Refine search
Actions for selected content:
53172 results in Statistics and Probability
ON THE ROBUSTNESS OF MIXTURE MODELS IN THE PRESENCE OF HIDDEN MARKOV REGIMES WITH COVARIATE-DEPENDENT TRANSITION PROBABILITIES
-
- Journal:
- Econometric Theory / Volume 41 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 16 June 2025, pp. 1229-1243
-
- Article
-
- You have access
- Open access
- Export citation
Infinite-horizon Fuk–Nagaev inequalities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 16 June 2025, pp. 1076-1088
- Print publication:
- September 2025
-
- Article
- Export citation
UNIFORM CONVERGENCE RATES FOR NONPARAMETRIC ESTIMATORS OF A DENSITY FUNCTION AND ITS DERIVATIVES WHEN THE DENSITY HAS A KNOWN POLE
-
- Journal:
- Econometric Theory / Volume 42 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 13 June 2025, pp. 631-657
-
- Article
-
- You have access
- Open access
- Export citation
Sojourn functionals of time-dependent
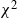 $\chi^2$-random fields on two-point homogeneous spaces
$\chi^2$-random fields on two-point homogeneous spaces
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 13 June 2025, pp. 1493-1512
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate geometric properties of invariant spatio-temporal random fields
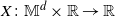 $X\colon\mathbb M^d\times \mathbb R\to \mathbb R$ defined on a compact two-point homogeneous space
$X\colon\mathbb M^d\times \mathbb R\to \mathbb R$ defined on a compact two-point homogeneous space 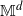 $\mathbb M^d$ in any dimension
$\mathbb M^d$ in any dimension 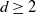 $d\ge 2$, and evolving over time. In particular, we focus on chi-squared-distributed random fields, and study the large-time behavior (as
$d\ge 2$, and evolving over time. In particular, we focus on chi-squared-distributed random fields, and study the large-time behavior (as 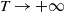 $T\to +\infty$) of the average on [0,T] of the volume of the excursion set on the manifold, i.e. of
$T\to +\infty$) of the average on [0,T] of the volume of the excursion set on the manifold, i.e. of 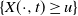 $\lbrace X(\cdot, t)\ge u\rbrace$ (for any
$\lbrace X(\cdot, t)\ge u\rbrace$ (for any 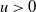 $u >0$). The Fourier components of X may have short or long memory in time, i.e. integrable or non-integrable temporal covariance functions. Our argument follows the approach developed in Marinucci et al. (2021) and allows us to extend their results for invariant spatio-temporal Gaussian fields on the two-dimensional unit sphere to the case of chi-squared distributed fields on two-point homogeneous spaces in any dimension. We find that both the asymptotic variance and limiting distribution, as
$u >0$). The Fourier components of X may have short or long memory in time, i.e. integrable or non-integrable temporal covariance functions. Our argument follows the approach developed in Marinucci et al. (2021) and allows us to extend their results for invariant spatio-temporal Gaussian fields on the two-dimensional unit sphere to the case of chi-squared distributed fields on two-point homogeneous spaces in any dimension. We find that both the asymptotic variance and limiting distribution, as 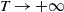 $T\to +\infty$, of the average empirical volume turn out to be non-universal, depending on the memory parameters of the field X.
$T\to +\infty$, of the average empirical volume turn out to be non-universal, depending on the memory parameters of the field X.
