Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
5 - Orbit-finiteness
- from PART ONE - THEORY
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp 78-94
-
- Chapter
- Export citation
Preface
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp xi-xiii
-
- Chapter
- Export citation
3 - Freshness
- from PART ONE - THEORY
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp 49-58
-
- Chapter
- Export citation
Dedication
-
- Book:
- Nominal Sets
- Published online:
- 05 July 2013
- Print publication:
- 30 May 2013, pp v-vi
-
- Chapter
- Export citation
The Entropy of Random-Free Graphons and Properties
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 16 May 2013, pp. 517-526
-
- Article
- Export citation
Maximal Empty Boxes Amidst Random Points
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 14 May 2013, pp. 477-498
-
- Article
- Export citation
-
We show that the expected number of maximal empty axis-parallel boxes amidst n random points in the unit hypercube [0,1]d in
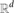 $\mathbb{R}^d$ is (1 ± o(1))
$\mathbb{R}^d$ is (1 ± o(1)) 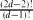 $\frac{(2d-2)!}{(d-1)!}$n lnd−1n, if d is fixed. This estimate is relevant to analysis of the performance of exact algorithms for computing the largest empty axis-parallel box amidst n given points in an axis-parallel box R, especially the algorithms that proceed by examining all maximal empty boxes. Our method for bounding the expected number of maximal empty boxes also shows that the expected number of maximal empty orthants determined by n random points in $\mathbb{R}^d$ is (1 ± o(1)) lnd−1n, if d is fixed. This estimate is related to the expected number of maximal (or minimal) points amidst random points, and has application to algorithms for coloured orthogonal range counting.
$\frac{(2d-2)!}{(d-1)!}$n lnd−1n, if d is fixed. This estimate is relevant to analysis of the performance of exact algorithms for computing the largest empty axis-parallel box amidst n given points in an axis-parallel box R, especially the algorithms that proceed by examining all maximal empty boxes. Our method for bounding the expected number of maximal empty boxes also shows that the expected number of maximal empty orthants determined by n random points in $\mathbb{R}^d$ is (1 ± o(1)) lnd−1n, if d is fixed. This estimate is related to the expected number of maximal (or minimal) points amidst random points, and has application to algorithms for coloured orthogonal range counting.
Cross t-Intersecting Integer Sequences from Weighted Erdős–Ko–Rado
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 09 May 2013, pp. 622-637
-
- Article
- Export citation
-
Let m,n and t be positive integers. Consider [m]n as the set of sequences of length n on an m-letter alphabet. We say that two subsets A⊂[m]n and B⊂[m]n cross t-intersect if any two sequences a∈A and b∈B match in at least t positions. In this case it is shown that if
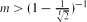 $m > (1-\frac 1{\sqrt[t]2})^{-1}$ then |A||B|≤(mn−t)2. We derive this result from a weighted version of the Erdős–Ko–Rado theorem concerning cross t-intersecting families of subsets, and we also include the corresponding stability statement. One of our main tools is the eigenvalue method for intersection matrices due to Friedgut [10].
$m > (1-\frac 1{\sqrt[t]2})^{-1}$ then |A||B|≤(mn−t)2. We derive this result from a weighted version of the Erdős–Ko–Rado theorem concerning cross t-intersecting families of subsets, and we also include the corresponding stability statement. One of our main tools is the eigenvalue method for intersection matrices due to Friedgut [10].
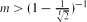

Modern Computer Algebra
-
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013
Sources of quotations
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 725-729
-
- Chapter
- Export citation
16 - Short vectors in lattices
- from III - Gauß
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 473-502
-
- Chapter
- Export citation
23 - Symbolic summation
- from V - Hilbert
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 645-676
-
- Chapter
- Export citation
11 - Fast Euclidean Algorithm
- from II - Newton
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 313-334
-
- Chapter
- Export citation
8 - Fast multiplication
- from II - Newton
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 221-256
-
- Chapter
- Export citation
I - Euclid
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 23-28
-
- Chapter
- Export citation
IV - Fermat
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 511-516
-
- Chapter
- Export citation
V - Hilbert
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 585-590
-
- Chapter
- Export citation
22 - Symbolic integration
- from V - Hilbert
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 623-644
-
- Chapter
- Export citation
18 - Primality testing
- from IV - Fermat
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 517-540
-
- Chapter
- Export citation
1 - Cyclohexane, cryptography, codes, and computer algebra
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 11-22
-
- Chapter
- Export citation
4 - Applications of the Euclidean Algorithm
- from I - Euclid
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 69-96
-
- Chapter
- Export citation
