Refine search
Actions for selected content:
53172 results in Statistics and Probability
Limit laws for the generalized Zagreb indices of random graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 26 May 2025, pp. 1539-1558
- Print publication:
- December 2025
-
- Article
- Export citation
-
In this paper, we study the asymptotic behavior of the generalized Zagreb indices of the classical Erdős–Rényi (ER) random graph G(n, p), as
 $n\to\infty$. For any integer
$n\to\infty$. For any integer  $k\ge1$, we first give an expression for the kth-order generalized Zagreb index in terms of the number of star graphs of various sizes in any simple graph. The explicit formulas for the first two moments of the generalized Zagreb indices of an ER random graph are then obtained from this expression. Based on the asymptotic normality of the numbers of star graphs of various sizes, several joint limit laws are established for a finite number of generalized Zagreb indices with a phase transition for p in different regimes. Finally, we provide a necessary and sufficient condition for any single generalized Zagreb index of G(n, p) to be asymptotic normal.
$k\ge1$, we first give an expression for the kth-order generalized Zagreb index in terms of the number of star graphs of various sizes in any simple graph. The explicit formulas for the first two moments of the generalized Zagreb indices of an ER random graph are then obtained from this expression. Based on the asymptotic normality of the numbers of star graphs of various sizes, several joint limit laws are established for a finite number of generalized Zagreb indices with a phase transition for p in different regimes. Finally, we provide a necessary and sufficient condition for any single generalized Zagreb index of G(n, p) to be asymptotic normal.


Multivariate regular variation of preferential attachment models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 26 May 2025, pp. 1068-1100
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data for action – description of the automated COVID-19 surveillance system in Denmark and lessons learnt, January 2020 to June 2024 – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 23 May 2025, e64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bad decisions have consequences: how cyber security could fall victim to climate change
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 21 May 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Network polarization: The study of political attitudes and social ties as dynamic multilevel networks
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 21 May 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Partially Observed Markov Decision Processes
- Filtering, Learning and Controlled Sensing
-
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025

Scalable Monte Carlo for Bayesian Learning
-
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025
Exact solution to the Chow–Robbins game for almost all n, by using a catalan triangle
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 16 May 2025, pp. 1206-1241
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The payoff in the Chow–Robbins coin-tossing game is the proportion of heads when you stop. Stopping to maximize expectation was addressed by Chow and Robbins (1965), who proved there exist integers
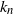 ${k_n}$ such that it is optimal to stop at n tosses when heads minus tails is
${k_n}$ such that it is optimal to stop at n tosses when heads minus tails is 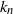 ${k_n}$. Finding
${k_n}$. Finding 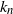 ${k_n}$ was unsolved except for finitely many cases by computer. We prove an
${k_n}$ was unsolved except for finitely many cases by computer. We prove an 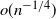 $o(n^{-1/4})$ estimate of the stopping boundary of Dvoretsky (1967), which then proves
$o(n^{-1/4})$ estimate of the stopping boundary of Dvoretsky (1967), which then proves  ${k_n} = \left\lceil {\alpha \sqrt n \,\, - 1/2\,\, + \,\,\frac{{\left( { - 2\zeta (\! -1/2)} \right)\sqrt \alpha }}{{\sqrt \pi }}{n^{ - 1/4}}} \right\rceil $ except for n in a set of density asymptotic to 0, at a power law rate. Here,
${k_n} = \left\lceil {\alpha \sqrt n \,\, - 1/2\,\, + \,\,\frac{{\left( { - 2\zeta (\! -1/2)} \right)\sqrt \alpha }}{{\sqrt \pi }}{n^{ - 1/4}}} \right\rceil $ except for n in a set of density asymptotic to 0, at a power law rate. Here,  $\alpha$ is the Shepp–Walker constant from the Brownian motion analog, and
$\alpha$ is the Shepp–Walker constant from the Brownian motion analog, and  $\zeta$ is Riemann’s zeta function. An
$\zeta$ is Riemann’s zeta function. An  $n^{ - 1/4}$ dependence was conjectured by Christensen and Fischer (2022). Our proof uses moments involving Catalan and Shapiro Catalan triangle numbers which appear in a tree resulting from backward induction, and a generalized backward induction principle. It was motivated by an idea of Häggström and Wästlund (2013) to use backward induction of upper and lower Value bounds from a horizon, which they used numerically to settle a few cases. Christensen and Fischer, with much better bounds, settled many more cases. We use Skorohod’s embedding to get simple upper and lower bounds from the Brownian analog; our upper bound is the one found by Christensen and Fischer in another way. We use them first for yet many more examples and a conjecture, then algebraically in the tree, with feedback to get much sharper Value bounds near the border, and analytic results. Also, we give a formula that gives the exact optimal stop rule for all n up to about a third of a billion; it uses the analytic result plus terms arrived at empirically.
$n^{ - 1/4}$ dependence was conjectured by Christensen and Fischer (2022). Our proof uses moments involving Catalan and Shapiro Catalan triangle numbers which appear in a tree resulting from backward induction, and a generalized backward induction principle. It was motivated by an idea of Häggström and Wästlund (2013) to use backward induction of upper and lower Value bounds from a horizon, which they used numerically to settle a few cases. Christensen and Fischer, with much better bounds, settled many more cases. We use Skorohod’s embedding to get simple upper and lower bounds from the Brownian analog; our upper bound is the one found by Christensen and Fischer in another way. We use them first for yet many more examples and a conjecture, then algebraically in the tree, with feedback to get much sharper Value bounds near the border, and analytic results. Also, we give a formula that gives the exact optimal stop rule for all n up to about a third of a billion; it uses the analytic result plus terms arrived at empirically.
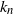
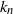
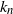
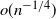