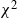
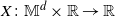
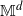
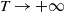
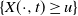
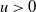
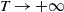
Inverting the healthcare pyramid: building synergies between outpatient care and inpatient hospitalisation
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 13 June 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk aggregation and stochastic dominance for a class of heavy-tailed distributions
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 56 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 11 June 2025, pp. 206-219
- Print publication:
- January 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Application of joinpoint regression to SARS-CoV-2 wastewater-based epidemiology in Las Vegas, Nevada, USA
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 09 June 2025, e68
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modelling the risk of food-borne transmission of Toxocara spp. to humans
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 09 June 2025, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ergodic theorem for branching markov chains indexed by trees with arbitrary shape
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 09 June 2025, pp. 1089-1104
- Print publication:
- September 2025
-
- Article
- Export citation
-
We prove an ergodic theorem for Markov chains indexed by the Ulam–Harris–Neveu tree over large subsets with arbitrary shape under two assumptions: (i) with high probability, two vertices in the large subset are far from each other, and (ii) with high probability, those two vertices have their common ancestor close to the root. The assumption on the common ancestor can be replaced by some regularity assumption on the Markov transition kernel. We verify that these assumptions are satisfied for some usual trees. Finally, with Markov chain Monte Carlo considerations in mind, we prove that when the underlying Markov chain is stationary and reversible, the Markov chain, that is the line graph, yields minimal variance for the empirical average estimator among trees with a given number of nodes. In doing so, we prove that the Hosoya–Wiener polynomial is minimized over
 $[{-}1,1]$ by the line graph among trees of a given size.
$[{-}1,1]$ by the line graph among trees of a given size.

Epidemic models with digital and manual contact tracing
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 09 June 2025, pp. 1430-1455
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We analyse a Markovian SIR epidemic model where individuals either recover naturally or are diagnosed, leading to isolation and potential contact tracing. Our focus is on digital contact tracing via a tracing app, considering both its standalone use and its combination with manual tracing. We prove that as the population size n grows large, the epidemic process converges to a limiting process, which, unlike with typical epidemic models, is not a branching process due to dependencies created by contact tracing. However, by grouping to-be-traced individuals into macro-individuals, we derive a multi-type branching process interpretation, allowing computation of the reproduction number R. This is then converted to an individual reproduction number
 $R^\mathrm{(ind)}$, which, in contrast to R, decays monotonically with the fraction of app-users, while both share the same threshold at 1. Finally, we compare digital (only) contact tracing and manual (only) contact tracing, proving that the critical fraction of app-users,
$R^\mathrm{(ind)}$, which, in contrast to R, decays monotonically with the fraction of app-users, while both share the same threshold at 1. Finally, we compare digital (only) contact tracing and manual (only) contact tracing, proving that the critical fraction of app-users,  $\pi_{\mathrm{c}}$, required for
$\pi_{\mathrm{c}}$, required for  $R=1$ is higher than the critical fraction manually contact-traced,
$R=1$ is higher than the critical fraction manually contact-traced,  $p_{\mathrm{c}}$, for manual tracing.
$p_{\mathrm{c}}$, for manual tracing.




Joining forces for online feedback management: policy recommendations for human–AI collaboration – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 09 June 2025, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
11 - Structural Results for Optimal Filters
- from Part III - POMDP Structural Results
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 282-311
-
- Chapter
- Export citation
Appendix A - Short Primer on Stochastic Simulation
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 570-584
-
- Chapter
- Export citation
2 - Reversible MCMC and Its Scaling
-
- Book:
- Scalable Monte Carlo for Bayesian Learning
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 39-61
-
- Chapter
- Export citation
Appendix B - Continuous-Time HMM Filters
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 585-592
-
- Chapter
- Export citation
19 - Discrete Stochastic Optimization
- from Part IV - Stochastic Gradient Algorithms and Reinforcement Learning
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 509-522
-
- Chapter
- Export citation
3 - Optimal Filtering
- from Part I - Stochastic Models and Bayesian Inference
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 34-70
-
- Chapter
- Export citation
18 - Stochastic Gradient Algorithms. Convergence Analysis
- from Part IV - Stochastic Gradient Algorithms and Reinforcement Learning
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 466-508
-
- Chapter
- Export citation
13 - Structural Results for Stopping-Time POMDPs
- from Part III - POMDP Structural Results
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 327-375
-
- Chapter
- Export citation
References
-
- Book:
- Scalable Monte Carlo for Bayesian Learning
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 225-234
-
- Chapter
- Export citation
