Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Preface
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp xi-xii
-
- Chapter
- Export citation
Contents
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp vii-x
-
- Chapter
- Export citation
3 - Elementary Operations and Properties
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 92-102
-
- Chapter
- Export citation
Dedication
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp v-vi
-
- Chapter
- Export citation
Index
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 317-322
-
- Chapter
- Export citation
6 - Single-Element Extensions
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 158-213
-
- Chapter
- Export citation
References
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 310-316
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp i-iv
-
- Chapter
- Export citation
9 - Subdivisions and Triangulations
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 258-295
-
- Chapter
- Export citation
4 - The Topological Representation Theorem
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 103-135
-
- Chapter
- Export citation
Hamiltonicity of sparse pseudorandom graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 25 March 2025, pp. 596-620
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that every
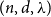 $(n,d,\lambda )$-graph contains a Hamilton cycle for sufficiently large
$(n,d,\lambda )$-graph contains a Hamilton cycle for sufficiently large  $n$, assuming that
$n$, assuming that 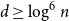 $d\geq \log ^{6}n$ and
$d\geq \log ^{6}n$ and 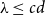 $\lambda \leq cd$, where
$\lambda \leq cd$, where 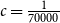 $c=\frac {1}{70000}$. This significantly improves a recent result of Glock, Correia, and Sudakov, who obtained a similar result for
$c=\frac {1}{70000}$. This significantly improves a recent result of Glock, Correia, and Sudakov, who obtained a similar result for 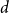 $d$ that grows polynomially with
$d$ that grows polynomially with  $n$. The proof is based on a new result regarding the second largest eigenvalue of the adjacency matrix of a subgraph induced by a random subset of vertices, combined with a recent result on connecting designated pairs of vertices by vertex-disjoint paths in
$n$. The proof is based on a new result regarding the second largest eigenvalue of the adjacency matrix of a subgraph induced by a random subset of vertices, combined with a recent result on connecting designated pairs of vertices by vertex-disjoint paths in 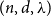 $(n,d,\lambda )$-graphs. We believe that the former result is of independent interest and will have further applications.
$(n,d,\lambda )$-graphs. We believe that the former result is of independent interest and will have further applications.
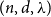

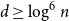
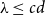
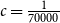

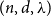
A note on digraph splitting
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 21 March 2025, pp. 559-564
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A tantalizing open problem, posed independently by Stiebitz in 1995 and by Alon in 1996 and again in 2006, asks whether for every pair of integers
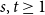 $s,t \ge 1$ there exists a finite number
$s,t \ge 1$ there exists a finite number 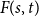 $F(s,t)$ such that the vertex set of every digraph of minimum out-degree at least
$F(s,t)$ such that the vertex set of every digraph of minimum out-degree at least 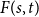 $F(s,t)$ can be partitioned into non-empty parts
$F(s,t)$ can be partitioned into non-empty parts 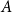 $A$ and
$A$ and 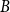 $B$ such that the subdigraphs induced on
$B$ such that the subdigraphs induced on 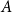 $A$ and
$A$ and 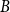 $B$ have minimum out-degree at least
$B$ have minimum out-degree at least  $s$ and
$s$ and 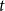 $t$, respectively.
$t$, respectively.In this short note, we prove that if
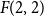 $F(2,2)$ exists, then all the numbers
$F(2,2)$ exists, then all the numbers 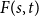 $F(s,t)$ with
$F(s,t)$ with 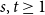 $s,t\ge 1$ exist and satisfy
$s,t\ge 1$ exist and satisfy 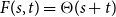 $F(s,t)=\Theta (s+t)$. In consequence, the problem of Alon and Stiebitz reduces to the case
$F(s,t)=\Theta (s+t)$. In consequence, the problem of Alon and Stiebitz reduces to the case 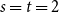 $s=t=2$. Moreover, the numbers
$s=t=2$. Moreover, the numbers 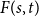 $F(s,t)$ with
$F(s,t)$ with 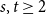 $s,t \ge 2$ either all exist and grow linearly, or all of them do not exist.
$s,t \ge 2$ either all exist and grow linearly, or all of them do not exist.
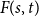
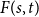
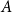
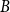
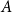
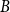

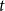
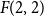
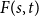
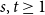
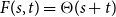
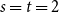
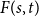
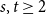
Face enumeration for split matroid polytopes
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 07 February 2025, pp. 528-544
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper initiates the explicit study of face numbers of matroid polytopes and their computation. We prove that, for the large class of split matroid polytopes, their face numbers depend solely on the number of cyclic flats of each rank and size, together with information on the modular pairs of cyclic flats. We provide a formula which allows us to calculate
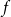 $f$-vectors without the need of taking convex hulls or computing face lattices. We discuss the particular cases of sparse paving matroids and rank two matroids, which are of independent interest due to their appearances in other combinatorial and geometric settings.
$f$-vectors without the need of taking convex hulls or computing face lattices. We discuss the particular cases of sparse paving matroids and rank two matroids, which are of independent interest due to their appearances in other combinatorial and geometric settings.
7 - Terminal Coalgebras as Algebras, Initial Algebras as Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 215-252
-
- Chapter
- Export citation
8 - Well-Founded Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 253-292
-
- Chapter
- Export citation
11 - Sufficient Conditions for Initial Algebras and Terminal Coalgebras
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 363-397
-
- Chapter
- Export citation
Preface
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp xi-xiv
-
- Chapter
- Export citation
Contents
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp vii-x
-
- Chapter
- Export citation
3 - Finitary Iteration
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 65-89
-
- Chapter
- Export citation
15 - Special Topics
-
- Book:
- Initial Algebras and Terminal Coalgebras
- Published online:
- 30 January 2025
- Print publication:
- 06 February 2025, pp 510-536
-
- Chapter
- Export citation
