Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry

Elements of Automata Theory
-
- Published online:
- 05 September 2013
- Print publication:
- 01 October 2009

Sets and Proofs
-
- Published online:
- 05 September 2013
- Print publication:
- 17 June 1999
Relative Tutte Polynomials of Tensor Products of Coloured Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 04 September 2013, pp. 801-828
-
- Article
- Export citation
CPC volume 22 issue 5 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 08 August 2013, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Degree Conditions for H-Linked Digraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 08 August 2013, pp. 684-699
-
- Article
- Export citation
Almost Spanning Subgraphs of Random Graphs After Adversarial Edge Removal
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 08 August 2013, pp. 639-683
-
- Article
- Export citation
-
Let Δ ≥ 2 be a fixed integer. We show that the random graph
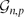 ${\mathcal{G}_{n,p}}$ with
${\mathcal{G}_{n,p}}$ with 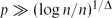 $p\gg (\log n/n)^{1/\Delta}$ is robust with respect to the containment of almost spanning bipartite graphs H with maximum degree Δ and sublinear bandwidth in the following sense: asymptotically almost surely, if an adversary deletes arbitrary edges from ${\mathcal{G}_{n,p}}$ in such a way that each vertex loses less than half of its neighbours, then the resulting graph still contains a copy of all such H.
$p\gg (\log n/n)^{1/\Delta}$ is robust with respect to the containment of almost spanning bipartite graphs H with maximum degree Δ and sublinear bandwidth in the following sense: asymptotically almost surely, if an adversary deletes arbitrary edges from ${\mathcal{G}_{n,p}}$ in such a way that each vertex loses less than half of its neighbours, then the resulting graph still contains a copy of all such H.
CPC volume 22 issue 5 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 08 August 2013, pp. b1-b9
-
- Article
-
- You have access
- Export citation

Complexity: Knots, Colourings and Countings
-
- Published online:
- 05 August 2013
- Print publication:
- 12 August 1993
Counting Plane Graphs: Cross-Graph Charging Schemes
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 6 / November 2013
- Published online by Cambridge University Press:
- 25 July 2013, pp. 935-954
-
- Article
- Export citation
On the Non-Planarity of a Random Subgraph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 22 July 2013, pp. 722-732
-
- Article
- Export citation
-
Let G be a finite graph with minimum degree r. Form a random subgraph Gp of G by taking each edge of G into Gp independently and with probability p. We prove that for any constant ε > 0, if
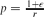 $p=\frac{1+\epsilon}{r}$, then Gp is non-planar with probability approaching 1 as r grows. This generalizes classical results on planarity of binomial random graphs.
$p=\frac{1+\epsilon}{r}$, then Gp is non-planar with probability approaching 1 as r grows. This generalizes classical results on planarity of binomial random graphs.
The Min Mean-Weight Cycle in a Random Network
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 22 July 2013, pp. 763-782
-
- Article
- Export citation
Forbidden Subgraphs Generating Almost the Same Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 11 July 2013, pp. 733-748
-
- Article
- Export citation
-
Let
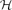 $\mathcal{H}$ be a set of connected graphs. A graph G is said to be $\mathcal{H}$-free if G does not contain any element of $\mathcal{H}$ as an induced subgraph. Let
$\mathcal{H}$ be a set of connected graphs. A graph G is said to be $\mathcal{H}$-free if G does not contain any element of $\mathcal{H}$ as an induced subgraph. Let 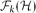 $\mathcal{F}_{k}(\mathcal{H})$ be the set of k-connected $\mathcal{H}$-free graphs. When we study the relationship between forbidden subgraphs and a certain graph property, we often allow a finite exceptional set of graphs. But if the symmetric difference of
$\mathcal{F}_{k}(\mathcal{H})$ be the set of k-connected $\mathcal{H}$-free graphs. When we study the relationship between forbidden subgraphs and a certain graph property, we often allow a finite exceptional set of graphs. But if the symmetric difference of 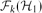 $\mathcal{F}_{k}(\mathcal{H}_{1})$ and
$\mathcal{F}_{k}(\mathcal{H}_{1})$ and 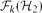 $\mathcal{F}_{k}(\mathcal{H}_{2})$ is finite and we allow a finite number of exceptions, no graph property can distinguish them. Motivated by this observation, we study when we obtain a finite symmetric difference. In this paper, our main aim is the following. If
$\mathcal{F}_{k}(\mathcal{H}_{2})$ is finite and we allow a finite number of exceptions, no graph property can distinguish them. Motivated by this observation, we study when we obtain a finite symmetric difference. In this paper, our main aim is the following. If 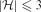 $|\mathcal{H}|\leq 3$ and the symmetric difference of
$|\mathcal{H}|\leq 3$ and the symmetric difference of 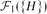 $\mathcal{F}_{1}(\{H\})$ and
$\mathcal{F}_{1}(\{H\})$ and 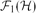 $\mathcal{F}_{1}(\mathcal{H})$ is finite, then either
$\mathcal{F}_{1}(\mathcal{H})$ is finite, then either 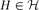 $H\in \mathcal{H}$ or
$H\in \mathcal{H}$ or 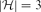 $|\mathcal{H}|=3$ and H=C3. Furthermore, we prove that if the symmetric difference of
$|\mathcal{H}|=3$ and H=C3. Furthermore, we prove that if the symmetric difference of 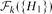 $\mathcal{F}_{k}(\{H_{1}\})$ and
$\mathcal{F}_{k}(\{H_{1}\})$ and 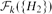 $\mathcal{F}_{k}(\{H_{2}\})$ is finite, then H1=H2.
$\mathcal{F}_{k}(\{H_{2}\})$ is finite, then H1=H2.
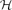
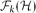
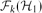
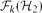
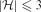
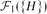
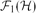
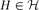
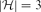
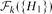
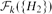
Rainbow Perfect Matchings in Complete Bipartite Graphs: Existence and Counting
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 09 July 2013, pp. 783-799
-
- Article
- Export citation
Excluded Forest Minors and the Erdős–Pósa Property
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 08 July 2013, pp. 700-721
-
- Article
- Export citation

Surveys in Combinatorics 2013
-
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013

Nominal Sets
- Names and Symmetry in Computer Science
-
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013
Non-Deterministic Graph Property Testing
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 5 / September 2013
- Published online by Cambridge University Press:
- 03 July 2013, pp. 749-762
-
- Article
-
- You have access
- Export citation
Analysis of a near-metric TSP approximation algorithm∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 06 August 2013, pp. 293-314
- Print publication:
- July 2013
-
- Article
- Export citation
Minimal 2-dominating sets in trees∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 08 July 2013, pp. 235-240
- Print publication:
- July 2013
-
- Article
- Export citation
Factoring and testing primes in small space∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 241-259
- Print publication:
- July 2013
-
- Article
- Export citation
