Refine search
Actions for selected content:
53172 results in Statistics and Probability
References
-
- Book:
- Dependence Models via Hierarchical Structures
- Published online:
- 20 March 2025
- Print publication:
- 27 March 2025, pp 132-134
-
- Chapter
- Export citation
Contents
-
- Book:
- Dependence Models via Hierarchical Structures
- Published online:
- 20 March 2025
- Print publication:
- 27 March 2025, pp vii-viii
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Dependence Models via Hierarchical Structures
- Published online:
- 20 March 2025
- Print publication:
- 27 March 2025, pp 1-22
-
- Chapter
-
- You have access
- Export citation
8 - Multivariate Dependent Sequences
-
- Book:
- Dependence Models via Hierarchical Structures
- Published online:
- 20 March 2025
- Print publication:
- 27 March 2025, pp 118-124
-
- Chapter
- Export citation
A large language model based data generation framework to improve mild cognitive impairment detection sensitivity
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 26 March 2025, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hamiltonicity of sparse pseudorandom graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 25 March 2025, pp. 596-620
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that every
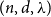 $(n,d,\lambda )$-graph contains a Hamilton cycle for sufficiently large
$(n,d,\lambda )$-graph contains a Hamilton cycle for sufficiently large  $n$, assuming that
$n$, assuming that 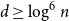 $d\geq \log ^{6}n$ and
$d\geq \log ^{6}n$ and 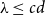 $\lambda \leq cd$, where
$\lambda \leq cd$, where 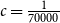 $c=\frac {1}{70000}$. This significantly improves a recent result of Glock, Correia, and Sudakov, who obtained a similar result for
$c=\frac {1}{70000}$. This significantly improves a recent result of Glock, Correia, and Sudakov, who obtained a similar result for 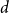 $d$ that grows polynomially with
$d$ that grows polynomially with  $n$. The proof is based on a new result regarding the second largest eigenvalue of the adjacency matrix of a subgraph induced by a random subset of vertices, combined with a recent result on connecting designated pairs of vertices by vertex-disjoint paths in
$n$. The proof is based on a new result regarding the second largest eigenvalue of the adjacency matrix of a subgraph induced by a random subset of vertices, combined with a recent result on connecting designated pairs of vertices by vertex-disjoint paths in 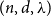 $(n,d,\lambda )$-graphs. We believe that the former result is of independent interest and will have further applications.
$(n,d,\lambda )$-graphs. We believe that the former result is of independent interest and will have further applications.
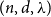

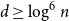
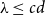
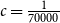

A central limit theorem for jump diffusion processes in the presence of round-off errors
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 25 March 2025, pp. 1242-1280
- Print publication:
- December 2025
-
- Article
- Export citation
-
Let X be the sum of a diffusion process and a Lévy jump process, and for any integer
 $n\ge 1$ let
$n\ge 1$ let 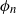 $\phi_n$ be a function defined on
$\phi_n$ be a function defined on  $\mathbb{R}^2$ and taking values in
$\mathbb{R}^2$ and taking values in  $\mathbb{R}$, with adequate properties. We study the convergence of functionals of the type where [x] is the integer part of the real number x and the sequences
$\mathbb{R}$, with adequate properties. We study the convergence of functionals of the type where [x] is the integer part of the real number x and the sequences \begin{align*} \Delta_n\sum_{i=1}^{[t/\Delta_n]} \phi_n\!\left(\alpha_n\left[\frac{X_{(i-1)\Delta_n}}{\alpha_n}\right], \:\frac{\alpha_n}{\sqrt{\Delta_n}}\left(\left[\frac{X_{i\Delta_n}}{\alpha_n}\right]-\left[\frac{X_{(i-1)\Delta_n}}{\alpha_n}\right]\right)\right),\end{align*}
\begin{align*} \Delta_n\sum_{i=1}^{[t/\Delta_n]} \phi_n\!\left(\alpha_n\left[\frac{X_{(i-1)\Delta_n}}{\alpha_n}\right], \:\frac{\alpha_n}{\sqrt{\Delta_n}}\left(\left[\frac{X_{i\Delta_n}}{\alpha_n}\right]-\left[\frac{X_{(i-1)\Delta_n}}{\alpha_n}\right]\right)\right),\end{align*} $(\Delta_n)$ and
$(\Delta_n)$ and  $(\alpha_n)$ tend to 0 as
$(\alpha_n)$ tend to 0 as  $n\to +\infty$. We then prove the law of large numbers and establish, in the case where
$n\to +\infty$. We then prove the law of large numbers and establish, in the case where  $\frac{\alpha_n}{\sqrt{\Delta_n}}$ converges to a real number in
$\frac{\alpha_n}{\sqrt{\Delta_n}}$ converges to a real number in  $[0,+\infty)$], a new central limit theorem which generalizes that in the case where X is a continuous Itô’s semimartingale.
$[0,+\infty)$], a new central limit theorem which generalizes that in the case where X is a continuous Itô’s semimartingale.









