating process entails a heavy-tailed distribution of
$\mathbb {E}[B/A]$. Large trimming is common in practice to reduce variance, but it incurs a large bias. This paper provides a novel method of correcting the large trimming bias. If a researcher is willing to assume that the joint distribution between A and B is smooth, then the trimming bias may be estimated well. Along with the proposed bias correction method, we also develop an inference method. Practical advantages of the proposed method are demonstrated through simulation studies, where the data generating process entails a heavy-tailed distribution of 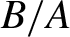 $B/A$. Applying the proposed method to the Compustat database, we analyze the history of external financial dependence of U.S. manufacturing firms for years 2000–2010.
$B/A$. Applying the proposed method to the Compustat database, we analyze the history of external financial dependence of U.S. manufacturing firms for years 2000–2010.
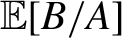
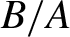
GENERALIZED LAPLACE INFERENCE IN MULTIPLE CHANGE-POINTS MODELS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 23 February 2021, pp. 35-65
-
- Article
- Export citation
