Refine search
Actions for selected content:
53172 results in Statistics and Probability
Contents
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp v-xi
-
- Chapter
- Export citation
5 - Multiagent Sensing: Social Learning and Data Incest
- from Part I - Stochastic Models and Bayesian Inference
-
- Book:
- Partially Observed Markov Decision Processes
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 91-113
-
- Chapter
- Export citation
Cutoff for the logistic SIS epidemic model with self-infection
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 04 June 2025, pp. 1456-1483
- Print publication:
- December 2025
-
- Article
- Export citation
Moderate deviations for weight-dependent random connection models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 04 June 2025, pp. 1406-1428
- Print publication:
- December 2025
-
- Article
- Export citation
Percolation in lattice k-neighbor graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 03 June 2025, pp. 1475-1492
- Print publication:
- December 2025
-
- Article
- Export citation
-
We define a random graph obtained by connecting each point of
 $\mathbb{Z}^d$ independently and uniformly to a fixed number
$\mathbb{Z}^d$ independently and uniformly to a fixed number  $1 \leq k \leq 2d$ of its nearest neighbors via a directed edge. We call this graph the directed k-neighbor graph. Two natural associated undirected graphs are the undirected and the bidirectional k-neighbor graph, where we connect two vertices by an undirected edge whenever there is a directed edge in the directed k-neighbor graph between the vertices in at least one, respectively precisely two, directions. For these graphs we study the question of percolation, i.e. the existence of an infinite self-avoiding path. Using different kinds of proof techniques for different classes of cases, we show that for
$1 \leq k \leq 2d$ of its nearest neighbors via a directed edge. We call this graph the directed k-neighbor graph. Two natural associated undirected graphs are the undirected and the bidirectional k-neighbor graph, where we connect two vertices by an undirected edge whenever there is a directed edge in the directed k-neighbor graph between the vertices in at least one, respectively precisely two, directions. For these graphs we study the question of percolation, i.e. the existence of an infinite self-avoiding path. Using different kinds of proof techniques for different classes of cases, we show that for  $k=1$ even the undirected k-neighbor graph never percolates, while the directed k-neighbor graph percolates whenever
$k=1$ even the undirected k-neighbor graph never percolates, while the directed k-neighbor graph percolates whenever  $k \geq d+1$,
$k \geq d+1$,  $k \geq 3$, and
$k \geq 3$, and  $d \geq 5$, or
$d \geq 5$, or  $k \geq 4$ and
$k \geq 4$ and  $d=4$. We also show that the undirected 2-neighbor graph percolates for
$d=4$. We also show that the undirected 2-neighbor graph percolates for  $d=2$, the undirected 3-neighbor graph percolates for
$d=2$, the undirected 3-neighbor graph percolates for  $d=3$, and we provide some positive and negative percolation results regarding the bidirectional graph as well. A heuristic argument for high dimensions indicates that this class of models is a natural discrete analogue of the k-nearest-neighbor graphs studied in continuum percolation, and our results support this interpretation.
$d=3$, and we provide some positive and negative percolation results regarding the bidirectional graph as well. A heuristic argument for high dimensions indicates that this class of models is a natural discrete analogue of the k-nearest-neighbor graphs studied in continuum percolation, and our results support this interpretation.










Facing the ambiguities of participation in data-driven projects: a systematic literature review
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 03 June 2025, e41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Recurring spoken term discovery in the zero-resource constraint using diagonal patterns
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 02 June 2025, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Case–control study of leptospirosis in Aotearoa New Zealand reveals behavioural, occupational, and environmental risk factors
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 02 June 2025, e67
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tight Hamilton cycles with high discrepancy
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 30 May 2025, pp. 565-584
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study discrepancy questions for spanning subgraphs of
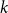 $k$-uniform hypergraphs. Our main result is that, for any integers
$k$-uniform hypergraphs. Our main result is that, for any integers 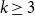 $k \ge 3$ and
$k \ge 3$ and 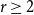 $r \ge 2$, any
$r \ge 2$, any  $r$-colouring of the edges of a
$r$-colouring of the edges of a 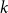 $k$-uniform
$k$-uniform  $n$-vertex hypergraph
$n$-vertex hypergraph 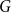 $G$ with minimum
$G$ with minimum 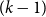 $(k-1)$-degree
$(k-1)$-degree 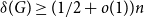 $\delta (G) \ge (1/2+o(1))n$ contains a tight Hamilton cycle with high discrepancy, that is, with at least
$\delta (G) \ge (1/2+o(1))n$ contains a tight Hamilton cycle with high discrepancy, that is, with at least 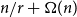 $n/r+\Omega (n)$ edges of one colour. The minimum degree condition is asymptotically best possible and our theorem also implies a corresponding result for perfect matchings. Our tools combine various structural techniques such as Turán-type problems and hypergraph shadows with probabilistic techniques such as random walks and the nibble method. We also propose several intriguing problems for future research.
