Refine search
Actions for selected content:
46 results
1 - Life and Times
- from Part I - Introduction
-
- Book:
- The Astronomy of Hipparchus
- Published online:
- 01 May 2026
- Print publication:
- 14 May 2026, pp 3-20
-
- Chapter
- Export citation
2 - Observation-Driven Science
-
- Book:
- Understanding Science
- Published online:
- 20 February 2026
- Print publication:
- 19 February 2026, pp 12-27
-
- Chapter
- Export citation
1 - What’s So Special about Science?
-
- Book:
- Understanding Science
- Published online:
- 20 February 2026
- Print publication:
- 19 February 2026, pp 1-11
-
- Chapter
- Export citation
Predicting Sunyaev-Zel’dovich effect observations of galaxy cluster cavities with the Square Kilometre Array
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e031
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Galaxy cluster X-ray cavities are inflated by relativistic jets that are ejected into the intracluster medium by active galactic nuclei (AGN). AGN jets prevent predicted cooling flow establishment at the cluster centre, and while this process is not well understood in existing studies, simulations have shown that the heating mechanism will depend on the type of gas that fills the cavities. Thermal and non-thermal distributions of electrons will produce different cavity Sunyaev Zel’dovich (SZ) effect signals, quantified by the ‘suppression factor’ f. This paper explores potential enhancements to prior constraints on the cavity gas type by simulating suppression factor observations with the Square Kilometre Array (SKA). Cluster cavities across different redshifts are observed to predict the optimum way of measuring f in future observations. We find that the SKA can constrain the suppression factor in the cavities of cluster MS 0735.6+7421 (MS0735) in as little as 4 h, with a smallest observable value of
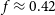 $f \approx 0.42$. Additionally, while the SKA may distinguish between possible thermal or non-thermal suppression factor values within the cavities of MS0735 if it observes for more than 8 h, determining the gas type of other clusters will likely require observations at multiple frequencies. The effect of cavity line of sight (LOS) position is also studied, and degeneracies between LOS position and the measured value of f are found. Finally, we find that for small cavities (radius < 80 kpc) at high redshift (
$f \approx 0.42$. Additionally, while the SKA may distinguish between possible thermal or non-thermal suppression factor values within the cavities of MS0735 if it observes for more than 8 h, determining the gas type of other clusters will likely require observations at multiple frequencies. The effect of cavity line of sight (LOS) position is also studied, and degeneracies between LOS position and the measured value of f are found. Finally, we find that for small cavities (radius < 80 kpc) at high redshift (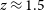 $z \approx 1.5$), the proposed high frequencies of the SKA (23.75–37.5 GHz) will be optimal, and that including MeerKAT antennas will improve all observations of this type.
$z \approx 1.5$), the proposed high frequencies of the SKA (23.75–37.5 GHz) will be optimal, and that including MeerKAT antennas will improve all observations of this type.
Observationally constrained estimates of the annual Arctic sea-ice volume budget 2010–2022
- Part of
-
- Journal:
- Annals of Glaciology / Volume 66 / 2025
- Published online by Cambridge University Press:
- 25 February 2025, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Sea-ice floating in the Arctic ocean is a constantly moving, growing and melting layer. The seasonal cycle of sea-ice volume has an average amplitude of
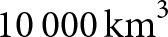 $10\,000\,\mathrm{km}^3$ or 9 trillion tonnes of sea ice. The role of dynamic redistribution of sea ice is observable during winter growth by the incorporation of satellite remote sensing of ice thickness, concentration and drift. Recent advances in the processing of CryoSat-2 radar altimetry data have allowed for the retrieval of summer sea-ice thickness. This allows for a full year of a purely remote sensing-derived ice volume budget analysis.
$10\,000\,\mathrm{km}^3$ or 9 trillion tonnes of sea ice. The role of dynamic redistribution of sea ice is observable during winter growth by the incorporation of satellite remote sensing of ice thickness, concentration and drift. Recent advances in the processing of CryoSat-2 radar altimetry data have allowed for the retrieval of summer sea-ice thickness. This allows for a full year of a purely remote sensing-derived ice volume budget analysis.Here, we present the closed volume budget of Arctic sea ice over the period October 2010–May 2022 revealing the key contributions to summer melt and minimum sea-ice volume and extent. We show the importance of ice drift to the inter-annual variability in Arctic sea-ice volume and the regional distribution of sea ice. The estimates of specific areas of sea-ice growth and melt provide key information on sea-ice over-production, the excess volume of ice growth compared to melt. The statistical accuracy of each key region of the Arctic is presented, revealing the current accuracy of knowledge of Arctic sea-ice volume from observational sources.
Chapter 3 - Early 1649
-
- Book:
- Milton's Ireland
- Published online:
- 14 November 2024
- Print publication:
- 12 December 2024, pp 81-103
-
- Chapter
- Export citation
The satellite threat to observational astronomy
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 20 / Issue S385 / December 2024
- Published online by Cambridge University Press:
- 19 January 2026, pp. 257-259
- Print publication:
- December 2024
-
- Article
- Export citation
Amateur astronomers’ perspectives on bright satellites in the age of megaconstellations: affected observations and willingness to act
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 20 / Issue S385 / December 2024
- Published online by Cambridge University Press:
- 19 January 2026, pp. 234-237
- Print publication:
- December 2024
-
- Article
- Export citation
3 - Basic Features of Clinical Assessment, Classification, and Diagnosis
-
- Book:
- Introduction to Clinical Psychology
- Published online:
- 31 October 2024
- Print publication:
- 31 October 2024, pp 50-77
-
- Chapter
- Export citation
Chapter 1 - What Is Ecology in Action?
