Refine search
Actions for selected content:
6974 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
References
-
- Book:
- Groups, Languages and Automata
- Published online:
- 16 March 2017
- Print publication:
- 23 February 2017, pp 270-282
-
- Chapter
- Export citation
14 - The co-word problem and the conjugacy problem
- from PART THREE - THE WORD PROBLEM
-
- Book:
- Groups, Languages and Automata
- Published online:
- 16 March 2017
- Print publication:
- 23 February 2017, pp 256-269
-
- Chapter
- Export citation
7 - Geodesics
- from PART TWO - FINITE STATE AUTOMATA AND GROUPS
-
- Book:
- Groups, Languages and Automata
- Published online:
- 16 March 2017
- Print publication:
- 23 February 2017, pp 169-183
-
- Chapter
- Export citation
6 - Hyperbolic groups
- from PART TWO - FINITE STATE AUTOMATA AND GROUPS
-
- Book:
- Groups, Languages and Automata
- Published online:
- 16 March 2017
- Print publication:
- 23 February 2017, pp 150-168
-
- Chapter
- Export citation
Forbidden Hypermatrices Imply General Bounds on Induced Forbidden Subposet Problems
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 4 / July 2017
- Published online by Cambridge University Press:
- 15 February 2017, pp. 593-602
-
- Article
- Export citation
-
We prove that for every poset P, there is a constant CP such that the size of any family of subsets of {1, 2, . . ., n} that does not contain P as an induced subposet is at most
settling a conjecture of Katona, and Lu and Milans. We obtain this bound by establishing a connection to the theory of forbidden submatrices and then applying a higher-dimensional variant of the Marcus–Tardos theorem, proved by Klazar and Marcus. We also give a new proof of their result.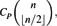 $$C_P{\binom{n}{\lfloor\gfrac{n}{2}\rfloor}},$$
$$C_P{\binom{n}{\lfloor\gfrac{n}{2}\rfloor}},$$
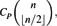
A Rainbow r-Partite Version of the Erdős–Ko–Rado Theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 3 / May 2017
- Published online by Cambridge University Press:
- 23 January 2017, pp. 321-337
-
- Article
- Export citation
The Minimum Number of Triangular Edges and a Symmetrization Method for Multiple Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 4 / July 2017
- Published online by Cambridge University Press:
- 23 January 2017, pp. 525-535
-
- Article
- Export citation

Random Graphs and Complex Networks
-
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016
On the Number of 4-Edge Paths in Graphs With Given Edge Density
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 3 / May 2017
- Published online by Cambridge University Press:
- 23 December 2016, pp. 431-447
-
- Article
- Export citation

Introduction to Coalgebra
- Towards Mathematics of States and Observation
-
- Published online:
- 22 December 2016
- Print publication:
- 27 October 2016
Intermezzo: Back to Real-World Networks …
- from Part III - Models for Complex Networks
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 179-182
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 1-54
-
- Chapter
-
- You have access
- Export citation
Glossary
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 304-305
-
- Chapter
- Export citation
Course Outline
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp xv-xvi
-
- Chapter
- Export citation
Contents
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp vii-x
-
- Chapter
- Export citation
3 - Branching Processes
- from Part I - Preliminaries
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 87-114
-
- Chapter
- Export citation
2 - Probabilistic Methods
- from Part I - Preliminaries
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 57-86
-
- Chapter
- Export citation
Dedication
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp v-vi
-
- Chapter
- Export citation
References
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 306-316
-
- Chapter
- Export citation
4 - Phase Transition for the Erdős-Rényi Random Graph
- from Part II - Basic Models
-
- Book:
- Random Graphs and Complex Networks
- Published online:
- 12 January 2017
- Print publication:
- 22 December 2016, pp 117-149
-
- Chapter
- Export citation