$n/r+\Omega (n)$ edges of one colour. The minimum degree condition is asymptotically best possible and our theorem also implies a corresponding result for perfect matchings. Our tools combine various structural techniques such as Turán-type problems and hypergraph shadows with probabilistic techniques such as random walks and the nibble method. We also propose several intriguing problems for future research.
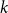
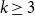
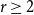

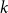

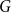
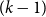
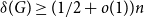
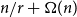
Legionnaires’ disease outbreak linked to a cold-water source in Yorkshire, 2022
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 30 May 2025, e66
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Random Matrix Theory, Interacting Particle Systems, and Integrable Systems
-
- Published online:
- 29 May 2025
- Print publication:
- 15 December 2014
On the last zero process with an application in corporate bankruptcy
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 28 May 2025, pp. 122-169
- Print publication:
- March 2026
-
- Article
- Export citation
-
For a spectrally negative Lévy process X, consider
 $g_t$ and its infinitesimal generator. Moreover, with
$g_t$ and its infinitesimal generator. Moreover, with  $t\geq 0$, the last time X is below the level zero before time
$t\geq 0$, the last time X is below the level zero before time  $\{(g_t,t, X_t), t\geq 0 \}$ the length of a current positive excursion, we derive a general formula that allows us to calculate a functional of the whole path of
$\{(g_t,t, X_t), t\geq 0 \}$ the length of a current positive excursion, we derive a general formula that allows us to calculate a functional of the whole path of  $U_t\,:\!=\,t-g_t$. We use a perturbation method for Lévy processes to derive an Itô formula for the three-dimensional process
$U_t\,:\!=\,t-g_t$. We use a perturbation method for Lévy processes to derive an Itô formula for the three-dimensional process 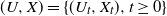 $ (U, X)=\{(U_t, X_t),t\geq 0\}$ in terms of the positive and negative excursions of the process X. As a corollary, we find the joint Laplace transform of
$ (U, X)=\{(U_t, X_t),t\geq 0\}$ in terms of the positive and negative excursions of the process X. As a corollary, we find the joint Laplace transform of  $(U_{\mathbf{e}_q}, X_{\mathbf{e}_q})$, where
$(U_{\mathbf{e}_q}, X_{\mathbf{e}_q})$, where  $\mathbf{e}_q$ is an independent exponential time, and the q-potential measure of the process (U, X). Furthermore, using the results mentioned above, we find a solution to a general optimal stopping problem depending on (U, X) with an application in corporate bankruptcy. Lastly, we establish a link between the optimal prediction of
$\mathbf{e}_q$ is an independent exponential time, and the q-potential measure of the process (U, X). Furthermore, using the results mentioned above, we find a solution to a general optimal stopping problem depending on (U, X) with an application in corporate bankruptcy. Lastly, we establish a link between the optimal prediction of 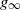 $g_{\infty}$ and optimal stopping problems in terms of (U, X) as per Baurdoux, E. J. and Pedraza, J. M.,
$g_{\infty}$ and optimal stopping problems in terms of (U, X) as per Baurdoux, E. J. and Pedraza, J. M.,  $L_p$ optimal prediction of the last zero of a spectrally negative Lévy process, Annals of Applied Probability, 34 (2024), 1350–1402.
$L_p$ optimal prediction of the last zero of a spectrally negative Lévy process, Annals of Applied Probability, 34 (2024), 1350–1402.







