In this paper we propose an upward correction to the standard error (SE) estimation of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\hat{\theta}_{\mathrm{ML}}$\end{document} , the maximum likelihood (ML) estimate of the latent trait in item response theory (IRT). More specifically, the upward correction is provided for the SE of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\hat{\theta}_{\mathrm{ML}}$\end{document}
, the maximum likelihood (ML) estimate of the latent trait in item response theory (IRT). More specifically, the upward correction is provided for the SE of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\hat{\theta}_{\mathrm{ML}}$\end{document} when item parameter estimates obtained from an independent pretest sample are used in IRT scoring. When item parameter estimates are employed, the resulting latent trait estimate is called pseudo maximum likelihood (PML) estimate. Traditionally, the SE of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\hat{\theta}_{\mathrm{ML}}$\end{document}
when item parameter estimates obtained from an independent pretest sample are used in IRT scoring. When item parameter estimates are employed, the resulting latent trait estimate is called pseudo maximum likelihood (PML) estimate. Traditionally, the SE of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$\hat{\theta}_{\mathrm{ML}}$\end{document} is obtained on the basis of test information only, as if the item parameters are known. The upward correction takes into account the error that is carried over from the estimation of item parameters, in addition to the error in latent trait recovery itself. Our simulation study shows that both types of SE estimates are very good when θ is in the middle range of the latent trait distribution, but the upward-corrected SEs are more accurate than the traditional ones when θ takes more extreme values.
is obtained on the basis of test information only, as if the item parameters are known. The upward correction takes into account the error that is carried over from the estimation of item parameters, in addition to the error in latent trait recovery itself. Our simulation study shows that both types of SE estimates are very good when θ is in the middle range of the latent trait distribution, but the upward-corrected SEs are more accurate than the traditional ones when θ takes more extreme values.
Person fit statistics are frequently used to detect aberrant behavior when assuming an item response model generated the data. A common statistic, \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}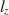 , has been shown in previous studies to perform well under a myriad of conditions. However, it is well-known that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
, has been shown in previous studies to perform well under a myriad of conditions. However, it is well-known that \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}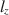 does not follow a standard normal distribution when using an estimated latent trait. As a result, corrections of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
does not follow a standard normal distribution when using an estimated latent trait. As a result, corrections of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}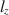 , called \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z^*$$\end{document}
, called \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z^*$$\end{document}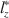 , have been proposed in the literature for specific item response models. We propose a more general correction that is applicable to many types of data, namely survey or tests with multiple item types and underlying latent constructs, which subsumes previous work done by others. In addition, we provide corrections for multiple estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta $$\end{document}
, have been proposed in the literature for specific item response models. We propose a more general correction that is applicable to many types of data, namely survey or tests with multiple item types and underlying latent constructs, which subsumes previous work done by others. In addition, we provide corrections for multiple estimators of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\theta $$\end{document}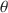 , the latent trait, including MLE, MAP and WLE. We provide analytical derivations that justifies our proposed correction, as well as simulation studies to examine the performance of the proposed correction with finite test lengths. An applied example is also provided to demonstrate proof of concept. We conclude with recommendations for practitioners when the asymptotic correction works well under different conditions and also future directions.
, the latent trait, including MLE, MAP and WLE. We provide analytical derivations that justifies our proposed correction, as well as simulation studies to examine the performance of the proposed correction with finite test lengths. An applied example is also provided to demonstrate proof of concept. We conclude with recommendations for practitioners when the asymptotic correction works well under different conditions and also future directions.
We report on an experimental study of turbulent Rayleigh–Bénard convection with asymmetric top and bottom plates. The plates are covered with pyramid-shaped roughness elements whose aspect ratios are  $\lambda =1$ or
$\lambda =1$ or  $\lambda =4$. In the low-Rayleigh-number regime (
$\lambda =4$. In the low-Rayleigh-number regime ( $Ra<1.9\times 10^9$), the heat transport efficiencies in the asymmetric cells, characterized by the Nusselt number, are smaller than those measured in a symmetric
$Ra<1.9\times 10^9$), the heat transport efficiencies in the asymmetric cells, characterized by the Nusselt number, are smaller than those measured in a symmetric  $\lambda = 1$ cell and are greater than those for a symmetric
$\lambda = 1$ cell and are greater than those for a symmetric  $\lambda = 4$ cell, whereas in the high-Rayleigh-number regime (
$\lambda = 4$ cell, whereas in the high-Rayleigh-number regime ( $Ra>1.9\times 10^9$), the Nusselt numbers of the asymmetric cells are, in turn, greater than those for the symmetric cell with
$Ra>1.9\times 10^9$), the Nusselt numbers of the asymmetric cells are, in turn, greater than those for the symmetric cell with  $\lambda = 1$ and smaller than those for the symmetric cell with
$\lambda = 1$ and smaller than those for the symmetric cell with  $\lambda = 4$. In addition, the heat transports of individual plates are studied based on the temperature drops across both halves of the cell. In the low-
$\lambda = 4$. In addition, the heat transports of individual plates are studied based on the temperature drops across both halves of the cell. In the low- $Ra$ regime, the
$Ra$ regime, the  $\lambda =1$ plate shows higher heat transfer than the
$\lambda =1$ plate shows higher heat transfer than the  $\lambda =4$ plate, while for the high-
$\lambda =4$ plate, while for the high- $Ra$ regime, the
$Ra$ regime, the  $\lambda =4$ plate shows a higher heat transport ability. In both regimes, the individual Nusselt number of the plate with lower heat transfer is insensitive to the topology of the other plate. Besides, it is found that the symmetry of the centre temperature distribution is robust to the symmetry breaking of boundary topographies. For the
$\lambda =4$ plate shows a higher heat transport ability. In both regimes, the individual Nusselt number of the plate with lower heat transfer is insensitive to the topology of the other plate. Besides, it is found that the symmetry of the centre temperature distribution is robust to the symmetry breaking of boundary topographies. For the  $Ra$ range explored, a weak temperature inversion is observed in the bulk of asymmetric rough cells. Finally, we remark that the temperature fluctuation at the cell centre and the Reynolds number associated with the large-scale circulation show universal power laws in terms of the flux Rayleigh number as
$Ra$ range explored, a weak temperature inversion is observed in the bulk of asymmetric rough cells. Finally, we remark that the temperature fluctuation at the cell centre and the Reynolds number associated with the large-scale circulation show universal power laws in terms of the flux Rayleigh number as  $\sigma _{T_{c}}\sim Ra_F^{0.68}$ and
$\sigma _{T_{c}}\sim Ra_F^{0.68}$ and  $Re_{LSC}\sim Ra_F^{0.36}$, respectively.
$Re_{LSC}\sim Ra_F^{0.36}$, respectively.

