Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
New applications of the wreath product of forest algebras∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 261-291
- Print publication:
- July 2013
-
- Article
- Export citation
9 - Automatic counting of tilings of skinny plane regions
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 363-378
-
- Chapter
- Export citation
4 - The complexity of change
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 127-160
-
- Chapter
- Export citation
Contents
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp v-vi
-
- Chapter
- Export citation
7 - The world of hereditary graph classes viewed through Truemper configurations
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 265-326
-
- Chapter
- Export citation
3 - Bent functions and their connections to combinatorics
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 91-126
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp i-iv
-
- Chapter
- Export citation
5 - How symmetric can maps on surfaces be?
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 161-238
-
- Chapter
- Export citation
2 - The geometry of covering codes: small complete caps and saturating sets in Galois spaces
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 51-90
-
- Chapter
- Export citation
Preface
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp vii-viii
-
- Chapter
- Export citation
6 - Some open problems on permutation patterns
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 239-264
-
- Chapter
- Export citation
8 - Structure in minor-closed classes of matroids
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 327-362
-
- Chapter
- Export citation
1 - Graph removal lemmas
-
-
- Book:
- Surveys in Combinatorics 2013
- Published online:
- 05 July 2013
- Print publication:
- 27 June 2013, pp 1-50
-
- Chapter
- Export citation
Size Ramsey Number of Bounded Degree Graphs for Games
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. 499-516
-
- Article
- Export citation
-
We study Maker/Breaker games on the edges of sparse graphs. Maker and Breaker take turns at claiming previously unclaimed edges of a given graph H. Maker aims to occupy a given target graph G and Breaker tries to prevent Maker from achieving his goal. We show that for every d there is a constant c = c(d) with the property that for every graph G on n vertices of maximum degree d there is a graph H on at most cn edges such that Maker has a strategy to occupy a copy of G in the game on H.
This is a result about a game-theoretic variant of the size Ramsey number. For a given graph G,
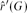 $\hat{r}'(G)$ is defined as the smallest number M for which there exists a graph H with M edges such that Maker has a strategy to occupy a copy of G in the game on H. In this language, our result yields that for every connected graph G of constant maximum degree,
$\hat{r}'(G)$ is defined as the smallest number M for which there exists a graph H with M edges such that Maker has a strategy to occupy a copy of G in the game on H. In this language, our result yields that for every connected graph G of constant maximum degree, 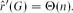 $\hat{r}'(G) = \Theta(n)$.
$\hat{r}'(G) = \Theta(n)$.Moreover, we can also use our method to settle the corresponding extremal number for universal graphs: for a constant d and for the class
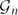 ${\cal G}_{n}$ of n-vertex graphs of maximum degree d,
${\cal G}_{n}$ of n-vertex graphs of maximum degree d, 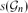 $s({\cal G}_{n})$ denotes the minimum number such that there exists a graph H with M edges where, for everyG ∈ ${\cal G}_{n}$, Maker has a strategy to build a copy of G in the game on H. We obtain that
$s({\cal G}_{n})$ denotes the minimum number such that there exists a graph H with M edges where, for everyG ∈ ${\cal G}_{n}$, Maker has a strategy to build a copy of G in the game on H. We obtain that 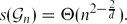 $s({\cal G}_{n}) = \Theta(n^{2 - \frac{2}{d}})$.
$s({\cal G}_{n}) = \Theta(n^{2 - \frac{2}{d}})$.
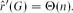
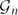
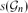
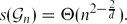
CPC volume 22 issue 4 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. b1-b3
-
- Article
-
- You have access
- Export citation
CPC volume 22 issue 4 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Freiman Homomorphisms of Random Subsets of
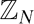 $\mathbb{Z}_{N}$
$\mathbb{Z}_{N}$
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. 592-611
-
- Article
- Export citation
-
Given a set
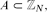 $A\subset\mathbb{Z}_{N}$, we say that a function
$A\subset\mathbb{Z}_{N}$, we say that a function 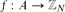 $f\colon A \to \mathbb{Z}_{N}$ is a Freiman homomorphism if f(a)+f(b)=f(c)+f(d) whenever a,b,c,d ∈ A satisfy a+b=c+d. This notion was introduced by Freiman in the 1970s, and plays an important role in the field of additive combinatorics. We say that A is linear if the only Freiman homomorphisms are functions of the form f(x) = ax+b.
$f\colon A \to \mathbb{Z}_{N}$ is a Freiman homomorphism if f(a)+f(b)=f(c)+f(d) whenever a,b,c,d ∈ A satisfy a+b=c+d. This notion was introduced by Freiman in the 1970s, and plays an important role in the field of additive combinatorics. We say that A is linear if the only Freiman homomorphisms are functions of the form f(x) = ax+b.Suppose the elements of A are chosen independently at random, each with probability p. We shall look at the following question: For which values of p=p(N) is A linear with high probability as N → ∞? We show that if p=(2logN − ω(N))1/3N−2/3, where ω(N) → ∞ as N → ∞, then A is not linear with high probability, whereas if p=N−1/2+ε for any ε>0 then A is linear with high probability.
Lipschitz Functions on Expanders are Typically Flat
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. 566-591
-
- Article
- Export citation
Reimer's Inequality on a Finite Distributive Lattice
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 11 June 2013, pp. 612-621
-
- Article
- Export citation

Boolean Models and Methods in Mathematics, Computer Science, and Engineering
-
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010
