Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Critical configurations of the hard-core model on square grid graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 04 February 2025, pp. 445-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the hard-core model on a finite square grid graph with stochastic Glauber dynamics parametrized by the inverse temperature
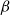 $\beta$. We investigate how the transition between its two maximum-occupancy configurations takes place in the low-temperature regime
$\beta$. We investigate how the transition between its two maximum-occupancy configurations takes place in the low-temperature regime 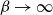 $\beta \to \infty$ in the case of periodic boundary conditions. The hard-core constraints and the grid symmetry make the structure of the critical configurations for this transition, also known as essential saddles, very rich and complex. We provide a comprehensive geometrical characterization of these configurations that together constitute a bottleneck for the Glauber dynamics in the low-temperature limit. In particular, we develop a novel isoperimetric inequality for hard-core configurations with a fixed number of particles and show how the essential saddles are characterized not only by the number of particles but also their geometry.
$\beta \to \infty$ in the case of periodic boundary conditions. The hard-core constraints and the grid symmetry make the structure of the critical configurations for this transition, also known as essential saddles, very rich and complex. We provide a comprehensive geometrical characterization of these configurations that together constitute a bottleneck for the Glauber dynamics in the low-temperature limit. In particular, we develop a novel isoperimetric inequality for hard-core configurations with a fixed number of particles and show how the essential saddles are characterized not only by the number of particles but also their geometry.

Initial Algebras and Terminal Coalgebras
- The Theory of Fixed Points of Functors
-
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025
On perfect subdivision tilings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 27 January 2025, pp. 421-444
-
- Article
- Export citation
-
For a given graph
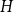 $H$, we say that a graph
$H$, we say that a graph 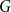 $G$ has a perfect
$G$ has a perfect 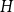 $H$-subdivision tiling if
$H$-subdivision tiling if 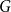 $G$ contains a collection of vertex-disjoint subdivisions of
$G$ contains a collection of vertex-disjoint subdivisions of 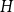 $H$ covering all vertices of
$H$ covering all vertices of 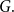 $G.$ Let
$G.$ Let 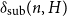 $\delta _{\mathrm {sub}}(n, H)$ be the smallest integer
$\delta _{\mathrm {sub}}(n, H)$ be the smallest integer 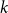 $k$ such that any
$k$ such that any  $n$-vertex graph
$n$-vertex graph 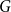 $G$ with minimum degree at least
$G$ with minimum degree at least 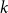 $k$ has a perfect
$k$ has a perfect 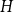 $H$-subdivision tiling. For every graph
$H$-subdivision tiling. For every graph 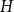 $H$, we asymptotically determined the value of
$H$, we asymptotically determined the value of 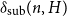 $\delta _{\mathrm {sub}}(n, H)$. More precisely, for every graph
$\delta _{\mathrm {sub}}(n, H)$. More precisely, for every graph 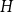 $H$ with at least one edge, there is an integer
$H$ with at least one edge, there is an integer 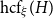 $\mathrm {hcf}_{\xi }(H)$ and a constant
$\mathrm {hcf}_{\xi }(H)$ and a constant 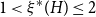 $1 \lt \xi ^*(H)\leq 2$ that can be explicitly determined by structural properties of
$1 \lt \xi ^*(H)\leq 2$ that can be explicitly determined by structural properties of 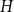 $H$ such that
$H$ such that 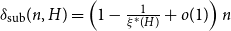 $\delta _{\mathrm {sub}}(n, H) = \left (1 - \frac {1}{\xi ^*(H)} + o(1) \right )n$ holds for all
$\delta _{\mathrm {sub}}(n, H) = \left (1 - \frac {1}{\xi ^*(H)} + o(1) \right )n$ holds for all  $n$ and
$n$ and 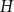 $H$ unless
$H$ unless 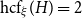 $\mathrm {hcf}_{\xi }(H) = 2$ and
$\mathrm {hcf}_{\xi }(H) = 2$ and  $n$ is odd. When
$n$ is odd. When 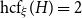 $\mathrm {hcf}_{\xi }(H) = 2$ and
$\mathrm {hcf}_{\xi }(H) = 2$ and  $n$ is odd, then we show that
$n$ is odd, then we show that 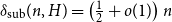 $\delta _{\mathrm {sub}}(n, H) = \left (\frac {1}{2} + o(1) \right )n$.
$\delta _{\mathrm {sub}}(n, H) = \left (\frac {1}{2} + o(1) \right )n$.
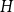
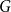
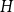
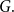
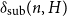
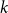