Short proof of the hypergraph container theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 5 / September 2025
- Published online by Cambridge University Press:
- 16 May 2025, pp. 621-624
-
- Article
- Export citation
Shedding light on Swiss health insurance costs in the last year of life
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 2 / July 2025
- Published online by Cambridge University Press:
- 15 May 2025, pp. 372-393
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nonparametric two-sample test for networks using joint graphon estimation
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 15 May 2025, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Covariate-adjusted functional data analysis for structural health monitoring
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 15 May 2025, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Missed opportunities in AI regulation: lessons from Canada’s AI and data act
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 15 May 2025, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stationary measures of continuous-time Markov chains with applications to stochastic reaction networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 14 May 2025, pp. 1031-1067
- Print publication:
- September 2025
-
- Article
- Export citation
-
We study continuous-time Markov chains on the nonnegative integers under mild regularity conditions (in particular, the set of jump vectors is finite and both forward and backward jumps are possible). Based on the so-called flux balance equation, we derive an iterative formula for calculating stationary measures. Specifically, a stationary measure
 $\pi(x)$ evaluated at
$\pi(x)$ evaluated at  $x\in\mathbb{N}_0$ is represented as a linear combination of a few generating terms, similarly to the characterization of a stationary measure of a birth–death process, where there is only one generating term,
$x\in\mathbb{N}_0$ is represented as a linear combination of a few generating terms, similarly to the characterization of a stationary measure of a birth–death process, where there is only one generating term,  $\pi(0)$. The coefficients of the linear combination are recursively determined in terms of the transition rates of the Markov chain. For the class of Markov chains we consider, there is always at least one stationary measure (up to a scaling constant). We give various results pertaining to uniqueness and nonuniqueness of stationary measures, and show that the dimension of the linear space of signed invariant measures is at most the number of generating terms. A minimization problem is constructed in order to compute stationary measures numerically. Moreover, a heuristic linear approximation scheme is suggested for the same purpose by first approximating the generating terms. The correctness of the linear approximation scheme is justified in some special cases. Furthermore, a decomposition of the state space into different types of states (open and closed irreducible classes, and trapping, escaping and neutral states) is presented. Applications to stochastic reaction networks are well illustrated.
$\pi(0)$. The coefficients of the linear combination are recursively determined in terms of the transition rates of the Markov chain. For the class of Markov chains we consider, there is always at least one stationary measure (up to a scaling constant). We give various results pertaining to uniqueness and nonuniqueness of stationary measures, and show that the dimension of the linear space of signed invariant measures is at most the number of generating terms. A minimization problem is constructed in order to compute stationary measures numerically. Moreover, a heuristic linear approximation scheme is suggested for the same purpose by first approximating the generating terms. The correctness of the linear approximation scheme is justified in some special cases. Furthermore, a decomposition of the state space into different types of states (open and closed irreducible classes, and trapping, escaping and neutral states) is presented. Applications to stochastic reaction networks are well illustrated.



Hausdorff moment transforms and their performance
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 13 May 2025, pp. 579-604
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Disinformation by design: leveraging solutions to combat misinformation in the Philippines’ 2025 election
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 13 May 2025, e39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of insurers’ technology accessibility as private information on market structure
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 13 May 2025, pp. 564-584
- Print publication:
- September 2025
-
- Article
- Export citation
A new approach in two-dimensional heavy-tailed distributions
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 2 / July 2025
- Published online by Cambridge University Press:
- 09 May 2025, pp. 317-349
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Insurance cycles detection using neural networks
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 2 / July 2025
- Published online by Cambridge University Press:
- 09 May 2025, pp. 350-371
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Asymptotics for Renewal Measure for Transient Markov Chain via Martingale Approach
-
- Book:
- Markov Chains with Asymptotically Zero Drift
- Published online:
- 24 April 2025
- Print publication:
- 08 May 2025, pp 191-220
-
- Chapter
- Export citation