Quantifying the direct and indirect components of COVID-19 vaccine effectiveness during the Delta variant era – ERRATUM
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 28 May 2025, e65
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE ECONOMETRIC THEORY AWARDS 2025
-
- Journal:
- Econometric Theory / Volume 41 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 28 May 2025, p. 994
-
- Article
-
- You have access
- Export citation
Non-homogeneous and time-changed versions of generalized counting processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 27 May 2025, pp. 43-79
- Print publication:
- March 2026
-
- Article
- Export citation
Diffusion approximation of the stationary distribution of a two-level single server queue
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 27 May 2025, pp. 1167-1205
- Print publication:
- December 2025
-
- Article
- Export citation
Steady-state Dirichlet approximation of the Wright-Fisher model using the prelimit generator comparison approach of Stein’s method
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 27 May 2025, pp. 1321-1359
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The Wright–Fisher model, originating in Wright (1931) is one of the canonical probabilistic models used in mathematical population genetics to study how genetic type frequencies evolve in time. In this paper we bound the rate of convergence of the stationary distribution for a finite population Wright–Fisher Markov chain with parent-independent mutation to the Dirichlet distribution. Our result improves the rate of convergence established in Gan et al. (2017) from
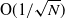 $\mathrm{O}(1/\sqrt{N})$ to
$\mathrm{O}(1/\sqrt{N})$ to 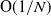 $\mathrm{O}(1/N)$. The results are derived using Stein’s method, in particular, the prelimit generator comparison method.
$\mathrm{O}(1/N)$. The results are derived using Stein’s method, in particular, the prelimit generator comparison method.
On the edge eigenvalues of the precision matrices of nonstationary autoregressive processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 27 May 2025, pp. 907-939
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Statistical models for improved insurance risk assessment using telematics
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 26 May 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotic behaviors of subcritical branching killed Brownian motion with drift
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 26 May 2025, pp. 1484-1509
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study asymptotic behaviors of a subcritical branching Brownian motion with drift
 $-\rho$, killed upon exiting
$-\rho$, killed upon exiting  $(0, \infty)$, and offspring distribution
$(0, \infty)$, and offspring distribution  $\{p_k{:}\; k\ge 0\}$. Let
$\{p_k{:}\; k\ge 0\}$. Let  $\widetilde{\zeta}^{-\rho}$ be the extinction time of this subcritical branching killed Brownian motion,
$\widetilde{\zeta}^{-\rho}$ be the extinction time of this subcritical branching killed Brownian motion,  $\widetilde{M}_t^{-\rho}$ the maximal position of all the particles alive at time t and
$\widetilde{M}_t^{-\rho}$ the maximal position of all the particles alive at time t and  $\widetilde{M}^{-\rho}:\!=\max_{t\ge 0}\widetilde{M}_t^{-\rho}$ the all-time maximal position. Let
$\widetilde{M}^{-\rho}:\!=\max_{t\ge 0}\widetilde{M}_t^{-\rho}$ the all-time maximal position. Let  $\mathbb{P}_x$ be the law of this subcritical branching killed Brownian motion when the initial particle is located at
$\mathbb{P}_x$ be the law of this subcritical branching killed Brownian motion when the initial particle is located at  $x\in (0,\infty)$. Under the assumption
$x\in (0,\infty)$. Under the assumption  $\sum_{k=1}^\infty k ({\log}\; k) p_k <\infty$, we establish the decay rates of
$\sum_{k=1}^\infty k ({\log}\; k) p_k <\infty$, we establish the decay rates of  $\mathbb{P}_x(\widetilde{\zeta}^{-\rho}>t)$ and
$\mathbb{P}_x(\widetilde{\zeta}^{-\rho}>t)$ and  $\mathbb{P}_x(\widetilde{M}^{-\rho}>y)$ as t and y respectively tend to
$\mathbb{P}_x(\widetilde{M}^{-\rho}>y)$ as t and y respectively tend to  $\infty$. We also establish the decay rate of
$\infty$. We also establish the decay rate of  $\mathbb{P}_x(\widetilde{M}_t^{-\rho}> z(t,\rho))$ as
$\mathbb{P}_x(\widetilde{M}_t^{-\rho}> z(t,\rho))$ as  $t\to\infty$, where
$t\to\infty$, where  $z(t,\rho)=\sqrt{t}z-\rho t$ for
$z(t,\rho)=\sqrt{t}z-\rho t$ for  $\rho\leq 0$ and
$\rho\leq 0$ and  $z(t,\rho)=z$ for
$z(t,\rho)=z$ for  $\rho>0$. As a consequence, we obtain a Yaglom-type limit theorem.
$\rho>0$. As a consequence, we obtain a Yaglom-type limit theorem.


















