Refine search
Actions for selected content:
53172 results in Statistics and Probability
Assessing driving risk through unsupervised detection of anomalies in telematics time series data
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 22 May 2025, pp. 205-241
- Print publication:
- May 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ASB volume 55 issue 2 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 22 May 2025, pp. f1-f2
- Print publication:
- May 2025
-
- Article
-
- You have access
- Export citation
ASB volume 55 issue 2 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 22 May 2025, pp. b1-b3
- Print publication:
- May 2025
-
- Article
-
- You have access
- Export citation
Weak convergence of adaptive Markov chain Monte Carlo
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 30 April 2025, pp. 1318-1339
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Colouring random subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 28 April 2025, pp. 585-595
-
- Article
- Export citation
-
We study several basic problems about colouring the
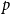 $p$-random subgraph
$p$-random subgraph 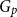 $G_p$ of an arbitrary graph
$G_p$ of an arbitrary graph 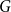 $G$, focusing primarily on the chromatic number and colouring number of
$G$, focusing primarily on the chromatic number and colouring number of 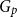 $G_p$. In particular, we show that there exist infinitely many
$G_p$. In particular, we show that there exist infinitely many 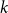 $k$-regular graphs
$k$-regular graphs 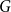 $G$ for which the colouring number (i.e., degeneracy) of
$G$ for which the colouring number (i.e., degeneracy) of 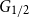 $G_{1/2}$ is at most
$G_{1/2}$ is at most 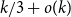 $k/3 + o(k)$ with high probability, thus disproving the natural prediction that such random graphs must have colouring number at least
$k/3 + o(k)$ with high probability, thus disproving the natural prediction that such random graphs must have colouring number at least 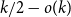 $k/2 - o(k)$.
$k/2 - o(k)$.
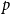
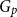
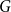
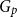
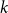
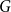
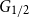
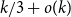
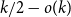
Coupling results and Markovian structures for number representations of continuous random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 28 April 2025, pp. 1340-1359
- Print publication:
- December 2025
-
- Article
- Export citation
-
Consider nested subdivisions of a bounded real set into intervals defining the digits
 $X_1,X_2,\ldots$ of a random variable X with a probability density function f. If f is almost everywhere lower semi-continuous, there is a non-negative integer-valued random variable N such that the distribution of
$X_1,X_2,\ldots$ of a random variable X with a probability density function f. If f is almost everywhere lower semi-continuous, there is a non-negative integer-valued random variable N such that the distribution of  $R=(X_{N+1},X_{N+2},\ldots)$ conditioned on
$R=(X_{N+1},X_{N+2},\ldots)$ conditioned on  $S=(X_1,\ldots,X_N)$ does not depend on f. If also the lengths of the intervals exhibit a Markovian structure,
$S=(X_1,\ldots,X_N)$ does not depend on f. If also the lengths of the intervals exhibit a Markovian structure,  $R\mid S$ becomes a Markov chain of a certain order
$R\mid S$ becomes a Markov chain of a certain order  $s\ge0$. If
$s\ge0$. If  $s=0$ then
$s=0$ then  $X_{N+1},X_{N+2},\ldots$ are independent and identically distributed with a known distribution. When
$X_{N+1},X_{N+2},\ldots$ are independent and identically distributed with a known distribution. When  $s>0$ and the Markov chain is uniformly geometric ergodic, there is a random time M such that the chain after time
$s>0$ and the Markov chain is uniformly geometric ergodic, there is a random time M such that the chain after time  $\max\{N,s\}+M-s$ is stationary and M follows a simple known distribution.
$\max\{N,s\}+M-s$ is stationary and M follows a simple known distribution.









Pricing and hedging for a sticky diffusion
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 28 April 2025, pp. 1235-1259
- Print publication:
- December 2025
-
- Article
- Export citation
-
We introduce a financial market model featuring a risky asset whose price follows a sticky geometric Brownian motion and a riskless asset that grows with a constant interest rate
 $r\in \mathbb R$. We prove that this model satisfies no arbitrage and no free lunch with vanishing risk only when
$r\in \mathbb R$. We prove that this model satisfies no arbitrage and no free lunch with vanishing risk only when  $r=0$. Under this condition, we derive the corresponding arbitrage-free pricing equation, assess the replicability, and give a representation of the replication strategy. We then show that all locally bounded replicable payoffs for the standard Black–Scholes model are also replicable for the sticky model. Last, we evaluate via numerical experiments the impact of hedging in discrete time and of misrepresenting price stickiness.
$r=0$. Under this condition, we derive the corresponding arbitrage-free pricing equation, assess the replicability, and give a representation of the replication strategy. We then show that all locally bounded replicable payoffs for the standard Black–Scholes model are also replicable for the sticky model. Last, we evaluate via numerical experiments the impact of hedging in discrete time and of misrepresenting price stickiness.



Markov Chains with Asymptotically Zero Drift
- Lamperti's Problem
-
- Published online:
- 24 April 2025
- Print publication:
- 08 May 2025
Influence of confining stress on different diameters of disc cutters in rock cutting
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Block–Savits type characterizations using the Laplace transform and some related issues
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 22 April 2025, pp. 1193-1215
- Print publication:
- September 2025
-
- Article
- Export citation
Please Advise Me: Advice Gap in the UK Working Party
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Please advise me: advice gap working party
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Algorithmic regulation at the city level in China
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reinstating trust in elections in the era of artificial intelligence and emerging technologies
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The epidemiology of acute gastrointestinal illness in Ethiopia, Mozambique, Nigeria, and Tanzania: a population survey
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e63
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Bibliography and Modern Book Production
- Notes and Sources for Student Librarians, Printers, Booksellers, Stationers, Book-collectors
-
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024
Spatiotemporal filtering modeling of hand, foot, and mouth disease: a case study from East China, 2009–2015
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 16 April 2025, e61
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improving healthcare cost prediction for chronic disease through covariate clustering and subgroup analysis methods
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 15 April 2025, pp. 374-394
- Print publication:
- May 2025
-
- Article
- Export citation
CONDITIONAL LIKELIHOOD RATIO TEST WITH MANY WEAK INSTRUMENTS
-
- Journal:
- Econometric Theory / Volume 42 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 15 April 2025, pp. 604-630
-
- Article
-
- You have access
- Open access
- Export citation
Advancing early warning mechanisms: an augmented intelligence-driven model for predicting multidimensional vulnerability levels in Afghanistan – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 14 April 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