Optimal inventory control with state-dependent jumps
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 24 March 2025, pp. 1360-1391
- Print publication:
- December 2025
-
- Article
- Export citation
Global patterns and trends in deaths of influenza-associated lower respiratory infections from 1990 to 2019
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 24 March 2025, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cyber risk capital
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 24 March 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Consideration of the proxy modelling validation framework by the proxy modelling working party
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 24 March 2025, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The real-time growth rate of stochastic epidemics on random intersection graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 24 March 2025, pp. 1132-1155
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quantifying the direct and indirect components of COVID-19 vaccine effectiveness during the Delta variant era
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 24 March 2025, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robust mortality forecasting in the presence of outliers
-
- Journal:
- British Actuarial Journal / Volume 30 / 2025
- Published online by Cambridge University Press:
- 24 March 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Moderate deviations of many–server queues via idempotent processes – Corrigendum
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 24 March 2025, pp. 743-747
- Print publication:
- June 2025
-
- Article
-
- You have access
- HTML
- Export citation
Antimicrobial susceptibility of gram-negative strains isolated from bloodstream infections in China: Results from the study for monitoring antimicrobial resistance trends (SMART) 2018–2020
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 21 March 2025, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A note on digraph splitting
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 21 March 2025, pp. 559-564
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A tantalizing open problem, posed independently by Stiebitz in 1995 and by Alon in 1996 and again in 2006, asks whether for every pair of integers
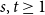 $s,t \ge 1$ there exists a finite number
$s,t \ge 1$ there exists a finite number 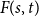 $F(s,t)$ such that the vertex set of every digraph of minimum out-degree at least
$F(s,t)$ such that the vertex set of every digraph of minimum out-degree at least 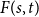 $F(s,t)$ can be partitioned into non-empty parts
$F(s,t)$ can be partitioned into non-empty parts 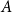 $A$ and
$A$ and 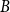 $B$ such that the subdigraphs induced on
$B$ such that the subdigraphs induced on 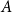 $A$ and
$A$ and 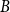 $B$ have minimum out-degree at least
$B$ have minimum out-degree at least  $s$ and
$s$ and 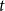 $t$, respectively.
$t$, respectively.In this short note, we prove that if
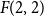 $F(2,2)$ exists, then all the numbers
$F(2,2)$ exists, then all the numbers 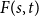 $F(s,t)$ with
$F(s,t)$ with 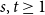 $s,t\ge 1$ exist and satisfy
$s,t\ge 1$ exist and satisfy 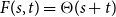 $F(s,t)=\Theta (s+t)$. In consequence, the problem of Alon and Stiebitz reduces to the case
$F(s,t)=\Theta (s+t)$. In consequence, the problem of Alon and Stiebitz reduces to the case 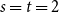 $s=t=2$. Moreover, the numbers
$s=t=2$. Moreover, the numbers 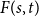 $F(s,t)$ with
$F(s,t)$ with 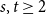 $s,t \ge 2$ either all exist and grow linearly, or all of them do not exist.
$s,t \ge 2$ either all exist and grow linearly, or all of them do not exist.
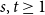
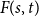
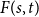

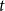
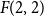
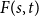
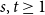
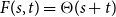
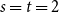
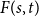
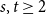
Joint mortality models based on subordinated linear hypercubes
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 21 March 2025, pp. 332-351
- Print publication:
- May 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TIME-VARYING COMPLETE SUBSET AVERAGING IN A DATA-RICH ENVIRONMENT
-
- Journal:
- Econometric Theory / Volume 42 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 21 March 2025, pp. 548-603
-
- Article
- Export citation
Invasive group a streptococcal infection associated with community healthcare services delivered at home, South East England, December 2021–2023: Descriptive epidemiological study
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 21 March 2025, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