- from Part I - Introduction and the Physical Environment
-
- Book:
- Ecology in Action
- Published online:
- 04 April 2024
- Print publication:
- 04 July 2024, pp 2-19
-
- Chapter
- Export citation

Early Modern Print Media and the Art of Observation
- Training the Literate Eye
-
- Published online:
- 14 March 2024
- Print publication:
- 04 April 2024
Measuring the global 21-cm signal with the MWA-II: improved characterisation of lunar-reflected radio frequency interference
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 40 / 2023
- Published online by Cambridge University Press:
- 08 November 2023, e055
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Radio interferometers can potentially detect the sky-averaged signal from the Cosmic Dawn (CD) and the Epoch of Reionisation (EoR) by studying the Moon as a thermal block to the foreground sky. The first step is to mitigate the Earth-based radio frequency interference (RFI) reflections (Earthshine) from the Moon, which significantly contaminate the FM band
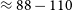 $\approx 88-110$ MHz, crucial to CD-EoR science. We analysed Murchison Widefield Array (MWA) phase I data from 72 to 180 MHz at 40 kHz resolution to understand the nature of Earthshine over three observing nights. We took two approaches to correct the Earthshine component from the Moon. In the first method, we mitigated the Earthshine using the flux density of the two components from the data, while in the second method, we used simulated flux density based on an FM catalogue to mitigate the Earthshine. Using these methods, we were able to recover the expected Galactic foreground temperature of the patch of sky obscured by the Moon. We performed a joint analysis of the Galactic foregrounds and the Moon’s intrinsic temperature
$\approx 88-110$ MHz, crucial to CD-EoR science. We analysed Murchison Widefield Array (MWA) phase I data from 72 to 180 MHz at 40 kHz resolution to understand the nature of Earthshine over three observing nights. We took two approaches to correct the Earthshine component from the Moon. In the first method, we mitigated the Earthshine using the flux density of the two components from the data, while in the second method, we used simulated flux density based on an FM catalogue to mitigate the Earthshine. Using these methods, we were able to recover the expected Galactic foreground temperature of the patch of sky obscured by the Moon. We performed a joint analysis of the Galactic foregrounds and the Moon’s intrinsic temperature 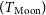 $(T_{\mathrm{Moon}})$ while assuming that the Moon has a constant thermal temperature throughout three epochs. We found
$(T_{\mathrm{Moon}})$ while assuming that the Moon has a constant thermal temperature throughout three epochs. We found 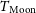 $T_{\mathrm{Moon}}$ to be at
$T_{\mathrm{Moon}}$ to be at 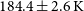 $184.4\pm{2.6}\,\mathrm{K}$ and
$184.4\pm{2.6}\,\mathrm{K}$ and 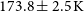 $173.8\pm{2.5}\,\mathrm{K}$ using the first and the second methods, respectively, and the best-fit values of the Galactic spectral index
$173.8\pm{2.5}\,\mathrm{K}$ using the first and the second methods, respectively, and the best-fit values of the Galactic spectral index 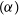 $(\alpha)$ to be within the 5% uncertainty level when compared with the global sky models. Compared with our previous work, these results improved constraints on the Galactic spectral index and the Moon’s intrinsic temperature. We also simulated the Earthshine at MWA between November and December 2023 to find suitable observing times less affected by the Earthshine. Such observing windows act as Earthshine avoidance and can be used to perform future global CD-EoR experiments using the Moon with the MWA.
$(\alpha)$ to be within the 5% uncertainty level when compared with the global sky models. Compared with our previous work, these results improved constraints on the Galactic spectral index and the Moon’s intrinsic temperature. We also simulated the Earthshine at MWA between November and December 2023 to find suitable observing times less affected by the Earthshine. Such observing windows act as Earthshine avoidance and can be used to perform future global CD-EoR experiments using the Moon with the MWA.
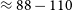
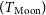
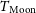
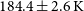
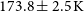
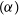
How do we design data sets for Machine Learning astronomy?
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 19 / Issue S368 / August 2023
- Published online by Cambridge University Press:
- 01 August 2025, pp. 11-27
- Print publication:
- August 2023
-
- Article
-
- You have access
- Open access
- Export citation
A Cross-Sectional Study and Observational Assessment of Shoppers’ COVID-19 Prevention Behaviors in Southwestern Ontario, Canada
-
- Journal:
- Disaster Medicine and Public Health Preparedness / Volume 17 / 2023
- Published online by Cambridge University Press:
- 08 May 2023, e384
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Skillful statistical prediction of subseasonal temperature by training on dynamical model data
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 23 February 2023, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 1 - Introduction
-
- Book:
- The Aging of Aquarius
- Published online:
- 15 December 2022
- Print publication:
- 22 December 2022, pp 1-12
-
- Chapter
- Export citation
Strong Lens Detection 2.0: Machine Learning and Transformer Models
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 18 / Issue S381 / December 2022
- Published online by Cambridge University Press:
- 04 March 2024, pp. 28-30
- Print publication:
- December 2022
-
- Article
-
- You have access
- Export citation
1 - Data Assimilation: General Background
- from Part I - General Background
-
- Book:
- Principles of Data Assimilation
- Published online:
- 22 September 2022
- Print publication:
- 29 September 2022, pp 3-34
-
- Chapter
- Export citation
10 - Bayesian Parameter Estimation and Reliability Updating
-
- Book:
- Structural and System Reliability
- Published online:
- 13 January 2022
- Print publication:
- 13 January 2022, pp 301-356
-
- Chapter
- Export citation
Chapter 8 - Ethnography and Routine Dynamics
- from Part II - Methodological Issues in Routine Dynamics Research
-
-
- Book:
- Cambridge Handbook of Routine Dynamics
- Published online:
- 11 December 2021
- Print publication:
- 16 December 2021, pp 103-129
-
- Chapter
- Export citation