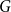
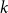
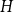
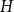
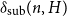
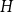
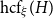
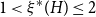
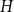
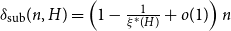

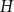
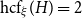

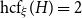

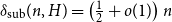
Hypergraph independence polynomials with a zero close to the origin
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 22 January 2025, pp. 486-490
-
- Article
- Export citation
-
For each uniformity
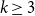 $k \geq 3$, we construct
$k \geq 3$, we construct 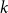 $k$ uniform linear hypergraphs
$k$ uniform linear hypergraphs 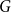 $G$ with arbitrarily large maximum degree
$G$ with arbitrarily large maximum degree 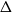 $\Delta$ whose independence polynomial
$\Delta$ whose independence polynomial 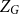 $Z_G$ has a zero
$Z_G$ has a zero 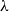 $\lambda$ with
$\lambda$ with 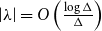 $\left \vert \lambda \right \vert = O\left (\frac {\log \Delta }{\Delta }\right )$. This disproves a recent conjecture of Galvin, McKinley, Perkins, Sarantis, and Tetali.
$\left \vert \lambda \right \vert = O\left (\frac {\log \Delta }{\Delta }\right )$. This disproves a recent conjecture of Galvin, McKinley, Perkins, Sarantis, and Tetali.
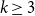
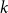
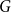
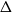
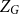
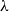
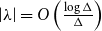
Structural convergence and algebraic roots
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 23 December 2024, pp. 392-400
-
- Article
- Export citation
-
Structural convergence is a framework for the convergence of graphs by Nešetřil and Ossona de Mendez that unifies the dense (left) graph convergence and Benjamini-Schramm convergence. They posed a problem asking whether for a given sequence of graphs
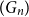 $(G_n)$ converging to a limit
$(G_n)$ converging to a limit 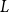 $L$ and a vertex
$L$ and a vertex  $r$ of
$r$ of 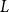 $L$, it is possible to find a sequence of vertices
$L$, it is possible to find a sequence of vertices 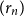 $(r_n)$ such that
$(r_n)$ such that 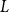 $L$ rooted at
$L$ rooted at  $r$ is the limit of the graphs
$r$ is the limit of the graphs 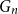 $G_n$ rooted at
$G_n$ rooted at 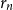 $r_n$. A counterexample was found by Christofides and Král’, but they showed that the statement holds for almost all vertices
$r_n$. A counterexample was found by Christofides and Král’, but they showed that the statement holds for almost all vertices  $r$ of
$r$ of 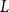 $L$. We offer another perspective on the original problem by considering the size of definable sets to which the root
$L$. We offer another perspective on the original problem by considering the size of definable sets to which the root  $r$ belongs. We prove that if
$r$ belongs. We prove that if  $r$ is an algebraic vertex (i.e. belongs to a finite definable set), the sequence of roots
$r$ is an algebraic vertex (i.e. belongs to a finite definable set), the sequence of roots 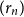 $(r_n)$ always exists.
$(r_n)$ always exists.
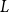

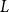
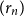
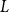

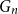
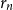

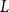


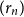

Data Structures and Algorithms in Java
- A Project-Based Approach
-
- Published online:
- 19 December 2024
- Print publication:
- 31 October 2024
-
- Textbook
- Export citation
Essential covers of the hypercube require many hyperplanes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 16 December 2024, pp. 326-337
-
- Article
- Export citation
-
We prove a new lower bound for the almost 20-year-old problem of determining the smallest possible size of an essential cover of the
 $n$-dimensional hypercube
$n$-dimensional hypercube 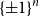 $\{\pm 1\}^n$, that is, the smallest possible size of a collection of hyperplanes that forms a minimal cover of
$\{\pm 1\}^n$, that is, the smallest possible size of a collection of hyperplanes that forms a minimal cover of 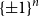 $\{\pm 1\}^n$ and such that, furthermore, every variable appears with a non-zero coefficient in at least one of the hyperplane equations. We show that such an essential cover must consist of at least
$\{\pm 1\}^n$ and such that, furthermore, every variable appears with a non-zero coefficient in at least one of the hyperplane equations. We show that such an essential cover must consist of at least 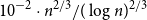 $10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$ hyperplanes, improving previous lower bounds of Linial–Radhakrishnan, of Yehuda–Yehudayoff, and of Araujo–Balogh–Mattos.
$10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$ hyperplanes, improving previous lower bounds of Linial–Radhakrishnan, of Yehuda–Yehudayoff, and of Araujo–Balogh–Mattos.

