Refine search
Actions for selected content:
26 results
8 - Supervised Learning
- from Part III - Machine Learning for Data Science
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 203-256
-
- Chapter
- Export citation
Implementation of support vector machines to classify abnormal neuronal response during emotion regulation at an individual level in patients with newly diagnosed bipolar disorder – and its association with subsequent functional changes and mood episodes
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 11 November 2025, e338
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
6 - Big Artificial Intelligence
-
- Book:
- Big Data in the Psychological Sciences
- Published online:
- 23 October 2025
- Print publication:
- 23 October 2025, pp 92-116
-
- Chapter
- Export citation
4 - Gaussian processes and other kernel methods
-
- Book:
- Machine Learning in Quantum Sciences
- Published online:
- 13 June 2025
- Print publication:
- 12 June 2025, pp 76-110
-
- Chapter
- Export citation
5 - Improving the Readability of Japanese Translations of Natural Disaster Risks Through Predictive Automated English Information Design
-
- Book:
- Multilingual Environmental Communications
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 104-133
-
- Chapter
- Export citation
Classification of internet addiction using machine learning on electroencephalography synchronization and functional connectivity
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 16 May 2025, e148
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing prosthetic hand control: A synergistic multi-channel electroencephalogram
-
- Journal:
- Wearable Technologies / Volume 5 / 2024
- Published online by Cambridge University Press:
- 28 November 2024, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Electromyogram (EMG) has been a fundamental approach for prosthetic hand control. However it is limited by the functionality of residual muscles and muscle fatigue. Currently, exploring temporal shifts in brain networks and accurately classifying noninvasive electroencephalogram (EEG) for prosthetic hand control remains challenging. In this manuscript, it is hypothesized that the coordinated and synchronized temporal patterns within the brain network, termed as brain synergy, contain valuable information to decode hand movements. 32-channel EEGs were acquired from 10 healthy participants during hand grasp and open. Synergistic spatial distribution pattern and power spectra of brain activity were investigated using independent component analysis of EEG. Out of 32 EEG channels, 15 channels spanning the frontal, central and parietal regions were strategically selected based on the synergy of spatial distribution pattern and power spectrum of independent components. Time-domain and synergistic features were extracted from the selected 15 EEG channels. These features were employed to train a Bayesian optimizer-based support vector machine (SVM). The optimized SVM classifier could achieve an average testing accuracy of 94.39
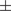 $ \pm $ .84% using synergistic features. The paired t-test showed that synergistic features yielded significantly higher area under curve values (p < .05) compared to time-domain features in classifying hand movements. The output of the classifier was employed for the control of the prosthetic hand. This synergistic approach for analyzing temporal activities in motor control and control of prosthetic hands have potential contributions to future research. It addresses the limitations of EMG-based approaches and emphasizes the effectiveness of synergy-based control for prostheses.
$ \pm $ .84% using synergistic features. The paired t-test showed that synergistic features yielded significantly higher area under curve values (p < .05) compared to time-domain features in classifying hand movements. The output of the classifier was employed for the control of the prosthetic hand. This synergistic approach for analyzing temporal activities in motor control and control of prosthetic hands have potential contributions to future research. It addresses the limitations of EMG-based approaches and emphasizes the effectiveness of synergy-based control for prostheses.
Moving to continuous classifications of bilingualism through machine learning trained on language production
-
- Journal:
- Bilingualism: Language and Cognition / Volume 28 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 24 May 2024, pp. 248-256
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COVID-19 cluster identification and support vector machine classifier model construction using global healthcare and socio-economic features
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 30 August 2023, e159
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
13 - Kernel Methods
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 440-472
-
- Chapter
- Export citation
Large-scale brain functional network abnormalities in social anxiety disorder
-
- Journal:
- Psychological Medicine / Volume 53 / Issue 13 / October 2023
- Published online by Cambridge University Press:
- 04 November 2022, pp. 6194-6204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Volume of hippocampus-amygdala transition area predicts outcomes of electroconvulsive therapy in major depressive disorder: high accuracy validated in two independent cohorts
-
- Journal:
- Psychological Medicine / Volume 53 / Issue 10 / July 2023
- Published online by Cambridge University Press:
- 23 May 2022, pp. 4464-4473
-
- Article
- Export citation
Evaluating the performance of machine learning models for automatic diagnosis of patients with schizophrenia based on a single site dataset of 440 participants
- Part of
-
- Journal:
- European Psychiatry / Volume 65 / Issue 1 / 2022
- Published online by Cambridge University Press:
- 23 December 2021, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multivariate classification provides a neural signature of Tourette disorder
-
- Journal:
- Psychological Medicine / Volume 53 / Issue 6 / April 2023
- Published online by Cambridge University Press:
- 03 November 2021, pp. 2361-2369
-
- Article
- Export citation
Distinguishing hypochondriasis and schizophrenia using regional homogeneity: a resting-state fMRI study and support vector machine analysis
-
- Journal:
- Acta Neuropsychiatrica / Volume 33 / Issue 4 / August 2021
- Published online by Cambridge University Press:
- 05 April 2021, pp. 182-190
-
- Article
- Export citation

Machine Learning for Speaker Recognition
-
- Published online:
- 26 June 2020
- Print publication:
- 19 November 2020
Improving speech emotion recognition based on acoustic words emotion dictionary
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 10 June 2020, pp. 747-761
-
- Article
- Export citation
Robust Wasserstein profile inference and applications to machine learning
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 01 October 2019, pp. 830-857
- Print publication:
- September 2019
-
- Article
- Export citation
Integrating LSA-based hierarchical conceptual space and machine learning methods for leveling the readability of domain-specific texts
-
- Journal:
- Natural Language Engineering / Volume 25 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 05 April 2019, pp. 331-361
-
- Article
- Export citation
