Refine search
Actions for selected content:
52713 results in Statistics and Probability
8 - Combining Direct Spectral Estimators
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp 351-444
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp 667-692
-
- Chapter
- Export citation
Data, Software and Ancillary Material
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp xxiv-xxiv
-
- Chapter
- Export citation
11 - Simulation of Time Series
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp 593-642
-
- Chapter
- Export citation
Dedication
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp v-vi
-
- Chapter
- Export citation
Contents
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp vii-xii
-
- Chapter
- Export citation
6 - Periodogram and Other Direct Spectral Estimators
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp 163-244
-
- Chapter
- Export citation
1 - Introduction to Spectral Analysis
-
- Book:
- Spectral Analysis for Univariate Time Series
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020, pp 1-20
-
- Chapter
- Export citation
ANALYTICALLY CLOSED-FORM SOLUTIONS FOR THE DISTRIBUTION OF A NUMBER OF CUSTOMERS SERVED DURING A BUSY PERIOD FOR SPECIAL CASES OF THE GEO/G/1 QUEUE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 18 March 2020, pp. 650-679
-
- Article
- Export citation
ANALYSIS AND APPLICATIONS OF THE RESIDUAL VARENTROPY OF RANDOM LIFETIMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 18 March 2020, pp. 680-698
-
- Article
-
- You have access
- Open access
- Export citation
GENERALIZATION OF THE PAIRWISE STOCHASTIC PRECEDENCE ORDER TO THE SEQUENCE OF RANDOM VARIABLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 18 March 2020, pp. 699-707
-
- Article
- Export citation

Spectral Analysis for Univariate Time Series
-
- Published online:
- 17 March 2020
- Print publication:
- 19 March 2020
Research about the optimal strategies for prevention and control of varicella outbreak in a school in a central city of China: based on an SEIR dynamic model
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 17 March 2020, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COUNT AND DURATION TIME SERIES WITH EQUAL CONDITIONAL STOCHASTIC AND MEAN ORDERS
-
- Journal:
- Econometric Theory / Volume 37 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 17 March 2020, pp. 248-280
-
- Article
- Export citation
Time series analysis and forecasting of chlamydia trachomatis incidence using surveillance data from 2008 to 2019 in Shenzhen, China
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 17 March 2020, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
QUANTILE TREATMENT EFFECTS IN REGRESSION KINK DESIGNS
-
- Journal:
- Econometric Theory / Volume 36 / Issue 6 / December 2020
- Published online by Cambridge University Press:
- 17 March 2020, pp. 1167-1191
-
- Article
- Export citation
Prevalence of Coxiella burnetii in German sheep flocks and evaluation of a novel approach to detect an infection via preputial swabs at herd-level
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 16 March 2020, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Constraints, the identifiability problem and the forecasting of mortality
-
- Journal:
- Annals of Actuarial Science / Volume 14 / Issue 2 / September 2020
- Published online by Cambridge University Press:
- 16 March 2020, pp. 537-566
-
- Article
- Export citation
-
Models of mortality often require constraints in order that parameters may be estimated uniquely. It is not difficult to find references in the literature to the “identifiability problem”, and papers often give arguments to justify the choice of particular constraint systems designed to deal with this problem. Many of these models are generalised linear models, and it is known that the fitted values (of mortality) in such models are identifiable, i.e., invariant with respect to the choice of constraint systems. We show that for a wide class of forecasting models, namely ARIMA
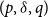 $(p,\delta, q)$ models with a fitted mean and
$(p,\delta, q)$ models with a fitted mean and 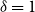 $\delta = 1$ or 2, identifiability extends to the forecast values of mortality; this extended identifiability continues to hold when some model terms are smoothed. The results are illustrated with data on UK males from the Office for National Statistics for the age-period model, the age-period-cohort model, the age-period-cohort-improvements model of the Continuous Mortality Investigation and the Lee–Carter model.
$\delta = 1$ or 2, identifiability extends to the forecast values of mortality; this extended identifiability continues to hold when some model terms are smoothed. The results are illustrated with data on UK males from the Office for National Statistics for the age-period model, the age-period-cohort model, the age-period-cohort-improvements model of the Continuous Mortality Investigation and the Lee–Carter model.
Animal agriculture exposures among Minnesota residents with zoonotic enteric infections, 2012–2016
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 16 March 2020, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antibodies of influenza A(H1N1)pdm09 virus in pigs’ sera cross-react with other influenza A virus subtypes. A retrospective epidemiological interpretation of Norway's serosurveillance data from 2009–2017
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 13 March 2020, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
