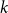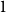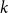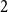Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
13 - Interaction between Initial Algebras and Terminal Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 461-476
-
- Chapter
- Export citation
Extending Wormald’s differential equation method to one-sided bounds
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 06 February 2025, pp. 545-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
10 - Fixed Points Determined by Finite Behaviour
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 319-362
-
- Chapter
- Export citation
2 - Algebras and Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 12-64
-
- Chapter
- Export citation
Index
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 618-626
-
- Chapter
- Export citation
9 - State Minimality and Well-Pointed Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 293-318
-
- Chapter
- Export citation
6 - Transfinite Iteration
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 167-214
-
- Chapter
- Export citation
4 - Finitary Set Functors
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 90-132
-
- Chapter
- Export citation
5 - Finitary Iteration in Enriched Settings
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 133-166
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 1-11
-
- Chapter
-
- You have access
- Export citation
Frontmatter
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp i-iv
-
- Chapter
- Export citation
Appendix A - Functors with Initial Algebras or Terminal Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 537-540
-
- Chapter
- Export citation
Appendix C - Set Functors
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 552-597
-
- Chapter
- Export citation
Appendix B - A Primer on Fixed Points in Ordered and Metric Structures
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 541-551
-
- Chapter
- Export citation
References
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 598-616
-
- Chapter
- Export citation
14 - Derived Functors
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 477-509
-
- Chapter
- Export citation
Dedication
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp v-vi
-
- Chapter
- Export citation
List of Categories
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 617-617
-
- Chapter
- Export citation
12 - Liftings and Extensions from Set
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 398-460
-
- Chapter
- Export citation
Satisfiability thresholds for regular occupation problems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 04 February 2025, pp. 491-527
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In the last two decades the study of random instances of constraint satisfaction problems (CSPs) has flourished across several disciplines, including computer science, mathematics and physics. The diversity of the developed methods, on the rigorous and non-rigorous side, has led to major advances regarding both the theoretical as well as the applied viewpoints. Based on a ceteris paribus approach in terms of the density evolution equations known from statistical physics, we focus on a specific prominent class of regular CSPs, the so-called occupation problems, and in particular on
 $r$-in-
$r$-in-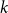 $k$ occupation problems. By now, out of these CSPs only the satisfiability threshold – the largest degree for which the problem admits asymptotically a solution – for the
$k$ occupation problems. By now, out of these CSPs only the satisfiability threshold – the largest degree for which the problem admits asymptotically a solution – for the 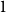 $1$-in-
$1$-in-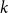 $k$ occupation problem has been rigorously established. Here we determine the satisfiability threshold of the
$k$ occupation problem has been rigorously established. Here we determine the satisfiability threshold of the 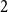 $2$-in-
$2$-in-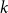 $k$ occupation problem for all
$k$ occupation problem for all 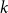 $k$. In the proof we exploit the connection of an associated optimization problem regarding the overlap of satisfying assignments to a fixed point problem inspired by belief propagation, a message passing algorithm developed for solving such CSPs.
$k$. In the proof we exploit the connection of an associated optimization problem regarding the overlap of satisfying assignments to a fixed point problem inspired by belief propagation, a message passing algorithm developed for solving such CSPs.