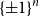
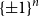
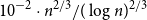
Tree universality in positional games
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 13 December 2024, pp. 338-358
-
- Article
- Export citation
-
In this paper we consider positional games where the winning sets are edge sets of tree-universal graphs. Specifically, we show that in the unbiased Maker-Breaker game on the edges of the complete graph
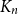 $K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most
$K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most 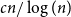 $cn/\log (n)$, for a suitable constant
$cn/\log (n)$, for a suitable constant  $c$ and
$c$ and  $n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
$n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
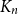
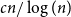


Twin-width of sparse random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 11 December 2024, pp. 401-420
-
- Article
- Export citation
-
We show that the twin-width of every
 $n$-vertex
$n$-vertex 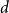 $d$-regular graph is at most
$d$-regular graph is at most 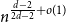 $n^{\frac{d-2}{2d-2}+o(1)}$ for any fixed integer
$n^{\frac{d-2}{2d-2}+o(1)}$ for any fixed integer 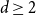 $d \geq 2$ and that almost all
$d \geq 2$ and that almost all 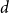 $d$-regular graphs attain this bound. More generally, we obtain bounds on the twin-width of sparse Erdős–Renyi and regular random graphs, complementing the bounds in the denser regime due to Ahn, Chakraborti, Hendrey, Kim, and Oum.
$d$-regular graphs attain this bound. More generally, we obtain bounds on the twin-width of sparse Erdős–Renyi and regular random graphs, complementing the bounds in the denser regime due to Ahn, Chakraborti, Hendrey, Kim, and Oum.

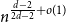
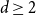
Tight bound for the Erdős–Pósa property of tree minors
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 11 December 2024, pp. 321-325
-
- Article
- Export citation
-
Let
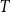 $T$ be a tree on
$T$ be a tree on  $t$ vertices. We prove that for every positive integer
$t$ vertices. We prove that for every positive integer 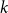 $k$ and every graph
$k$ and every graph 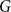 $G$, either
$G$, either 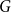 $G$ contains
$G$ contains 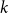 $k$ pairwise vertex-disjoint subgraphs each having a
$k$ pairwise vertex-disjoint subgraphs each having a 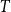 $T$ minor, or there exists a set
$T$ minor, or there exists a set 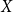 $X$ of at most
$X$ of at most 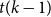 $t(k-1)$ vertices of
$t(k-1)$ vertices of 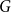 $G$ such that
$G$ such that 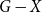 $G-X$ has no
$G-X$ has no 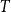 $T$ minor. The bound on the size of
$T$ minor. The bound on the size of 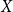 $X$ is best possible and improves on an earlier
$X$ is best possible and improves on an earlier 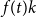 $f(t)k$ bound proved by Fiorini, Joret, and Wood (2013) with some fast-growing function
$f(t)k$ bound proved by Fiorini, Joret, and Wood (2013) with some fast-growing function 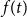 $f(t)$. Moreover, our proof is short and simple.
$f(t)$. Moreover, our proof is short and simple.
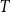

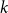
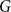
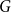
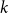
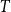
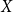
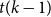
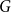
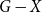
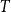
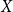
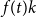
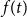
Sampling from the random cluster model on random regular graphs at all temperatures via Glauber dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 359-391
-
- Article
- Export citation
-
We consider the performance of Glauber dynamics for the random cluster model with real parameter
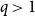 $q\gt 1$ and temperature
$q\gt 1$ and temperature 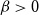 $\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random
$\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random 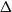 $\Delta$-regular graphs for all sufficiently large
$\Delta$-regular graphs for all sufficiently large 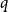 $q$ and obtained an efficient sampling algorithm for all temperatures
$q$ and obtained an efficient sampling algorithm for all temperatures 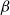 $\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large
$\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large 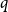 $q$ (with respect to
$q$ (with respect to 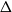 $\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures
$\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures 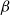 $\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
$\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
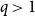
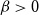
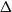
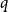
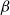
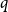
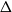
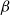
1 - Introduction
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 1-21
-
- Chapter
- Export citation
Preface
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp v-x
-
- Chapter
- Export citation
6 - Asymmetric Graph TSP
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 114-133
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp i-iv
-
- Chapter
- Export citation
10 - Parity Correction of Random Trees
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 212-230
-
- Chapter
- Export citation
Contents
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp xi-xiv
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 407-422
-
- Chapter
- Export citation
Index
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 423-428
-
- Chapter
- Export citation
16 - Path TSP by Dynamic Programming
-
- Book:
- Approximation Algorithms for Traveling Salesman Problems
- Published online:
- 14 November 2024
- Print publication:
- 05 December 2024, pp 351-380
-
- Chapter
- Export citation
